

Nisarg Patel, MD
@nxpatel
Followers
3K
Following
17K
Media
393
Statuses
5K
@UCSF surgeon-scientist. Computational genomics, AI/ML, regulatory policy. Cofounder @memorahealth (acq). Alum @ycombinator w18, @broadinstitute, @harvardmed.
San Francisco, CA
Joined December 2012
My latest in @Health_Affairs on the AI training data challenge health systems shouldn't ignore: Amidst AI labs moving towards model training on chat history with multi-year retention windows, ~2.6% of Claude & 5.7% of ChatGPT conversations contain clinical content, often as PHI

healthaffairs.org
Adopting the proper countermeasures to protect and maintain trust in health care data will require additional collaboration and testing with health care professionals and policy makers.
1
0
3

AI has given venture capital a new way to repeat an old mistake: kingmaking. The pattern from 2021 is back: a category becomes "obvious," a top-tier firm anoints its winner, and everyone else acts like the decision is final. Sierra for support. Harvey for legal. Applied Compute
67
79
1K
Finally, these issues are solvable through collaboration. Privacy-preserving techniques (federated learning, DP-SGD, synthetic data) + healthcare-specific guardrails (BAA-tier access controls, HIPAA audit logs) lead to models that train on clinical text *compliantly*. This
0
0
0
This framework maps HIPAA requirements to ML architecture decisions. For example, "minimum necessary" standard → requires input sanitization layers that extract only task-relevant features before model ingestion. Trust & Safety teams can build this and health system leaders can
1
0
0
A real scenario: clinicians sometimes paste encounter notes into Claude/ChatGPT because they're phenomenal tools (and in certain cases are more appropriate for a given task vs @EvidenceOpen, @Doximity), but consumer tiers lack BAAs, per-record audit trails, or role-based access
1
0
0
The gap is architectural: HIPAA imagines data as discrete, auditable, and erasable. Language models transform data into distributed weights where individual records become difficult (though not impossible) to extract or selectively delete. This mismatch creates regulatory

arxiv.org
Large language models (LLMs) have transformed natural language processing, but their ability to memorize training data poses significant privacy risks. This paper investigates model inversion...
1
0
0
At @UCSFSurgery, @UCSF_DOCIT, I see both sides: AI labs have strong general safety measures (Constitutional AI, privacy filters, differential privacy research), but HIPAA-compliance and protecting PHI isn't a subset of AI safety, it's a distinct requirement space with specific
1
0
0
AWS is down. Government is shut down. Epic is still up.

Amazon $AMZN's AWS is still down. Here are some of the sites affected: Adobe Creative Cloud Airtable Amazon (incl. Alexa & Prime Video) Apple Music Asana AT&T Battlefield (EA) Blink (Security) Boost Mobile Canva ChatGPT Chime Coinbase CollegeBoard Dead By Daylight Delta Air
0
1
1
Love that AI labs are prioritizing biomedical research. Between Skills and MCP, the near-term future of computational biology might not necessarily be *better prediction models* but rather *better integration layers* that let general intelligence operate across the full research

We’re launching our Claude for Life Sciences initiative today, including new bioinformatics Skills, and new MCPs from @benchling, @BioRender, PubMed, @WileyGlobal, @Sagebio, @10xGenomics and more: https://t.co/qONB8arod2
0
0
4
Excited for the imminent health system research/ops work on local 1) post-training (to improve hospital-specific clinical context), 2) benchmarking/uncertainty evaluation (to track population-specific accuracy/drift), and 3) continuous model monitoring and rapid on-prem patching

