

LDJ
@ldjconfirmed
Followers
5,292
Following
197
Media
61
Statuses
319
e/λ Currently: Doing some stuff with AI Prev: @NousResearch @TTSLabsAI DM for business/consulting or interesting conversations.
S4
Joined March 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Davido
• 132437 Tweets
Lionel Messi
• 115045 Tweets
Criston Cole
• 94724 Tweets
Wizkid
• 69177 Tweets
トレード
• 54135 Tweets
#منصور_مع_اجيال_البترول
• 31420 Tweets
#RedVelvet10VEisCosmic
• 24661 Tweets
ひたちなか
• 21558 Tweets
コロナ陽性
• 21315 Tweets
殺害予告
• 20790 Tweets
#Number_i_BON
• 20483 Tweets
ロッキン
• 19195 Tweets
MasaDEPAN LebihMAJU
• 17090 Tweets
Happy New Week
• 16458 Tweets
不買運動
• 16345 Tweets
Jada
• 16163 Tweets
コレクション缶バッジ
• 12908 Tweets
めった刺し
• 10269 Tweets




















Pinned Tweet

Running locally on iphone 13 mini without cellular, without wifi, without bluetooth.
Real-time, not sped-up.
Insightful in-depth response to a question involving 2 relatively obscure and complex topics. (I plan to make it even more effecient soon 😉) ty to WebLLM & MLCChat.
38
44
339

Nice, I can finally easily chat with my documents and papers through native ChatGPT interface (GPT-4)

17
44
542

Therapist: “Biblically accurate transformers aren’t real, they can’t hurt you.”
Biblically accurate transformer:
5
29
230
Looks like somebody on reddit tested a bunch of open source long context models and concluded Capybara-34B is the best for long context over 32K.
Seems to maintain over 93% accuracy until 72K context length (about 100 pages) and still over 65% accuracy until 185K context length.

12
17
139
❄ Apparently this is pretty accurate according to
@altryne
who is currently in Denver right now.

3
13
222
Happy to announce the open sourcing of the Capybara dataset! Merry Christmas everyone!🎄
Thank you to
@yield
/
@niemerg
for sponsoring the creation, as well as
@a16z
for helping make the first trainings possible within
@NousResearch
, and
@JSupa15
for contributions.

7
23
193
I can even add in objects from other images🤔I pushed it a bit to its limits with this really weird skateboard though.

3
10
156
Capybara with the pope jacket, okay I'm having too much fun lmao.



9
13
152
Happy to announce i'm open sourcing my Puffin dataset that I used to train the first third party LLama-2 finetune (Nous-Puffin)
Afaik it currently still holds SOTA score for some reasoning benchmarks like PIQA. All with only 3K examples!
Big thank you to some of my peers over
8
26
153
Finally releasing my 2 new Capybara V1.9 models built on Mistral-7B and StableLM-3B!
Also Obsidian is here - likely the worlds first multi-modal 3B model (built upon Capybara). Can run on iphone!
And special thank you to
@stablequan
as this wouldn't be possible without him!

4
39
146
Nous-Capybara-34B fine-tuned on Yi-34B-200K is out now.
It's showing some impressive scores, apparently
beating all current 70B models in this benchmark that focuses on instructions + multi-lingual abilities.
Lots of ways it can improve and other exciting model releases soon!

@NousResearch
Congratulations on achieving first place in my LLM Comparison/Test where Nous Capybara placed at the top, right next to GPT-4 and a 120B model!
0
4
58
3
23
122
😅Woah, Terence Tao is saying that AI tools are proving invaluable in his workflow... and even mentions using something built on the AI model I collaborated on.😀
( built on the Morph Prover 7B model)
The AI-assisted mathematics breakthroughs are coming!

3
9
110

If anyone is curious, here are some benchmarks for Apples new on-device model and server model, versus other popular models at instruction following and writing abilities.

8
16
109
Just 7K examples from my Capybara dataset with ORPO technique (and no SFT warmup) ended up outperforming models like Zephyr which used more than 100X the data😲. Thank you to
@jiwoohong98
for training this and thank you to
@dvilasuero
for making the preference labels of capybara.

12
7
106
6 months ago I remember joining Nous before even the first Hermes, it was essentially a group chat in a private discord with folks I befriended through shared philosophy amongst us and common goals. Surreal to see now a Nous banner hanging over a grimes set at an AI party in SF!

