
Jason Ramapuram
@jramapuram
Followers
1K
Following
2K
Media
44
Statuses
268
ML Research Scientist MLR | Formerly: DeepMind, Qualcomm, Viasat, Rockwell Collins | Swiss-minted PhD in ML | Barista alumnus ☕ @ Starbucks | 🇺🇸🇮🇳🇱🇻🇮🇹
Joined August 2009
Enjoy attention? Want to make it ~18% faster? Try out Sigmoid Attention. We replace the traditional softmax in attention with a sigmoid and a constant (not learned) scalar bias based on the sequence length. Paper: Code: This was


16
163
835
RT @teelinsan: Uncertainty quantification (UQ) is key for safe, reliable LLMs. but are we evaluating it correctly?. 🚨 Our ACL2025 paper f….
0
11
0
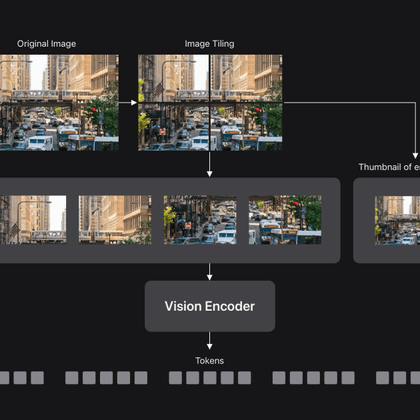
RT @HPouransari: 🌟Explore key insights from the FastVLM project (real-time vision-language model) in this blog post:. .
machinelearning.apple.com
Vision Language Models (VLMs) enable visual understanding alongside textual inputs. They are typically built by passing visual tokens from a…
0
38
0
Data mixing ratios are critical for modern LLM training. This work takes a first principles approach and develops scaling laws for the mixing ratios, enabling “train small” -> “get guarantees at scale”. Definitely worth a read.

We propose new scaling laws that predict the optimal data mixture, for pretraining LLMs, native multimodal models and large vision encoders !. Only running small-scale experiments is needed, and we can then extrapolate to large-scale ones. These laws allow 1/n 🧵

0
2
14
Love Mamba? Take a deep dive into this work from Apple MLR.

Is the mystery behind the performance of Mamba🐍 keeping you awake at night? We got you covered! Our ICML2025 paper demystifies input selectivity in Mamba from the lens of approximation power, long-term memory, and associative recall capacity.

0
0
4
RT @mkirchhof_: Can LLMs access and describe their own internal distributions? With my colleagues at Apple, I invite you to take a leap for….
0
19
0




RT @pals_nlp_wrkshp: Join us at @emnlpmeeting for: . "Tailoring AI: Exploring Active and Passive LLM Personalization" 🎯🧠. To answer, when s….
0
16
0
RT @ruomingpang: At WWDC we introduce a new generation of LLMs developed to enhance the Apple Intelligence features. We also introduce the….

machinelearning.apple.com
With Apple Intelligence, we're integrating powerful generative AI right into the apps and experiences people use every day, all while…
0
110
0
RT @stevenstrogatz: My new #math series in the New York Times, "Math, Revealed," is aimed at everyone, whether you love math or not. Have a….

