

Zyphra
@ZyphraAI
Followers
7K
Following
257
Media
36
Statuses
117
Palo Alto, CA
Joined March 2021
Today, we're excited to announce a beta release of Zonos, a highly expressive TTS model with high fidelity voice cloning. We release both transformer and SSM-hybrid models under an Apache 2.0 license. Zonos performs well vs leading TTS providers in quality and expressiveness.
138
442
3K
Zyphra is expanding! Join our growing team in Palo Alto. We have multiple roles open across multimodal foundation models, RL, product, and infrastructure. Check them out here:

jobs.ashbyhq.com
Zyphra Jobs
3
5
21

Another mature reasoning RL stack from perhaps the highest-taste Western open source AI company
Training Recipe: We train using the PRIME framework and use iterative context lengthening to encourage efficient reasoning traces. Even with responses truncated to 2048 tokens, ZR1-1.5B still outperforms Qwen2.5-Math-7B-Instruct!

3
11
153
Use the model in our Playground by going to 'Zyphra Chat' and selecting ZR1-1.5B: https://t.co/MOxeT5pokY Read our blog: https://t.co/WTZ3yDVjwJ Download the model on HuggingFace: https://t.co/Wgp9mBECvA

1
3
35
Training Recipe: We train using the PRIME framework and use iterative context lengthening to encourage efficient reasoning traces. Even with responses truncated to 2048 tokens, ZR1-1.5B still outperforms Qwen2.5-Math-7B-Instruct!
2
4
74
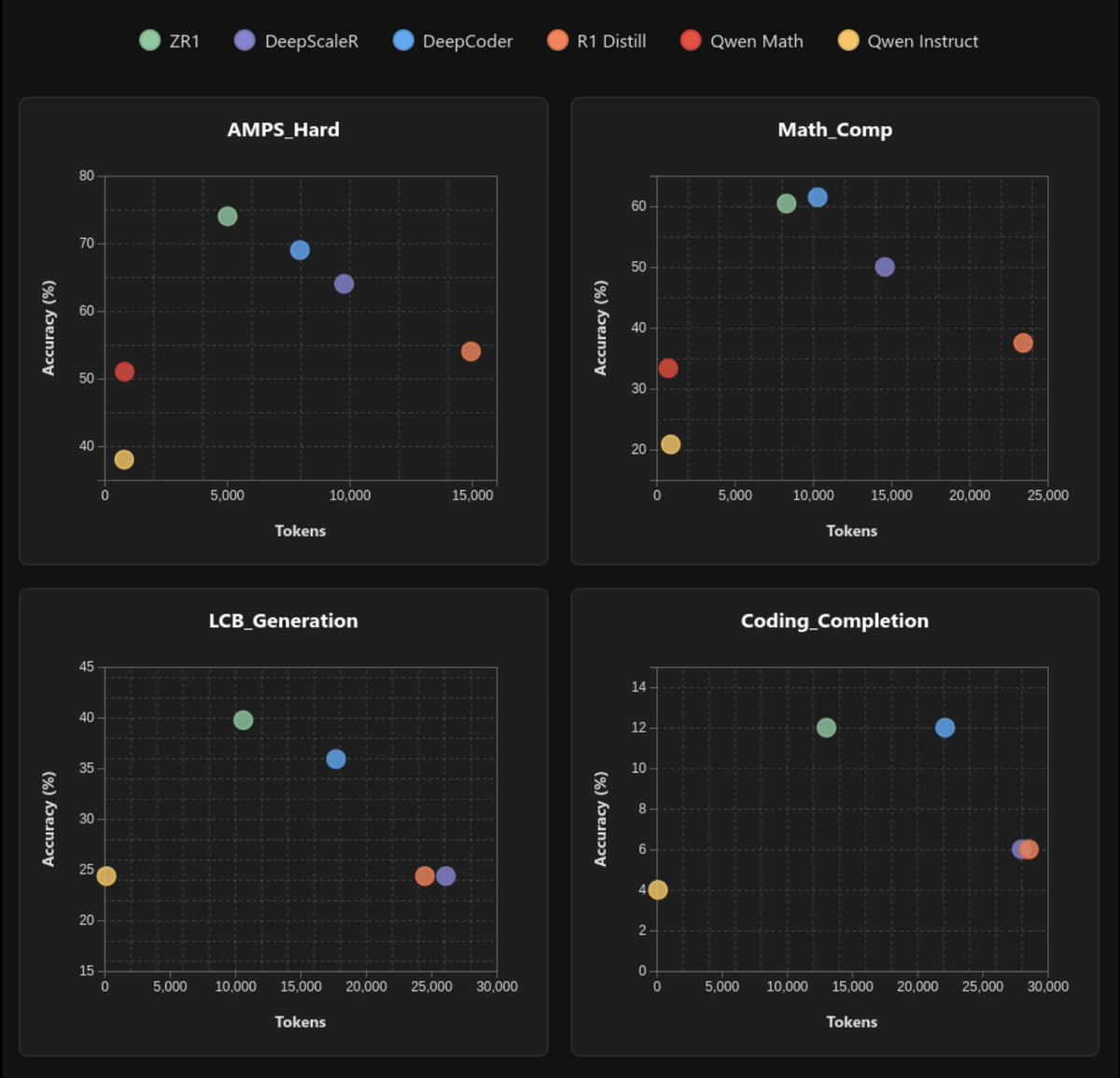
On math benchmarks, we find that ZR1-1.5B performs close to the SoTA DeepScaleR-1.5B despite having more general coding abilities and using less reasoning tokens. On many competition math tasks, ZR1-1.5B performs about the level of Qwen2.5-72B-math-instruct. 👇How'd we do it?👇