3
9
94
Puffin now available! Happy to be involved, Special thanks to:
@RedmondAI
for sponsoring the compute.
Has knowledge as recent as early 2023.
Free of censorship, low hallucination rate, insightful concise responses.
Available now for commercial use.

8
20
84
Nous Capybara V1 7B is here!
Seemingly competing with SOTA models in some benches, all while being trained to handle advanced multi-turn conversations.
A culmination of months of distillation insights from techniques introduced by Vicuna, Evol-Instruct, Orca, Lamini and more.

Announcing Nous-Capybara-7B!
The SOTA 7B model by Nous Research. Trained with less than 20K examples, thousands of high quality multi-turn conversations synthesized in the process. Further improvements coming in the near future.
GGUF here:
6
47
192
2
13
81
I plan on keeping a close eye these next couple years on these 9 companies that could significantly impact the future of AI.
Vaire Computing (Reversible compute)
Liquid AI
Symbolica AI
Sakana AI
Kyutai
Holistic (France/No site yet)
Extropic
Normal computing
Rain AI
10
8
78
@BasedBeffJezos
- Led the worlds first llama-2 uncensored chat model (Puffin)
- Co-led the first 3B multi-modal model that can fit on an average phone (Obsidian).
- Dropped LLM datasets that are now used in the training of several popular models such as OpenChat, Dolphin, Starling, CausalLM,
7
7
72
Important contamination warning for those using Pure-Dove or derivative datasets & models!
I personally don't use AI-judged benchmarks like MT-bench, so I don't typically check my datasets for contamination of such. But thanks to
@Fluke_Ellington
at
@MistralAI
, we've
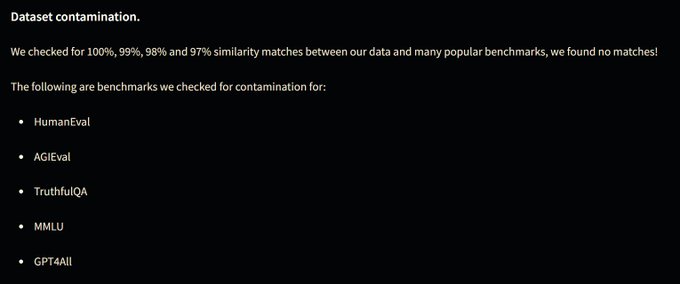
3
10
69
CapybaraHermes is now released thanks to
@dvilasuero
and
@argilla_io
, It outperforms other popular 7B finetunes in most benchmarks tested, this was trained with a new Capybara-DPO dataset that was used to improve on OpenHermes-2.5 with just 7K examples! (more to come) Benchmarks:

4
12
65
If you're doing a lot of fine-tuning and dataset curation, definitely make sure to check out Lilac Garden. They were nice enough to run Capybara through it before official release and allowed me to see interesting insights that normal embedding clustering typically fails to show.


Today we are announcing Lilac Garden, our new cloud service for accelerating AI dataset transforms.
The first service is LLM-powered clustering, enabling a birds eye view of data, 100x faster than running locally.
Read more and sign up for the waitlist:

8
21
127
1
10
64
Zephyr-ORPO-141B is the first model I've seen get this consistently right about what JEPA actually stands for. I tried this even with Claude-3-Opus and it fails too, and even the latest GPT-4-turbo fails! I checked the fine-tune dataset and it has no mention of JEPA either.



5
10
63
Crazy how fast a Macbook laptop can run this model
completely offline. No reliance on a big server needed.
✊

Capybara 34B by
@NousResearch
running on M3 Max 128gb
llama.cpp, 8 bit quantized
10 tok/sec (30 tok/sec for prompt)
video so you can get a feel
activity monitor says 74gb of 128gb is used OS-wide total.
8
20
233
9
6
57
@borisdayma
"Many amazing 7B+ models are available but they are all fine-tune on top of Llama 2 trained by Meta"
Not true, many organizations have released open source pretrained 7B models separate from Llama.
Mistral, Falcon, RedPajama, Pythia, StableLM, MPT... probably more i'm missing.
8
1
54
Puffin-13B benchmarks are in 🔥 Reaches a record SOTA in several GPT4All benchmarks
It's my new favorite model and already some benefits over ChatGPT.
Free of censorship, low hallucination, has knowledge up to 2023 and available for commercial use!!




