
Mingxing Tan
@tanmingxing
Followers
3K
Following
156
Media
26
Statuses
152
Introducing EMMA: a Gemini based multimodal model for motion planning, perception, and reasoning in autonomous driving! Check out our paper to learn more: Paper: https://t.co/b43IR2AxMi Blog:

waymo.com
At Waymo, we have been at the forefront of AI and ML in autonomous driving for over 15 years, and are continuously contributing to advancing research in the field. Today, we are sharing our latest...

Introducing our latest research paper on EMMA, an End-to-End Multimodal Model for autonomous driving! 🤖This cutting-edge AI research highlights the potential to leverage multimodal world knowledge for autonomous driving. Learn more: https://t.co/HwXOVmKdbG
1
3
25
0
3
7
Polyloss is a general framework, and can naturally subsume cross-entropy loss, focal loss, and other losses. With just one line of code change and one tunable epsilon, it improves EfficientNetV2 (epsilon=2), Mask-RCNN (epsilon=-1), and RSN 3D detection (epsilon=-0.4).
0
0
25
3/N: Our idea is simple: making those coefficients tunable for different models and tasks! Among all coefficients, we find the leading term is the most important one, so our final Poly1 simply tunes the first coefficient by adding one tunable item epsilon * (1 - Pt):
1
0
31
2/N: Where does this magic code come from? Well, it comes from the principle of taylor expansion. If you expand cross-entropy loss, you will find the polynomial coefficients are simply 1/j. These coefficients are fixed for all models and tasks, but are they optimal? No!
1
0
24
Still using cross-entropy loss or focal loss? Now you have a better choice: PolyLoss Our ICLR’22 paper shows: with one line of magic code, Polyloss improves all image classification, detection, and segmentation tasks, sometimes by a large margin. Arixv: https://t.co/jsmX4r7gaD
23
252
1K
Learn how DeepFusion, a fully end-to-end multi-modal 3D detection framework, applies a simple yet effective feature fusion strategy to unify the signals from two sensing modalities and achieve state-of-the-art performance.
research.google
Posted by Yingwei Li, Student Researcher, Google Cloud and Adams Wei Yu, Research Scientist, Google Research, Brain Team LiDAR and visual cameras a...
0
55
212
thread 4/n: DeepFusion is particularly effective for long-range objects, helping autonomous vehicles see further and more clear:
0
0
4
thread 3/n: With such simple modules, we observe a drastic accuracy gain (up to +8.9AP) by DeepFusion:
1
0
5
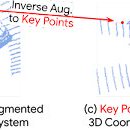
thread 2/n: how to effectively align and combine lidar and camera data? It turns out two key techniques are important: InverseAugment and LearnableAlign (using cross-attention):
1
1
5
Introducing DeepFusion: a new SoTA lidar-camera multimodal model for autonomous driving. Use cross-attention to align and fuse lidar-camera info, and drastically improve accuracy & robustness for 3D detection. Arxiv: https://t.co/8jPc1BWRVf Leaderboard: https://t.co/BMbFMDZcaZ↓
3
18
129
Open-domain dialog—where a model converses about any topic—is a key challenge for language models. Learn about LaMDA, a project to build dialog models that are more safe, grounded, high quality, and in line with our Responsible AI Principles ↓
7
102
360
A more comprehensive blog about efficient models is available here:

research.google
Posted by Mingxing Tan and Zihang Dai, Research Scientists, Google Research As neural network models and training data size grow, training efficien...
0
0
22
Notably, in addition to EffNetV2, we also developed CoAtNet for high data regime (like JFT-3B), by combining convs and transformers: https://t.co/pi5NaBDgRr CoAtNet is worse than EffNetV2 in low data regime and better than EffNetV2 in high data regime:
2
1
25
A more detailed comparison is show below: EffNetV2 is better than ConvNeXt in every aspect of Params, FLOPs, and throughput.
2
2
35
Nice paper with beautiful plots and catchy titles! I was hopping it could compare EffNetV2 (ICML 2021, convs only) as well: https://t.co/YHWEb8pHmR If EffNetV2 is included, the figure should look roughly like this:

A ConvNet for the 2020s abs: https://t.co/SrqEPigdr8 github: https://t.co/Bzg7vYIBxV Constructed entirely from standard ConvNet modules, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation
4
51
293

As in past years, I've spent part of the holiday break summarizing much of the work we've done in @GoogleResearch over the last year. On behalf of @Google's research community, I'm delighted to share this writeup (this year grouped into five themes). https://t.co/aFHshmWXSU
43
269
1K
Wish your neural networks faster and more accurate? Check out our recent EfficientNetV2 and CoAtNet, which significantly speed up the training and inference, while achieving state-of-the-art 90.88% top-1 accuracy on ImageNet.

As #NeuralNetwork models and training data size grow, training efficiency has become more important. Today we present two families of models for image recognition that train faster and achieve state-of-the-art performance. Learn more and grab the code ↓
10
81
259

🆕 The new EfficientNet V2 models are available on #TFHub! They’re a family of image classification models that achieves greater parameter efficiency and faster training speed. Take a look → https://t.co/5PDtQypEkI
2
68
220
Happy to introduce CoAtNet: combining convolution and self-attention in a principled way to obtain better capacity and better generalization. 88.56% top-1 with ImageNet21K (13M imgs), matching ViT-huge with JFT (300M imgs). Paper: https://t.co/AQE33LuzSr
7
109
345