

Jakub Smékal
@jakub_smekal
Followers
954
Following
675
Media
31
Statuses
251
AI, physics, and neuroscience. PhD student @Stanford
California
Joined July 2016

We also just dropped a new blog that steps through both the the math and the code! Blog: https://t.co/Ud2tHD9lVL Poster: https://t.co/doxlOH2pZv With my amazing collaborators @awarr9 , @jimmysmith1919 , and @scott_linderman
0
3
37
I'm excited to share our #NeurIPS2024 paper, "Modeling Latent Neural Dynamics with Gaussian Process Switching Linear Dynamical Systems" 🧠✨ We introduce the gpSLDS, a new model for interpretable analysis of latent neural dynamics! 🧵 1/10
2
17
137

So excited by our latest @NeurIPSConf paper on parallelizing nonlinear RNNs! With my amazing collaborators @awarr9, @jimmysmith1919, and @scott_linderman. We are building on the beautiful DEER algorithm by YH Lim, @mfkasim, et al. ( https://t.co/HomnNayAt3). Thread below!

arxiv.org
Sequential models, such as Recurrent Neural Networks and Neural Ordinary Differential Equations, have long suffered from slow training due to their inherent sequential nature. For many years this...

Did you know that you can parallelize *nonlinear* RNNs over their sequence length!? Our @NeurIPSConf paper "Towards Scalable and Stable Parallelization of nonlinear RNNs," which introduces quasi-DEER and ELK to parallelize ever larger and richer dynamical systems! 🧵 [1/11]

1
5
21

Badly kept secret, but very excited to announce our $6M funding round to push forward our vision for a Web of trillions of cooperating AI agents 🥳 It's been a long journey to this point. I realized the importance of a new, more decentralized approach to AI over 3 years ago and

This is the new direction of Agentic AI frameworks 🤖 Agnostic... clever. https://t.co/x5cqDOBkj5
34
17
176

Excited to share a new project! 🎉🎉 https://t.co/A36dZL55ar How do we navigate between brain states when we switch tasks? Are dynamics driven by control, or passive decay of the prev task? To answer, we compare high-dim linear dynamical systems fit to EEG and RNNs🌀 ⏬
7
108
519

Since we started our LLM efforts this year a major goal of mine has been to surpass the heavyweights of the 7B range, and today we achieved just that Zamba2 series models offer SOTA performance and unparalleled inference efficiency. Zyphra now has the best LLMs in the ≤8B range

Today, in collaboration with @NvidiaAI, we bring you Zamba2-7B – a hybrid-SSM model that outperforms Mistral, Gemma, Llama3 & other leading models in both quality and speed. Zamba2-7B is the leading model for ≤8B weight class. 👇See more in the thread below👇
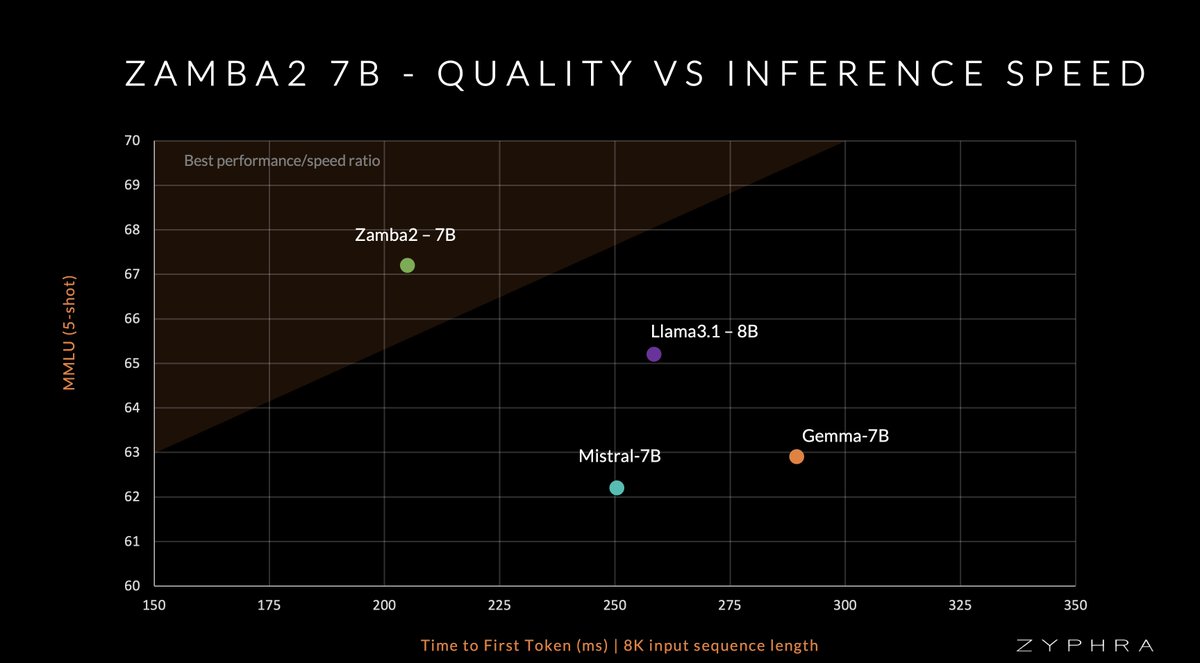
3
5
122

