

Pau Rodríguez
@prlz77
Followers
2K
Following
2K
Media
69
Statuses
678
Research Scientist @Apple MLR on #machine_learning understanding and robustness. @ELLISforEurope member. Previously at ServiceNow and Element AI in Montréal.
Barcelona, Spain
Joined June 2012
If you liked our calibration paper and want to work with me & our team, please apply to this PhD internship. 6-months in our Paris office:

Our research team is hiring PhD interns 🍏 Spend your next summer in Paris and explore the next frontiers of LLMs for uncertainty quantification, calibration, RL and post-training, and Bayesian experimental design. Details & Application ➡️
2
18
166
Our research team is hiring PhD interns 🍏 Spend your next summer in Paris and explore the next frontiers of LLMs for uncertainty quantification, calibration, RL and post-training, and Bayesian experimental design. Details & Application ➡️

jobs.apple.com
Apply for a Internship - Machine Learning Research on Uncertainty job at Apple. Read about the role and find out if it’s right for you.
6
59
342
LLMs are notorious for "hallucinating": producing confident-sounding answers that are entirely wrong. But with the right definitions, we can extract a semantic notion of "confidence" from LLMs, and this confidence turns out to be calibrated out-of-the-box in many settings (!)
22
82
586
We rethink how and why LLMs are calibrated: Not just on token-level, but on answer-level 👇

LLMs are notorious for "hallucinating": producing confident-sounding answers that are entirely wrong. But with the right definitions, we can extract a semantic notion of "confidence" from LLMs, and this confidence turns out to be calibrated out-of-the-box in many settings (!)
0
1
20
We have unlocked parallel training of non-linear RNNs! > LSTM entered the chat 🔥

𝗣𝗮𝗿𝗮𝗥𝗡𝗡: 𝗨𝗻𝗹𝗼𝗰𝗸𝗶𝗻𝗴 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗼𝗳 𝗡𝗼𝗻𝗹𝗶𝗻𝗲𝗮𝗿 𝗥𝗡𝗡𝘀 𝗳𝗼𝗿 𝗟𝗟𝗠𝘀 For years, we’ve given RNNs for doomed, and looked at Transformer as 𝘁𝗵𝗲 LLM—but we just needed better math 📄 https://t.co/lFQrUEfEvZ 💻 https://t.co/Lg7gbcwgFU
0
2
13

🔥 Holy shit... Apple just did something nobody saw coming They just dropped Pico-Banana-400K a 400,000-image dataset for text-guided image editing that might redefine multimodal training itself. Here’s the wild part: Unlike most “open” datasets that rely on synthetic
91
421
4K

If you are excited about Multimodal and Agentic Reasoning with Foundation Models, Apple ML Research has openings for Researchers, Engineers, and Interns in this area. Consider applying through the links below or feel free to send a message for more information. - Machine
jobs.apple.com
Apply for a AIML - Machine Learning Researcher, MLR job at Apple. Read about the role and find out if it’s right for you.
12
54
458

📢 Research Internship @Apple Zurich Looking for interns with strong Computer Vision / ML skills to work on Human Modeling, Reconstruction, and Generation. Our work has enabled features like Persona on Vision Pro, Portrait Mode, FaceTime Eye Contact, Animoji & ARKit. 👇
11
39
370

🚀 Come work with me in the Machine Learning Research team at Apple! I’m looking for FT research scientists with a strong track of impactful publications on generative modeling (NeurIPS, ICML, ICLR, CVPR, ICCV, etc.) to join my team and work on fundamental generative modeling
jobs.apple.com
Apply for a AIML - Machine Learning Researcher, MLR job at Apple. Read about the role and find out if it’s right for you.
7
41
345
The best part? LinEAS works on LLMs & T2I models. Huge thanks to the team: Michal Klein, Eleonora Gualdoni, Valentino Maiorca, Arno Blaas, Luca Zappella, Marco Cuturi, & Xavier Suau (who contributed like a 1st author too🥇)! 💻 https://t.co/IdZOpwtFXC 📄 https://t.co/sfPHk5sT2B
0
0
2
LinEAS globally 🌐 optimizes all 1D-Wasserstein distances between source and target activation distributions at multiple layers via backprop ⏩. ✨Bonus: we can now add a sparsity objective. The result? Targeted 🎯 interventions that preserve fluency with strong conditioning!
1
0
2
Existing methods estimate layer-wise 🥞 interventions. While powerful, layer-wise methods have some approximation error since the optimization is done locally, without considering multiple layers at once 🤔. We circumvent this problem in LinEAS with an end-to-end optimization ⚙️!
1
0
1
🦊Activation Steering modifies a model's internal activations to control its output. Think of a slider 🎚️ that gradually adds a concept, like art style 🎨 to the output. This is also a powerful tool for safety, steering models away from harmful content.
1
0
1
🚀 Excited to share LinEAS, our new activation steering method accepted at NeurIPS 2025! It approximates optimal transport maps e2e to precisely guide 🧭 activations achieving finer control 🎚️ with ✨ less than 32 ✨ prompts! 💻 https://t.co/IdZOpwtFXC 📄 https://t.co/sfPHk5sT2B
1
15
52

🕳️🐇Into the Rabbit Hull – Part II Continuing our interpretation of DINOv2, the second part of our study concerns the geometry of concepts and the synthesis of our findings toward a new representational phenomenology: the Minkowski Representation Hypothesis
5
69
381

📣 Internship at Apple ML Research We’re looking for a PhD research intern with interests in efficient multimodal models and video. For our recent works see https://t.co/gOZIopzufv This is a pure-research internship where the objective is to publish high-quality work. Internship
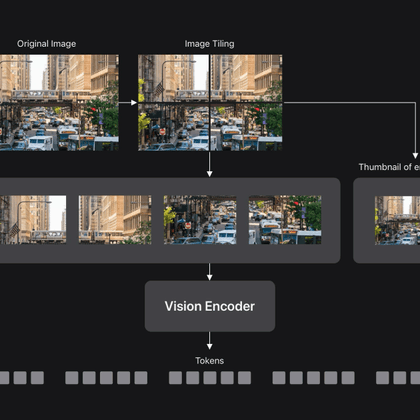
machinelearning.apple.com
Vision Language Models (VLMs) enable visual understanding alongside textual inputs. They are typically built by passing visual tokens from a…
3
30
298

📣We have PhD research internship positions available at Apple MLR. DM me your brief research background, resume, and availability (earliest start date and latest end date) if interested in the topics below.

Introducing Pretraining with Hierarchical Memories: Separating Knowledge & Reasoning for On-Device LLM Deployment 💡We propose dividing LLM parameters into 1) anchor (always used, capturing commonsense) and 2) memory bank (selected per query, capturing world knowledge). [1/X]🧵
8
49
461

New APPLE paper says a small base model plus fetched memories can act like a bigger one. With about 10% extra fetched parameters, a 160M model matches models over 2x its size. Packing all facts into fixed weights wastes memory and compute because each query needs very little.
29
121
1K

Super excited to share l3m 🚀, a library for training large multimodal models, which we used to build AIM and AIMv2. Massive thanks to @alaa_nouby @DonkeyShot21 Michal Klein @MustafaShukor1 @jmsusskind and many others.
1
16
55