5
8
54
Thank you
@a16z
for funding my R&D and models at
@NousResearch
as part of your first AI grant cohort!
I’m honored to be part of such a small handful of recipients. Congrats to my peers & friends that are funded too!
@theemozilla
@Teknium1
@jeremyphoward
@TheBlokeAI
@jon_durbin
6
5
54
Really liking all the possibilities to create some interesting art here, some of the most unique stuff i've seen in a while.




3
3
52


"There could be a timeline where OpenAI releases Gobi and it is an AGI, but no one cares because it releases same week as GTA6. That would be a glorious timeline."
- 夜土
6
1
49
I had an amazing time for my first visit to SF (Spent 10 days) I met up with many friends, made some new ones, and had really interesting conversations with a wide range of people that are working on truly interesting things.
Special thank you here to the many folks that I had
6
2
50
@andromeda74356
I plopped in a 100 page pdf and it was able to accurately tell me what was on page 75. Haven't tried a longer pdf than that yet.
1
2
49
Apparently my latest Nous-Capybara model was selected as the new default model for users on the Faraday platform 😄
Definitely check them out if you've ever been interested in running something like character AI, fully offline and locally ran on your own hardware. Full control.

6
11
49
Using image posting + browsing + DallE to generate some cool derivative stuff with Capybara and Pikachu included in some too 😄




0
4
47
🤔 Big?
Btw shout out to
@winglian
for already getting close to having this fine-tunable on Axolotl within 48 hours.
2
3
13
After many delays and convincing from
@Teknium1
, I'm finally releasing Nous-Puffin-70B. It's worth also checking out his Nous-Hermes-70B model!
Thanks to
@pygmalion_ai
for the compute resources!
The benches aren't complete, but may potentially beat ChatGPT in several tests
3
9
42
The date is December 15th 2024.
You're outside while wearing the open source frame glasses. You have hands-free communication with Open interpreter and your multi-modal LLama-3 instance running on your desktop, it's finetuned on the Capybara V2 dataset generated with GPT-4.5

7
1
38
@abacaj
I just checked in MS paint and checked which pixel heights are higher or lower on each side, it's definitely MMLU going slightly down, and HumanEval is exactly the same as before, everything else is increasing at least slightly.
4
0
37
@deepfates
@LIL_QUESTION
Don’t take it personally, he has an automated blocking system that seems pretty experimental and unpredictable. He has even had some of his friends and mutuals accidentally blocked before.
5
0
38
Let’s say hypothetically I had a genie make me an LLM that is supposed to have little to no hallucinations at all (or at least what we colloquially consider to be an “LLM Hallucination”)
What would be some of the best prompts to test it?
31
2
37
Has nobody tried using Claude 3 Opus as an agent yet and seeing how much better than GPT-4 it might be? Maybe in something like AutoGPT? Open Interpreter? ChatDev? AI Town?
13
1
36
Happy New Years to everyone, I made some of my best friends and experiences in 2023 + more to come. We'll see amazing progress in AI and tech in 2024.
Here's the obvious reminder for you to stay healthy both physically and mentally, and keep connected with those around you! ♥
3
2
33
Anyone have a preferred combination of LLM "inference controls" that you use? For example the specific set of values you might prefer to use for temperature, top_k, rep_p etc..
It seems that most agree it could have a significant impact on outputs but isn't talked about enough.
13
3
32
@mayfer
Already an open source decoder-only MoE with 32 experts training on 1T tokens of pre-training from scratch right now, and can fit in a consumer GPU. Should be ready fresh out of the oven in 3-6 weeks.
2
0
31
Exciting to see my Capybara model is currently the top trending model with open weights on Open Router, Only beaten by the proprietary Gemini Pro variants.😀

3
1
31
If you're losing connection with ChatGPT, I recommend trying out some local models through LMStudio, It works completely offline, you can try my latest Nous-Capybara-34B model if you have 24GB of VRAM, or more than 24GB of Unified Ram on a Mac.
The speeds might surprise you!