2
2
31
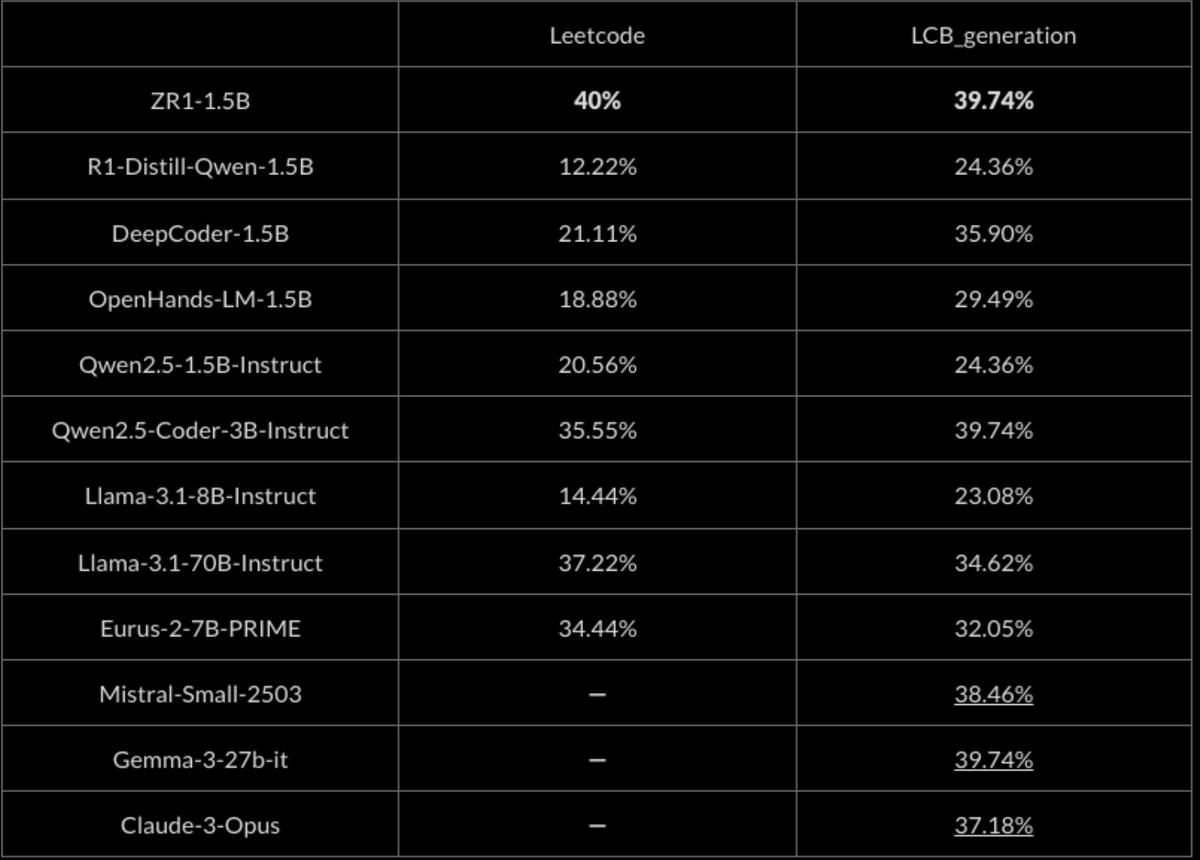
On hard coding evaluations, ZR1-1.5B achieves rough parity with Claude3-Opus and Gemma2-27B-instruct and improves over the base R1-Distill-1.5B model by over 50%. ZR1-1.5B is SoTA on coding evaluations for its size, greatly outperforming code reasoning models such as OpenHands.
2
2
50
Zyphra is releasing our first reasoning model, ZR1-1.5B. This small but powerful reasoning model excels at both math and code, making it one of the best models in these categories for its size. It also uses 60% less reasoning tokens than comparable models. 🆓Apache 2.0 license.
15
64
501
Today we’re releasing a highly requested feature in our Playground — Multi Voice. Powered by Zonos, it lets you assign different voices to different parts of text, generating one seamless audio clip. Bring expressive Voice AI to all of your content or just have some fun.
1
8
26
本日、Zyphra は Zonos-v0.1-hybrid を搭載した日本語の Zonos を発表できることを嬉しく思います。 このモデルは英語に加え、表現力豊かな日本語にも優れています。 モデル���試し、高度に最適化された API https://t.co/wO6LZA6Wqp を使用して構築します さらに多くの言語が間もなく登場します.
0
3
15
Today Zyphra is excited to announce Zonos in Japanese, powered by Zonos-v0.1-hybrid. In addition to English, this model excels at very expressive Japanese. Play with the model and build with our highly optimized API https://t.co/wO6LZA6Wqp Many more languages are coming soon.
12
46
208

