

Manu Gaur
@gaur_manu
Followers
323
Following
19K
Media
106
Statuses
2K
used to do physics, now multiplying matrices @IIIT_Hyderabad | Incoming @CMU_Robotics
New Delhi, India
Joined May 2012
Can RL fine-tuning endow MLLMs with fine-grained visual understanding?. Using our training recipe, we outperform SOTA open-source MLLMs on fine-grained visual discrimination with ClipCap, a mere 200M param simplification of modern MLLMs!!!. 🚨Introducing No Detail Left Behind:

4
30
128
Everyone asks who is adam but not how is adam 😢.


1
0
4
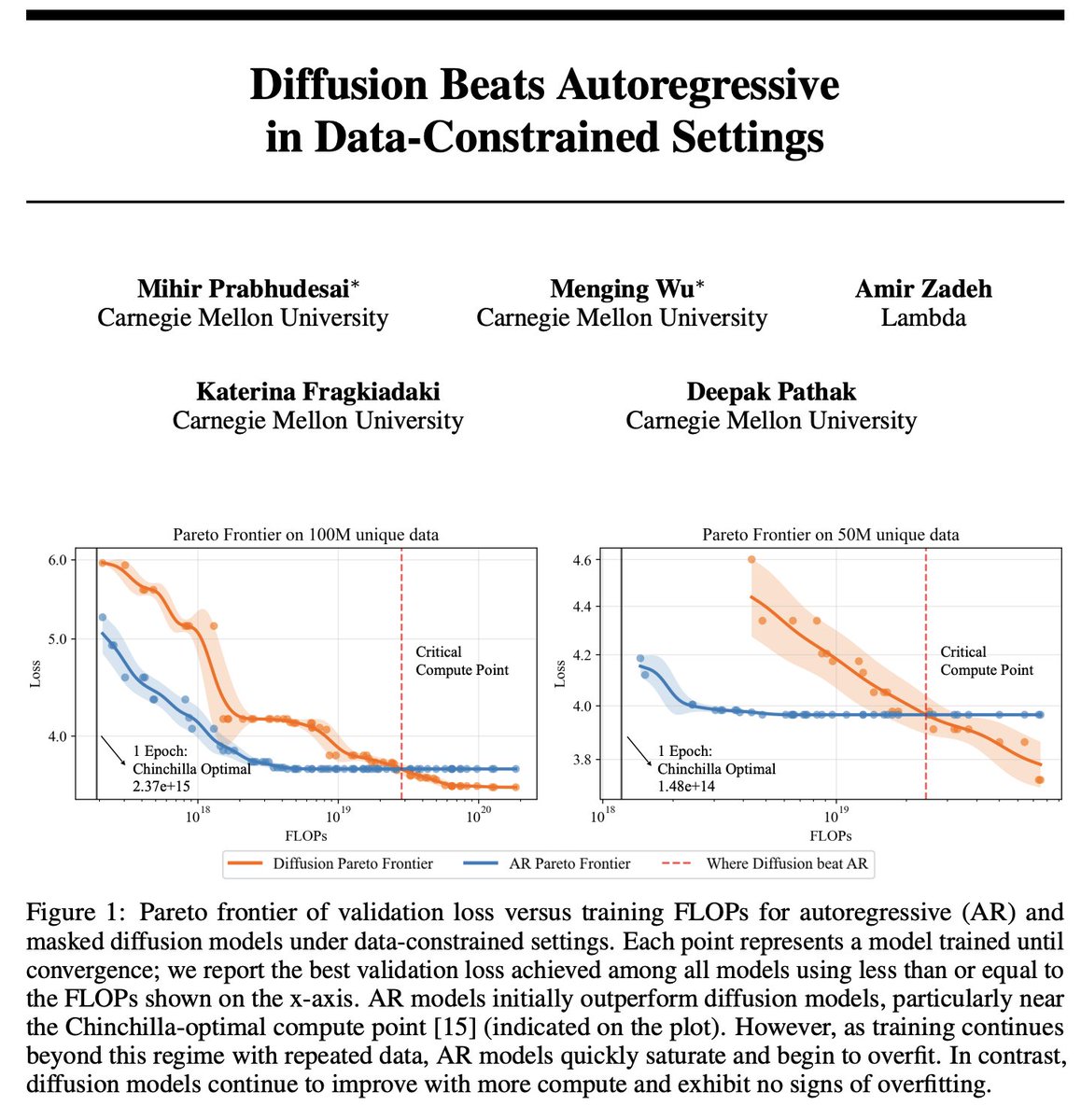
Great research work. The thread is a gold mine for anyone interested in understanding diffusion language modelling and how it fares with AR models!.