After a bit of experimentation, Nous-Capybara-34B is the best local model I have ever used
7
4
47
7
3
30
Some folks are putting in meticulous effort towards manually graded, complex multi-turn testing of AI models on questions that aren't online, and even foreign languages too.
I'm glad to see my Capybara V1.9 model shown to be a top record breaker in these most recent tests done!

2
4
29
Congrats to my colleagues
@theemozilla
and Bloc97 at
@NousResearch
that are making 128K context available at SOTA quality! Also would like to thank the University of Geneva and EleutherAI for their contributions. I plan to push the envelope in other directions at Nous very soon!

YaRN: Efficient Context Window Extension of Large Language Models
paper page:
Rotary Position Embeddings (RoPE) have been shown to effectively encode positional information in transformer-based language models. However, these models fail to generalize

5
109
446
0
4
24
Image + Text + Audio has come a massive way this year.
All this happened in 2023:
- Midjourney V5 & V6 released
- GPT-4, Llama & Mixtral MoE released
- Elevenlabs came out of stealth
- Suno & Deepmind released music gen tools
2024 is when this all becomes polished and unified.
2
4
25
Mamba-former MoE model with byte level multi-modal JEPA understanding.
Can do input and output of Images, video, voice, foley, robotic movement data and more.
Runs on a Photonic Neuromorphic Thermodynamic Quantum Hybrid chip.
Sources say it's dropping soon👀
(It's a joke)
2
1
22

@a16z
@yield
@jon_durbin
@knowrohit07
@Teknium1
The entire Capybara dataset will be released in the next few weeks. Right now i'm making the Less-wrong derived portion available, synthesized from using thousands of in-depth posts on LessWrong as context, and expanded into deep nuanced conversations.

1
1
20
@dvilasuero
@argilla_io
Check it out here, just use ChatML format with it:
This wouldn't be possible either if it wasn't for
@Teknium1
OpenHermes-2.5 model being used as the base which has just had it's own dataset released opensource as well!

4
5
18
@VALIPOKKANN
The video is a screen recording from my own iphone. The app is called mlc chat and is already available for people to use some LLM’s on iphone.
3
0
18
It was a pleasure being able to collaborate with Morph Labs on this, I see Morph Prover as just the beginning of how AI can dramatically shift the landscape of even how innovations in mathematics become accelerated!
The downstream implications are virtually endless.
0
0
18
@cyr
Yea it's cool, actually add this custom instruction in my settings to make it sounds more realistic when talking: Speak in a natural casual prose as if you are speaking verbally through audio on not through written text, also please occasionally use uhm and uh when you need to
1
0
13
@jiwoohong98
@dvilasuero
Here is the model if anybody wants to try it out, test it on other benchmarks, or continue training on other data:

0
1
16
Next gen interface for conversational AI is basically FaceTime.
Can take in live video and understand the nuances of your facial expressions, body language and voice, as well as the AI being able to generate video of its own nuanced facial expressions, body language and voice.
7
0
15

@niikhll
@RedmondAI
LM Studio
Highly recommend, everything from downloading the model to inferencing it locally, all can be done within LM Studio itself end-to-end, don't even need to go to HuggingFace website anymore to download the model 🔥
0
1
16
My friend
@nisten
also deserves a special thank you! he quantized the model to Q6 which makes it run even faster.
He also kindly provides instructions on his HF page here about how to run it on your own PC!

1
2
16
This list is of companies either working on fundamentally new hardware compute paradigms, or ones that I believe may work on novel neural network architecture paradigms.
Some notable mentions: Prophetic AI, Cortical Labs, Rysana and software applications incorporated.
2
0
15
@tomchapin
There’s more! The new multi-modal model I collaborated on under Nous Research is efficient enough to do this while running on even a non-pro iphone at practical speeds! Even capable of back and forth conversation about what it sees, called Obsidian-3B, only 2GB of ram needed.