NEW: OpenAI just released gpt-oss, its first open-weight models since GPT-2. The 120B model nearly matches o3 on HealthBench, beating GPT-4o and o4-mini -- making it OpenAI’s most efficient model yet. Big step toward local, low-cost clinical AI.
2
1
13
Finally, despite the incredible appetite for health AI (see @SofiaGuerraR's excellent breakdown), enterprise health systems and SMB clinics will need to assess their own "AI readiness", i.e., data structure/portability, level of AI expertise, cybersecurity standards (a large
1
1
2
LLMs appear to have significantly better generalizability over prior clinical decision support tools; however, we'll likely need both local (i.e. clinic, health system) and organization-level guidelines (e.g., AMIA) for clinical model governance, auditing, and improvement.
1
0
2
This meant that v2 model validation was done in a bespoke fashion tailored to each health system's level of staff resources/expertise and clinical QI sophistication. Univ of Colorado Health offers a helpful example of how intentional validation steps, including model comparisons
1
0
2
An unanswered question is *where* the best practices for language model implementation will be designed, within model manufacturers (akin to enterprise SaaS deployment teams) or hospital staff? For example, the poor performance and criticism of Epic's initial sepsis prediction
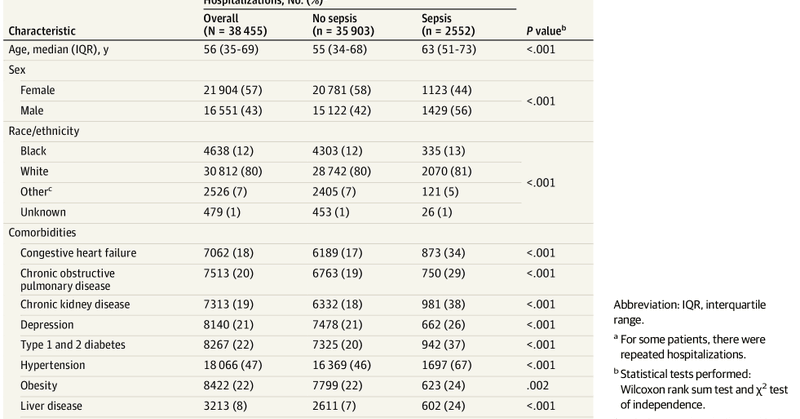
jamanetwork.com
This cohort study externally validates the Epic Sepsis Model in the prediction of sepsis and evaluates its potential clinical impact compared with usual care.
1
1
1
The *standout* point on this work is the excellent focus on effective deployment, user training, and workflow implementation (e.g., minimally intrusive UI), a critical step for real-world studies often overlooked in the prior generation of health AI products (e.g., the remarkably

📣 Excited to share our real-world study of an LLM clinical copilot, a collab between @OpenAI and @PendaHealth. Across 39,849 live patient visits, clinicians with AI had a 16% relative reduction in diagnostic errors and a 13% reduction in treatment errors vs. those without. 🧵
2
1
6
These tools, encompassing molecular, spatial, *and* temporal cell/tissue changes (+ tested on in vitro microphysiological systems) may provide data that foundation models will need to 1) precisely gauge the lethality of suspected tumors and 2) assess urgency for intervention.
0
0
1
In the same way that the @arcinstitute team recently used the transcriptome and perturbation data to represent and abstract shifting single-cell states, I believe the future of cancer diagnostics is in designing tools that, when combined, model cancer cell biology and metastasis.
1
0
1
Tools like mammograms, MRIs, colonoscopies, and pap smears can visualize tumor size/shape, and in the case of the latter two even produce genomic/histopathological data, but early-stage tumors often leave very little identifying characteristics regarding their aggressiveness.
1
0
1
Always enjoy reading @DrSidMukherjee's prose, and while his latest @NewYorker essay is a master class in biostats, it also got me thinking about the value of cancer diagnostics outside the typical bayesian/PPV mental model, that is, as *representations* of human pathophysiology.
1
0
4
Most patients won’t describe their symptoms to neatly fit into a diagnostic schema off the bat, but patient-facing LLMs can ask the right follow-up questions to structure and memorize symptom arcs in a format that helps clinicians *and* computers (i.e. other agents) when needed.
0
0
4