@ZyphraAI have launched their first Text to Speech model, Zonos-v0.1 - now the leading open weights Text to Speech model in Artificial Analysis Speech Arena. Zonos-v0.1 is currently scoring a Speech Arena ELO of 1020, just behind proprietary speech models available on Google

3
10
43
We apologize if you’ve been experiencing performance issues on our Playground/API over the past 24 hours. Since yesterday’s release, we’ve seen higher than expected activity, but we’re working diligently to troubleshoot. Thanks to everyone who has tried Zonos!
14
1
64

The simulation is sounding ever smarter... from the DeepSeek of the free world: @ZyphraAI
https://t.co/2ZXuze2Jpc
11
30
183
Currently Zonos is a beta preview. While highly expressive, Zonos is sometimes unreliable in generations leading to interesting bloopers. We are excited to continue pushing the frontiers of conversational agent performance, reliability, and efficiency over the coming months.
2
2
69
Zonos offers flexible control of vocal speed, emotion, tone, and audio quality as well as instant unlimited high quality voice cloning. Zonos natively generates speech at 44Khz. Our hybrid is the first open-source SSM hybrid audio model. Tech report to be released soon.
2
3
86
Try the model in our playground and build with our model API: https://t.co/wO6LZA6Wqp Read our blog post: https://t.co/TUsbDcnBkV Get the weights on Huggingface: https://t.co/3CTerovrZX and https://t.co/8WCmsm2sRG Download the inference code:
7
36
258

@johannes_hage deepseek of the west, and it's no surprise that millidge is there
0
1
17