🚨 The era of infinite internet data is ending, So we ask:. 👉 What’s the right generative modelling objective when data—not compute—is the bottleneck?. TL;DR:. ▶️Compute-constrained? Train Autoregressive models. ▶️Data-constrained? Train Diffusion models. Get ready for 🤿 1/n
0
1
7
Yup. the linear layer can reconstruct using the residual stream as long as the image is scaled. It works even if you initialize siglip with random weights :


Nothing special here: this is always case for randomly initialized clip due to pre-norm nature. For siglip, your size of residual stream is proportional to magnitude of initial emb, but its not the case for activations on MLP / attention due to normalizations.(Say z <- z +

0
0
4
Moving beyond MCQ to tasks that evaluate free-form generation is crucial to develop systems that better understand instructions and leverage EXISTING knowledge more effectively. From my work - gemini knows the prominent point of difference (aces VQA), but fails to independently

MCQ is great for checking existence of specific knowledge i.e if model fails to answer, it definitely lacks it. However, providing the answer along with the task prompt biases model's output towards the very concept that is being evaluated. This raises questions about whether the.
0
0
4
"On MMMU Pro , a visual question-answering benchmark with 10 choices, we obtain 51% shortcut-accuracy without showing the image or the question". Cambrian did show language shortcuts made by MLLMs on popular VQA datasets, but shortcuts using just the multiple choices is insane!


There's been a hole at the heart of #LLM evals, and we can now fix it. 📜New paper: Answer Matching Outperforms Multiple Choice for Language Model Evaluations. ❗️We found MCQs can be solved without even knowing the question. Looking at just the choices helps guess the answer

1
3
13
MCQ is great for checking existence of specific knowledge i.e if model fails to answer, it definitely lacks it. However, providing the answer along with the task prompt biases model's output towards the very concept that is being evaluated. This raises questions about whether the.
There's been a hole at the heart of #LLM evals, and we can now fix it. 📜New paper: Answer Matching Outperforms Multiple Choice for Language Model Evaluations. ❗️We found MCQs can be solved without even knowing the question. Looking at just the choices helps guess the answer
0
3
7
feeling dumb that I never thought of it this way. makes total sense, a linear classifier learns the "ideal" vector W_j for each class. with CLIP, we can simply replace the learnt W_j with text embeddings - so the text encoder effectively is a hypernetwork.

1
0
7

the fomo is very real for those outside the frontier labs. Curiosity driven research remains a healthy escape (for me at least)— feynman style, detached from the outcomes and pursued solely for the love of the game. Whether or not I succeed, I’d certainly enjoy the ride.

@SuvanshSanjeev lol thanks for saying that! I think we’re both coming from the same place-wanting to encourage others. I’ve seen a lot of phd students feeling anxious, struggling with fomo and wondering if they’re making a huge life mistake. but I really believe we can create a culture where.
2
0
4
This is who runs this account



0
0
3
lance armstrong's favourite policy gradient method!.

(1/n) Since its publication in 2017, PPO has essentially become synonymous with RL. Today, we are excited to provide you with a better alternative - EPO.
0
0
1
“there was no importance to what I was doing, but ultimately there was” :)


He was at Cornell I think and burned out and he started working on the physics of the plates wobbling on those cafeteria things that stack the plates. Completely pointless. Just fun easy physics for him and it unstuck him.
1
2
4
you can take a man out of physics, but you can't take the physics out of the man 😉.great talk by kaiming!

0
0
1

"there are cathedrals everywhere for those with the eyes to see".


0
0
2
what pytorch hell am I in. adding print statements to the forward() doubles my training speed 😭😭 (31 iters/s jumps to 73)



6
1
58
really neat (also cheap) solution to an important problem!.

We can then mimic the effect of learned register tokens by just shifting the activations arising from the register neurons to a dummy token during the forward pass.

0
0
1
really cool work. post-training image generators with VLMs seems to be an obvious way of enforcing multimodal control. however its expensive, instead you can simply use the gradient of the reward model to update the generator at test time. also highly efficient as you don’t need.

✨New preprint: Dual-Process Image Generation! We distill *feedback from a VLM* into *feed-forward image generation*, at inference time. The result is flexible control: parameterize tasks as multimodal inputs, visually inspect the images with the VLM, and update the generator.🧵
0
0
2
a good prior goes a long way for controllable generations. Cool work by @zeeshank95!.

Can text-to-image Diffusion models handle surreal compositions beyond their training distribution?. 🚨 Introducing ComposeAnything — Composite object priors for diffusion models .📸 More faithful, controllable generations — no retraining required. 🔗1/9

0
0
0
important read >> huge gains or measurement errors??.
Confused about recent LLM RL results where models improve without any ground-truth signal? We were too. Until we looked at the reported numbers of the Pre-RL models and realized they were serverely underreported across papers. We compiled discrepancies in a blog below🧵👇

0
0
5