
Michael Hanna
@michaelwhanna
Followers
599
Following
371
Media
27
Statuses
69
PhD student at the University of Amsterdam / ILLC, interested in computational linguistics and (mechanistic) interpretability. Current Anthropic Fellow.
Berkeley, CA
Joined August 2019
RT @GoodfireAI: New research update! We replicated @AnthropicAI's circuit tracing methods to test if they can recover a known, simple trans….
0
53
0
RT @Jack_W_Lindsey: We’re releasing an open-source library and public interactive interface for tracing the internal “thoughts” of a langua….
0
43
0

RT @mlpowered: The methods we used to trace the thoughts of Claude are now open to the public!. Today, we are releasing a library which let….
0
176
0
We’re also excited to see other replications of transcoder circuit-finding work! EleutherAI has been building a library as well, which you can find here:

github.com
Contribute to EleutherAI/attribute development by creating an account on GitHub.
1
0
6
Big thanks as well to @johnnylin and @CurtTigges from @Neuronpedia, for hosting graphs + features and running autointerp on the transcoder features, making circuit-finding even easier! Thanks to @adamrpearce too for the awesome frontend for visualizing circuits!.
1
0
7
Thanks also to @thebasepoint for your help and to fellow Fellow @andyarditi for pre-release testing! Thanks also to @Anthropic and @EthanJPerez for running the Anthropic Fellows Program - it's been a great environment for doing important safety research.
1
0
5
Circuit-tracer uses the attribution method introduced in Anthropic's recent work ( and was built as part of the Anthropic Fellows Program. Thanks to our mentors, @mlpowered and @Jack_W_Lindsey for making this possible!.
transformer-circuits.pub
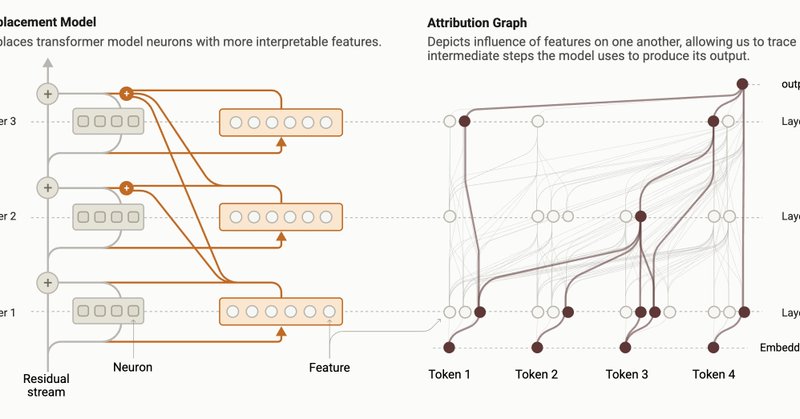
We describe an approach to tracing the “step-by-step” computation involved when a model responds to a single prompt.
1
0
10
For now, circuit-tracer supports Gemma 2 (2B) and Llama 3.2 (1B), and uses single-layer transcoders, but is extensible to other models and transcoder architectures! Try it out on:. - Github: - Colab (click the badge!):
github.com
Contribute to safety-research/circuit-tracer development by creating an account on GitHub.
1
0
9
More whimsical features abound as well: we can find a "pirate" feature in Gemma, and clamp it on to make Gemma tell stories about pirates!

1
0
10
We can also perform interventions to check that our circuits are correct! Don't believe that Gemma uses a "French" feature to produce French results? We can turn it off and make Gemma output English - or turn a "Chinese" feature on, and get Chinese output!

1
0
10
This lets us find circuits that help explain complex model behaviors. For example, we can see that Gemma 2 (2B) solves the same task in multiple languages by using cross-lingual features - and adding language-specific features at the end.

1
0
9
Circuit-tracer then finds the features that are important by computing the exact effect that each feature has on each other feature and on the model's logits. We can then explore the features that are causally relevant, constructing a graph of features - that is, a circuit!

1
0
14
Circuit-tracer works by taking in a model and set of transcoders, which break down its internal activations into interpretable features. We determine the meaning of each feature by looking at the text that makes it activate the strongest - check out the Texas feature below!
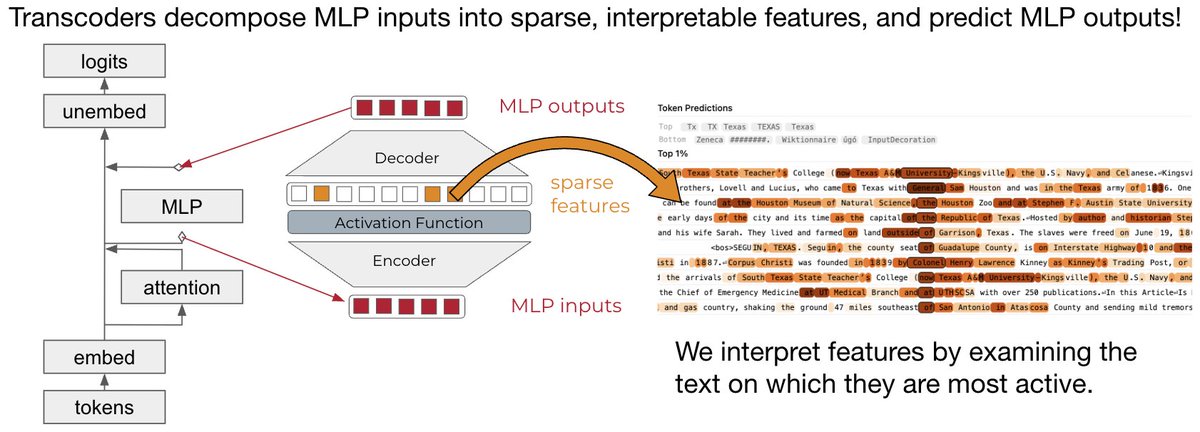
1
0
14
RT @AnthropicAI: Our interpretability team recently released research that traced the thoughts of a large language model. Now we’re open-s….
0
582
0
I'll be presenting this in person at @naaclmeeting, tomorrow at 11am in Ballroom C! Come on by - I'd love to chat with folks about this and all things interp / cog sci!.
Sentences are partially understood before they're fully read. How do LMs incrementally interpret their inputs?. In a new paper @amuuueller and I use mech interp to study how LMs process structurally ambiguous sentences. We show LMs rely on both syntactic & spurious features! 1/10

0
0
37
RT @amuuueller: Lots of progress in mech interp (MI) lately! But how can we measure when new mech interp methods yield real improvements ov….
0
38
0
RT @tal_haklay: 1/13 LLM circuits tell us where the computation happens inside the model—but the computation varies by token position, a ke….
0
44
0
Want to know the whole story? Check out the pre-print here! 10/10.

arxiv.org
Autoregressive transformer language models (LMs) possess strong syntactic abilities, often successfully handling phenomena from agreement to NPI licensing. However, the features they use to...
0
1
6
Unexpectedly, we find that, when answering follow-up questions like "The boy fed the chicken smiled. Did the boy feed the chicken?", LMs don't repair or rely on earlier syntactic features! But they also don't generate new syntactic features. 9/10.
1
0
1
What do LMs do when the ambiguity is resolved? Do they repair their initial representations—which could look like adding on to the circuit we've shown? Or do they reanalyze—for example, by ignoring that circuit and using new syntactic features? 8/10.
1
0
1