1
0
15
@Fluke_Ellington
@MistralAI
The related models trained on this data would likely be most or all Capybara models, as well as Obsidian, OpenChat-3.5, OpenHermes-2.5, Jackalope and possibly a few more models that don't publicly reference pure-dove yet in their model card.
2
0
14
@BasedBeffJezos
Forgot to mention an important one! It was a pleasure to collaborate on the morph-prover model that is now used by renowned mathematicians like Terrence Tao in theorem searching workflows.
Also worth noting a lot of this wouldn’t be possible without the ecosystem, support and
2
0
12
Thank you to
@a16z
and
@yield
for helping to make this R&D possible.
I'm calling this method Amplify-instruct, it synthesizes new turns and creates in-depth multi-turn conversations from quality single-turn dataset seeds made by
@jon_durbin
@knowrohit07
@Teknium1
and others!
1
0
14
@EduardoSlonski
@ylecun
@DrJimFan
@RichardSSutton
The video data we receive doesn’t seem to increase a humans practical Intelligence much in the written knowledge being testing. We can prove this testing people who have been blind since birth versus those who are sighted. Also humans who can’t hear and those without touch.
2
0
12
Obsidian is a 3B parameter model with vision that is efficient enough to briskly run on even a non-pro iphone, while demonstrating surprisingly accurate understanding of images and holding back and forth conversations!
Link:
Check out the example convo:

3
0
12
@HamelHusain
I can vouch for MLC 💯 even their optimizations for iphone were suprising to me, I posted a video a few days ago of it running locally on iphone and responding well to a fairly difficult prompt.
Running locally on iphone 13 mini without cellular, without wifi, without bluetooth.
Real-time, not sped-up.
Insightful in-depth response to a question involving 2 relatively obscure and complex topics. (I plan to make it even more effecient soon 😉) ty to WebLLM & MLCChat.
38
44
339
0
0
12
@grdntheplanet
@amedhat_
@far__el
Just start reading about the evolution in the past 12 months of:
Meta-Llama, Stanford-Alpaca, Vicuna, WizardLM, Microsoft-Orca, Microsoft Phi-1 and Mistral.
That should just about catch you up on the lore in chronological order, starting with Meta-Llama and ending on Mistral.
0
2
8
@natolambert
“Associative memory, especially in long context tasks”
You might’ve missed it in the papers, but Hyena and Mamba have already been shown to have significantly better associative memory abilities compared to transformers and other architectures, ESPECIALLY in very long contexts.

2
1
11
@amasad
I don't use Linux so I have no idea if this is accurate or not, but here is what our Puffin model generates when I ask the same question verbatim. Interface is using just the recommended pre-prompt and format from the repo:

2
0
11


@stevenmoon
You can find the source data towards the bottom of this link, however I felt it was poorly formatted in the original visualizations, so I re-formatted the same data points into what I feel is a better visualization.

1
0
9
@Fluke_Ellington
@MistralAI
Correction, not entirely sure whether or not it was contained within OpenHermes-2.5 yet, talking with Tek now and might have a conclusive answer for it within the next few days.
2
0
10
@nisten
@teortaxesTex
Doesn't mean it's not Mistral-Medium.
They've never said that Mistral-Medium isn't trained on top of Llama-2-70B, the evidence actually points towards Mistral Medium API using the llama-2-tokenizer instead of the Mistral instruct tokenizer used for Mistral 7B and Mixtral 47B.
1
0
7
Here is the Reddit post on LocalLLaMA:

2
0
8
@ConcavePerspex
@ggerganov
@8th_block
Unified Ram specifically on the M2 Ultra is seriously impressive. It has higher bandwidth than VRAM on RTX 4080 (700GB/s) and only beaten by the RTX 4090 (1TB/s) and higher end workstation cards. For reference, PCI DDR5 ram Bandwidth limit is ~70GB/s which is about 10 times less
1
0
9
@teortaxesTex
@max_paperclips
Haha this is exactly what I was thinking as well, as soon as I saw the paper.

1
0
8
@abacaj
Paid version is much better. I find myself fairly often now googling questions with frustrating results, and then just instinctively going to perplexity and getting exactly what I was looking for. Judging the free version of perplexity I feel like is similar to judging GPT-3.5.
3
0
9
Lastly, I'd like to thank
@a16z
for sponsoring my R&D with these projects under Nous Research and helping to push the envelope with open source space!
There is more to come and I implore anyone to share their chats or feedback with me, which will go to improve the next gen!
0
1
9
@ChadhaArna65411
@nivi
That’s not what it means, photon to photon means that there is a 12ms difference between the moment that a photon enters the camera and the moment the display shows the corresponding light, this is camera processing latency plus 3D processing plus display refresh rate delay.
1
0
9
@jacobavillegas
I believe the whole app requires less than 10GB of free space to download. The entire AI model file you see me using is less than 4GB and fits entirely into ram during usage.
1
0
8
@SolomonWycliffe
@matchaman11
@Yampeleg
There is! You just don't know about it. has a really nice UI and you can easily search up any GGML formatted model that's been uploaded to HF and immediately start running it, all without even having to visit HuggingFace in your browser!

