
Vinod Grover
@vinodg
Followers
3K
Following
9K
Media
79
Statuses
1K
Sr Distinguished Engineer @nvidia. Compilers, CUDA C++, PL, Machine Learning and Systems. tweets and opinions are personal.
Seattle, WA
Joined March 2008
RT @__tensorcore__: marks the start of a short series of blogposts about CUTLASS 3.x and CuTe that we've been meani….

developer.nvidia.com
In the era of generative AI, utilizing GPUs to their maximum potential is essential to training better models and serving users at scale. Often, these models have layers that cannot be expressed as…
0
50
0
RT @ShashiTharoor: Proud of Thiruvananthapuram girl Divi Bijesh, who won her second world title in under-10 chess this year! Long may she c….

onmanorama.com
Divi Bijesh bagged the U-10 girls title of FIDE World Cadets Cup at Batumi, Georgia.
0
239
0

RT @tqchenml: #MLSys2025 make sure to attend 10:30am keynote @istoica05 An AI stack: from scaling AI workloads to evaluating LLMs. Checkou….
0
15
0
RT @zhyncs42: MLSys 2025 is coming up! Want to meet the developers behind FlashInfer, XGrammar, and SGLang @lmsysorg in person? Join us for….
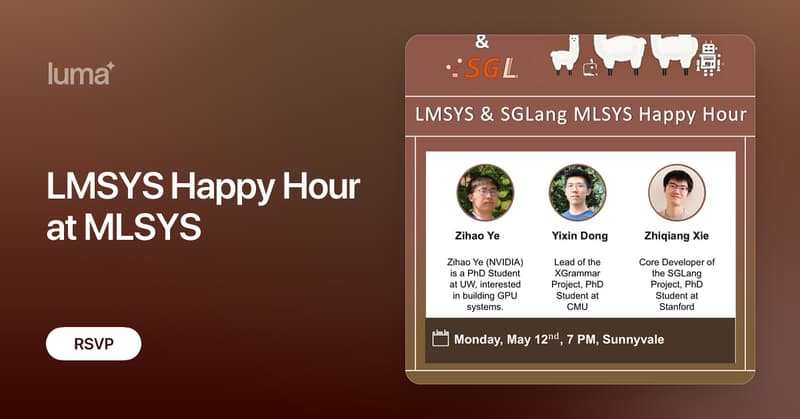
lu.ma
Join top engineers and researchers to explore the latest breakthroughs in AI infrastructure! Hosted by LMSYS Org, SGLang, FlashInfer and XGrammer, this event…
0
9
0
RT @RajeevAlur: Congratulations to Swarat Chaudhuri (PhD, @PennCIS 2007) for this wonderful honor from Guggenheim Foundation .

gf.org
Since 1925, the Guggenheim Foundation has given Fellowships to exceptional artists, writers, scholars, and scientists, empowering them to pursue meaningful work under the freest possible conditions.
0
6
0
RT @tqchenml: Happy to share our latest work at @ASPLOSConf 2025! LLMs are dynamic, both in sequence and batches. Relax brings an ML compil….

arxiv.org
Dynamic shape computations have become critical in modern machine learning workloads, especially in emerging large language models. The success of these models has driven the demand for their...
0
36
0

RT @ye_combinator: Check out the intra-kernel profiler in flashinfer to visualize the timeline of each SM/warpgroup in the lifecycle of a C….
0
31
0
Pipeline Parallelism in JAX!.
Scaling Deep Learning Training with MPMD Pipeline Parallelism. Joint work with @0xA95 @seanprime7 Hanfeng Chen .
0
1
32
RT @__tensorcore__: 🔥🚨 CUTLASS Blackwell is here 🚨🔥. 3.8 release is loaded with support for new features of Blackwell, even an attention ke….
0
32
0
Latest version of flashInfer paper with some cool ideas!.

Are you curious about how to build an efficient and customizable attention engine bebind the scene of major LLM serving frameworks? Checkout the latest arxiv paper on FlashInfer about all the cool ideas from @ye_combinator.
0
2
19
Scaling Deep Learning Training with MPMD Pipeline Parallelism. Joint work with @0xA95 @seanprime7 Hanfeng Chen .
arxiv.org
We present JaxPP, a system for efficiently scaling the training of large deep learning models with flexible pipeline parallelism. We introduce a seamless programming model that allows implementing...
0
5
27