BREAKING NEWS The Royal Swedish Academy of Sciences has decided to award the 2024 #NobelPrize in Physics to John J. Hopfield and Geoffrey E. Hinton “for foundational discoveries and inventions that enable machine learning with artificial neural networks.”

1K
13K
33K

Our new NeurIPS spotlight: https://t.co/0GcC4xz57K Get rich quick: new exact solutions to learning dynamics reveal how unbalanced initializations promote rapid feature learning. See thread ->

arxiv.org
While the impressive performance of modern neural networks is often attributed to their capacity to efficiently extract task-relevant features from data, the mechanisms underlying this rich...

🌟Announcing NeurIPS spotlight paper on the transition from lazy to rich🔦 We reveal through exact gradient flow dynamics how unbalanced initializations promote rapid feature learning co-led @AllanRaventos and @ClementineDomi6 @FCHEN_AI @klindt_david @SaxeLab @SuryaGanguli
2
23
187

"The structure of data is the dark matter of theory in deep learning" — @SuryaGanguli during his talk on "Perspectives from Physics, Neuroscience, and Theory" at the Simons Institute's Special Year on Large Language Models and Transformers, Part 1 Boot Camp.

0
25
141

@jimmysmith1919 @MichaelKleinman @dan_biderman @scott_linderman @SaxeLab We're excited about the future prospects of this type of analysis for deep nonlinear SSMs in showing both how best to parameterize these models for different tasks as well as understand their limitations.
0
0
5
@jimmysmith1919 @MichaelKleinman @dan_biderman @scott_linderman @SaxeLab There's been much interest in the recent deep SSM literature in the role of latent state size in memory capacity, expressivity, and model performance. In our simplified setting, we show analytically and empirically that larger state sizes can also improve the rate of convergence.

1
0
5
@jimmysmith1919 @MichaelKleinman @dan_biderman @scott_linderman @SaxeLab Analyzing the setting of one-layer SSMs in the frequency domain, we recover analytical solutions describing the evolution of the SSM's learnable parameters as a function of data-dependent sufficient statistics, latent state size, and initialization, under simplifying assumptions.
1
0
5
@jimmysmith1919 @MichaelKleinman @dan_biderman @scott_linderman Inspired by work analyzing the dynamics of learning as a function of data and model parameterization in deep linear feedforward neural networks (@SaxeLab et al. https://t.co/w9tMez5RHY), we study the learning dynamics of linear SSMs.
arxiv.org
Despite the widespread practical success of deep learning methods, our theoretical understanding of the dynamics of learning in deep neural networks remains quite sparse. We attempt to bridge the...
1
0
6
@jimmysmith1919 @MichaelKleinman @dan_biderman @scott_linderman Deep state space models (S4, S5, S6/Mamba, and many more!) are an exciting class of architectures for sequence modeling tasks, both for language and otherwise, but we don't really understand them well enough on a theory level.
1
0
5
Excited to share the first paper of my PhD: Towards a theory of learning dynamics in deep state space models https://t.co/OMX0yTDlJw with @jimmysmith1919, @MichaelKleinman, @dan_biderman, and @scott_linderman. Accepted as a Spotlight talk at the NGSM workshop at ICML 2024!
arxiv.org
State space models (SSMs) have shown remarkable empirical performance on many long sequence modeling tasks, but a theoretical understanding of these models is still lacking. In this work, we study...
5
21
158
Great post on Mamba and state space models:
newsletter.maartengrootendorst.com
An Alternative to Transformers for Language Modeling
0
0
2


"You can't have infinite growth on a planet with finite resources!" After all, why shouldn't we try to solve nuclear fusion, print atoms and molecules, build Dyson spheres, mine other planets, and travel to other solar systems and galaxies

2
5
26
it's likely going to become too risky to keep a fixed time-window for "education" and "the rest of life", simply because the environment you optimize for is going to change too quickly
0
0
3