0
1
8
@NousResearch
’s Puffin-70B model is now quantized and uploaded to hugging face as GGUF! (new file format that supersedes GGML) as well as GGML and GPTQ thanks to
@TheBlokeAI
! Again big thank you to
@PygmalionAI
for helping provide compute.

0
1
8

0
0
8
@GMihelac
@yacineMTB
Won't be able to run any of the largest models with a 3090, this has 64GB of 200GB/s bandwidth and can run Mixtral at 20 tokens per second, which is a model that can't fit long context at all on the 24GB of a 3090 at all unless you quantize it to maybe Q2 or offload to cpu ram.
0
0
8
@ManuelFaysse
@MistralAI
7B for 8T would actually be around the perfectly chinchilla optimal amount when it comes to optimizing for best model at a fixed model size with current training procedures. Optimal amount for current models is about 1K tokens per parameter.
0
1
7
@abacaj
@KyleLiang5
They outline a different eval methodology which they believe is better than the current "common practice in ML"

0
1
6
Congrats to my friend
@prateeky2806
and his colleagues!
Memory capacity is one of the biggest drawbacks I see MoE architectures struggling with. (Both training and inference)
This work could be a huge step in alleviating this problem and making MoE an obvious choice for LLMs.

🚀Struggling with Memory issues in MoE models?😭
Introducing...✨MC-SMoE✨
We merge experts THEN compress/decompose merged experts➡️low-rank. Up to 80% mem reduction! 🎉
w/
@pingzli
@KyriectionZhang
@yilin_sung
@YuCheng3
@mohitban47
@TianlongChen4
🧵👇
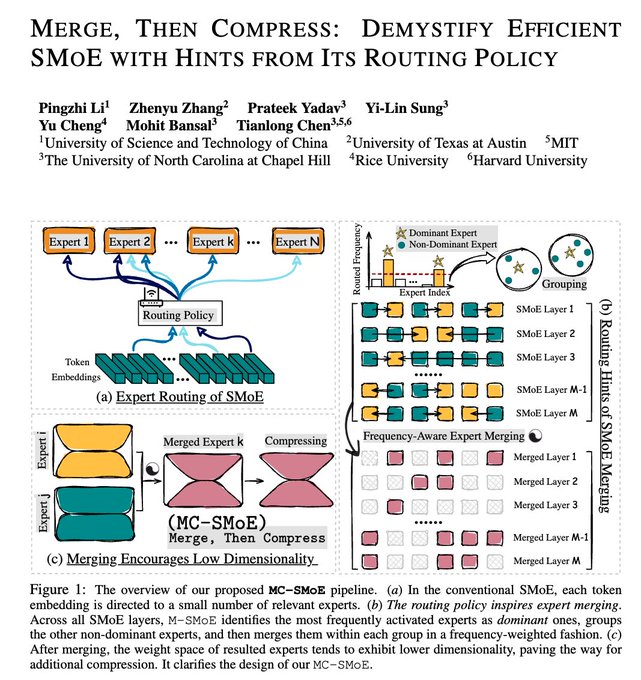
4
74
257
0
0
7
@jon_durbin
@maximelabonne
@Teknium1
@intel
@argilla_io
@fblgit
I really wish that the side of my/your model card page could show which model merges in Huggingface have used our model, just like we can already see which datasets were used to train a model. Maybe
@Thom_Wolf
or
@ClementDelangue
can make this happen.
2
0
7
@altryne
Source of the data is apple.
as usual I take any first-party benchmarks with at least a bit of a grain of salt, but I wouldn't be too surprised that these scores are true.
0
0
7
@gerardsans
They’ve actually been surprisingly transparent about their tech, they even say that the on-device model is ~3B parameters and using mirror descent policy optimization for post-training, along with swappable specialized LoRAs for the model to excel at important tasks at inference.
0
0
6