

Wei Shen 沈 伟
@shenwei356
Followers
2K
Following
4K
Media
70
Statuses
2K
Associate professor of Bioinformatics at Chongqing Medical University, China. Lab: https://t.co/67yy7iHTqZ Personal: https://t.co/PgK3FxXeWb https://t.co/mvJTdAyoHz
Chongqing, China
Joined November 2013
LexicMap paper is out!🎉 BTW, we've just released v0.8.0, with reduced indexing and searching memory usage, more features (e.g., limiting search by TaxId), and more utilities to improve the usability. https://t.co/bqbgtAoLFz

github.com
v0.8.0 - 2025-09-10 No changes to the index format (see Index format changelog). New commands: lexicmap utils merge-search-results: Merge a query's search results from multiple indexes. lexic...

Efficient sequence alignment against millions of prokaryotic genomes with LexicMap https://t.co/QBuQ9vZ1iy
3
31
102

The scikit-bio paper in online in Nature Methods! Many thanks to our collaborators, community contributors and reviewers! We couldn’t have done it without you. https://t.co/bvbMdwMtUY
#Bioinformatics #OpenSource
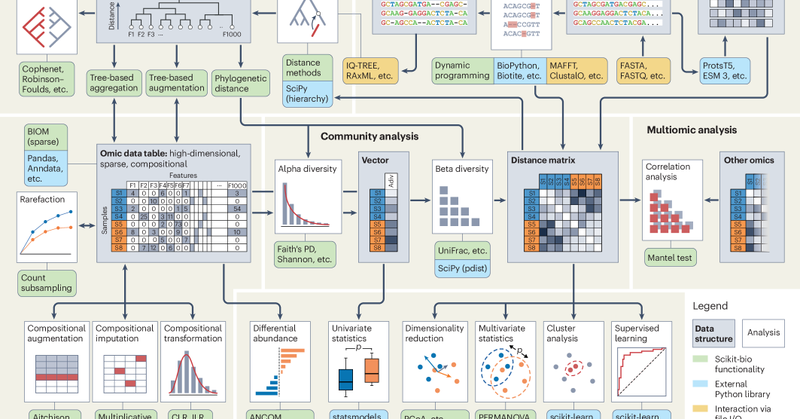
nature.com
Nature Methods - Scikit-bio: a fundamental Python library for biological omic data analysis
4
53
290

It's Monday! ...and a new #MVIF program is out! 🤩 Free registration: https://t.co/h8GhACapmd Highlights: 🇺🇸 Vanessa Hale 🇰🇷 Jun Hyung Cha Keynote: 🇺🇸 Katherine Lemon Talks: 🇺🇸 Meenakshi Chakraborty 🇨🇳 Wei Shen @shenwei356 🇺🇸 Johanna Gutleben @jo_goodlife
0
4
4

This paper highlights some recent security vulnerabilities in sequencers & directly related software (here, with a focus on ONT devices). The intersection of sequencing tech & security seems under-developed! https://t.co/7RHUAfrwWb ONT’s CVE guidelines: https://t.co/nMdGurXCHw

nature.com
Nature Communications - Portable genome sequencers are revolutionizing genomic research. However, their reliance on external systems introduces new vulnerabilities that threaten the security of...
1
2
5

Efficient and accurate search in petabase-scale sequence repositories https://t.co/XDORBMJa8P 🧬🖥️🧪 MetaGraph: https://t.co/5VGSGCB30R Code: https://t.co/R6H4vXE4ti
2
23
77
I sincerely appreciate the opportunity to visit EMBL-EBI. The guidance and support I received from Zamin Iqbal, John Lees and other colleagues have been immensely valuable, leading to a positive transformation in my career path. 😀

There are millions of openly available microbial genomes, but searching them can be slow. Until now 🥁 Introducing LexicMap, a new alignment tool that lets you search these data in minutes, helping track antibiotic resistance, trace outbreaks, and more. https://t.co/UnQCBDst65
0
0
8
There are millions of openly available microbial genomes, but searching them can be slow. Until now 🥁 Introducing LexicMap, a new alignment tool that lets you search these data in minutes, helping track antibiotic resistance, trace outbreaks, and more. https://t.co/UnQCBDst65
0
10
20

🌎👩🔬 For 15+ years biology has accumulated petabytes (million gigabytes) of🧬DNA sequencing data🧬 from the far reaches of our planet.🦠🍄🌵 Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open. https://t.co/dDBtAjfdYL
5
151
380


skani v0.3.0 is released. https://t.co/dEkIzxIbDr * 30-40% potential reduction in memory * Breaking changes to indexing and searching databases Calculate ANI for contigs, genomes. Search vs > 140k genomes: pre-indexed GTDB-R226 available for download.

github.com
Fast, robust ANI and aligned fraction for (metagenomic) genomes and contigs. - bluenote-1577/skani
0
23
54
Yes, I just recommended it to my students.

https://t.co/We4bDz0cRb is shaping up to becoming one of the absolute top resources for learning hands on #bioinformatics and #genomics today!
0
2
11

Slides from my talk (with Kamil Jaron) on an history of k-mers in bioinformatics:
1
31
85
This seems like an awesome course! https://t.co/byOMSDIfCE! If there were more hours in the day, I'd want to put something like this together at UMD.
0
4
12
Also updated - taxid-changelog to May, 2025 https://t.co/9AabacigLF - gtdb-taxdump to GTDB r226 https://t.co/bKrIReUSOG - ictv-taxdump to VMR_MSL40
0
1
0
TaxonKit v0.20.0 is adapted to recent rank changes in NCBI Taxonomy.

github.com
Changes TaxonKit v0.20.0 This version is mainly for maintaining compatibility with NCBI's recent changes(1, 2). Please remove the ranks.txt file in ~/.taxonkit/ or other directories containi...

Updates coming to #NCBITaxonomy! We are introducing two new ranks, domain and realm, and discontinuing the rank superkingdom. Learn more: https://t.co/IqvlgNqjG5
1
14
34
⚡️LexicMap v0.7.0 fixed a minor bug in index building and improved the alignment accuracy! Please rebuild the existing index. Sorry for the inconvenience. 🥹 https://t.co/05zJ4N1UdA

github.com
v0.7.0 - 2025-04-11 Please rebuild the index, as some seeds in the genome end regions were missed during computation. lexicmap index: Fix a little bug in seed desert filling -- forgot to fill the...
1
5
26

A decade ago, we had thousands of bacterial genomes. Now, we have millions. How to scale computational methods? Our paper in @naturemethods answers this: use evolutionary history to guide compression and search. …From terabytes to tens of GBs… w/@Baym @ZaminIqbal et al. 🧵1/
3
53
169
Thrilled that our work on this problem with @KarelBrinda, @ZaminIqbal, and others is out in @naturemethods today! We used phylogenetic compression (described in the thread) to compress every microbe ever sequenced onto a flash drive so that it can be searched with a laptop!

So we asked: what sets the fundamental limit on computation on large genomic databases? Evolution! The irreducible entropy in genome collections is bounded by the most parsimonious path to introduce that variability. In other words, optimal compression should echo phylogeny. 4/
3
29
134