nytimes.com
In the world of taxicab geometry, even the Pythagorean theorem takes a back seat.
0
147
0
RT @Maureendss: Now that @ISCAInterspeech registration is open, time for some shameless promo!. Sign-up and join our Interspeech tutorial:….
interspeech2025.org
0
5
0
RT @GoogleDeepMind: Video, meet audio. 🎥🤝🔊. With Veo 3, our new state-of-the-art generative video model, you can add soundtracks to clips y….
0
1K
0
RT @reach_vb: Let's goo! Starting today you can access 5000+ LLMs powered by MLX directly from Hugging Face Hub! 🔥. All you need to do is c….
0
20
0
Great push by @FlorisWeers in getting these models out and in a clean easy to use script:
github.com
Contribute to apple/ml-sigmoid-attention development by creating an account on GitHub.
0
0
2
Stop by poster #596 at 10A-1230P tomorrow (Fri 25 April) at #ICLR2025 to hear more about Sigmoid Attention! . We just pushed 8 trajectory checkpoints each for two 7B LLMs for Sigmoid Attention and a 1:1 Softmax Attention (trained with a deterministic dataloader for 1T tokens):. -
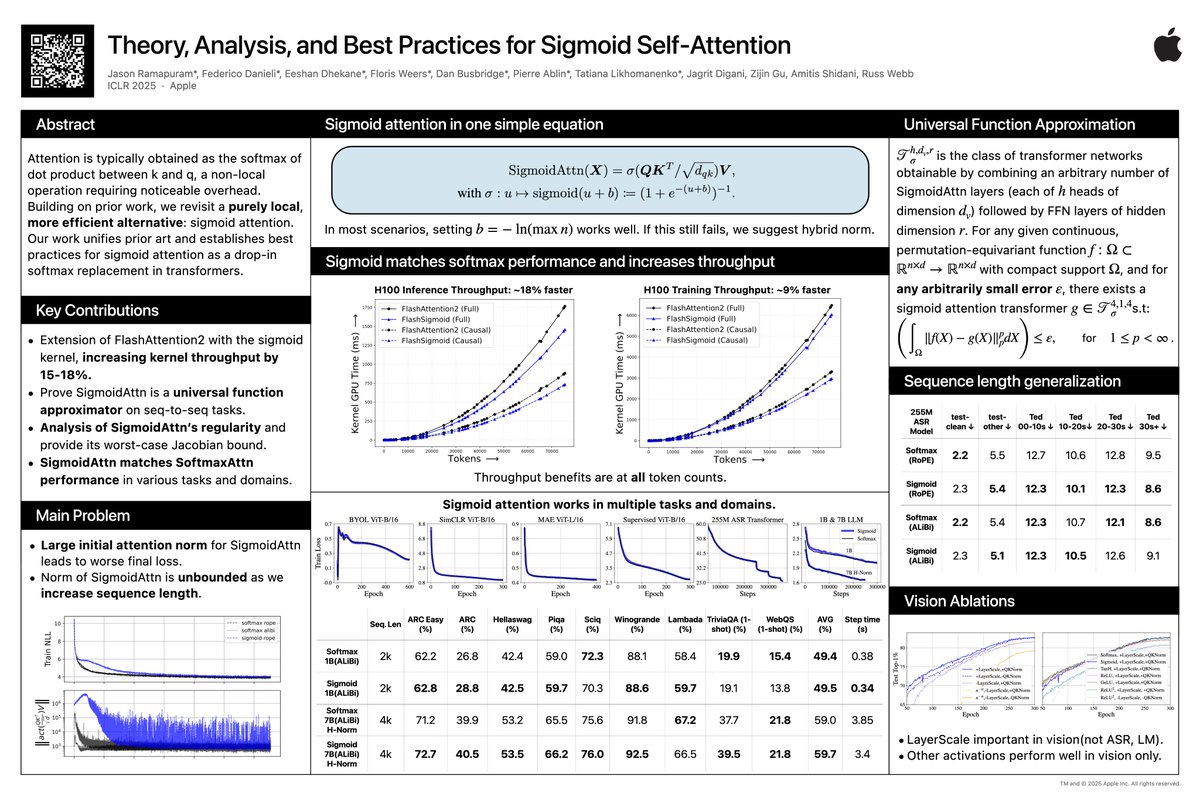
Small update on SigmoidAttn (arXiV incoming). - 1B and 7B LLM results added and stabilized. - Hybrid Norm [on embed dim, not seq dim], `x + norm(sigmoid(QK^T / sqrt(d_{qk}))V)`, stablizes longer sequence (n=4096) and larger models (7B). H-norm used with Grok-1 for example.

1
14
45
RT @MartinKlissarov: Here is an RL perspective on understanding LLMs for decision making. Are LLMs best used as: .policies / rewards / tra….
0
29
0
RT @prlz77: Our work on fine-grained control of LLMs and diffusion models via Activation Transport will be presented @iclr_conf as spotligh….
machinelearning.apple.com
Large generative models are becoming increasingly capable and more widely deployed to power production applications, but getting these…
0
10
0
RT @MustafaShukor1: We release a large scale study to answer the following:.- Is late fusion inherently better than early fusion for multim….
0
77
0