
Quentin Garrido
@garridoq_
Followers
1K
Following
1K
Media
24
Statuses
278
Research Scientist, FAIR at Meta. PhD from @MetaAI and Université Gustave Eiffel with Yann LeCun and Laurent Najman. Ex MVA and @ESIEEPARIS
Joined April 2021
The last paper of my PhD is finally out ! Introducing "Intuitive physics understanding emerges from self-supervised pretraining on natural videos" We show that without any prior, V-JEPA --a self-supervised video model-- develops an understanding of intuitive physics !
19
166
898
Great work ! While biased, I'm particularly a fan of the integration of "surprise" in the model. We've seen in the past how it can be used alone for intuitive physics understanding ( https://t.co/YmBFzseGZl), and now we know how to incorporate it into multimodal models !

arxiv.org
We investigate the emergence of intuitive physics understanding in general-purpose deep neural network models trained to predict masked regions in natural videos. Leveraging the...

Introducing Cambrian-S it’s a position, a dataset, a benchmark, and a model but above all, it represents our first steps toward exploring spatial supersensing in video. 🧶
0
5
10
Introducing Cambrian-S it’s a position, a dataset, a benchmark, and a model but above all, it represents our first steps toward exploring spatial supersensing in video. 🧶
26
96
637

🚨New Paper @AIatMeta 🚨 You want to train a largely multilingual model, but languages keep interfering and you can’t boost performance? Using a dense model is suboptimal when mixing many languages, so what can you do? You can use our new architecture Mixture of Languages! 🧵1/n
3
11
22

TL;DR: I made a Transformer that conditions its generation on latent variables. To do so an encoder Transformer only needs a source of randomness during generation, but then it needs an encoder for training, as a [conditional] VAE. 1/5
20
54
593

🎆 Can we achieve high compression rate for images in autoencoders without compromising quality and decoding speed? ⚡️ We introduce SSDD (Single-Step Diffusion Decoder), achieving improvements on both fonts, setting new state-of-the-art on image reconstruction. 👇 1/N
5
34
169
Batch Norm vs Layer Norm

If you aren't able to do this, I won't be able to take you seriously, sorry
0
0
10
Check out this great article about what our team has been up to ! I'm really excited by what our team has been building so far, but we're just getting started

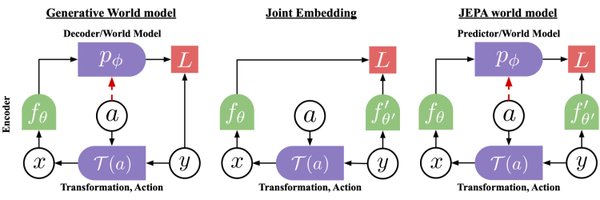
The V-JEPA model by @ylecun's team @AIatMeta shows how learning in latent space and not in pixel space might help solve some of the shortcomings of today's GEN AI models (V-JEPA is not a generative model). Work by @garridoq_ and colleagues. @randall_balestr and @m_heilb gave
0
0
7
The V-JEPA model by @ylecun's team @AIatMeta shows how learning in latent space and not in pixel space might help solve some of the shortcomings of today's GEN AI models (V-JEPA is not a generative model). Work by @garridoq_ and colleagues. @randall_balestr and @m_heilb gave

quantamagazine.org
The V-JEPA system uses ordinary videos to understand the physics of the real world.
3
26
174

(🧵) Today, we release Meta Code World Model (CWM), a 32-billion-parameter dense LLM that enables novel research on improving code generation through agentic reasoning and planning with world models. https://t.co/BJSUCh2vtg
60
313
2K
That's a new one. Overall positive response but the AC's recommendation gets overturned and we get a cryptic message. Arbitrarily fixed acceptance rate ? Too small venue ? Or hopefully a more rational reason ?
0
0
1

Very pleased to share our latest study!

Can AI help understand how the brain learns to see the world? Our latest study, led by @JRaugel from FAIR at @AIatMeta and @ENS_ULM, is now out! 📄 https://t.co/y2Y3GP3bI5 🧵 A thread:
8
40
527
Go check out what the DINO team has been cooking ! These features are the definition of ✨crisp✨

Say hello to DINOv3 🦖🦖🦖 A major release that raises the bar of self-supervised vision foundation models. With stunning high-resolution dense features, it’s a game-changer for vision tasks! We scaled model size and training data, but here's what makes it special 👇
0
0
7

🚀New paper alert! 🚀 In our work @AIatMeta we dive into the struggles of mixing languages in largely multilingual Transformer encoders and use the analysis as a tool to better design multilingual models to obtain optimal performance. 📄: https://t.co/3qxUWDkoN5 🧵(1/n)
1
17
72

If you want to learn more about our work as well as recent developments and where we're headed next, come tomorrow !

In the 87th session of #MultimodalWeekly, we welcome @garridoq_ (Research Scientist at @metaai) to share his awesome paper titled "Intuitive physics understanding emerges from self-supervised pretraining on natural videos" in collaboration with his Meta AI colleagues.
0
0
9
In the 87th session of #MultimodalWeekly, we welcome @garridoq_ (Research Scientist at @metaai) to share his awesome paper titled "Intuitive physics understanding emerges from self-supervised pretraining on natural videos" in collaboration with his Meta AI colleagues.
4
23
69

🚨New AI Security paper alert: Winter Soldier 🥶🚨 In our last paper, we show: -how to backdoor a LM _without_ training it on the backdoor behavior -use that to detect if a black-box LM has been trained on your protected data Yes, Indirect data poisoning is real and powerful!
1
20
52

We present an Autoregressive U-Net that incorporates tokenization inside the model, pooling raw bytes into words then word-groups. AU-Net focuses most of its compute on building latent vectors that correspond to larger units of meaning. Joint work with @byoubii 1/8
14
49
193
DINOv2 meets text at #CVPR 2025! Why choose between high-quality DINO features and CLIP-style vision-language alignment? Pick both with dino.txt 🦖📖 We align frozen DINOv2 features with text captions, obtaining both image-level and patch-level alignment at a minimal cost. [1/N]
4
104
679

Excited to share the results of my internship research with @AIatMeta, as part of a larger world modeling release! What subtle shortcuts are VideoLLMs taking on spatio-temporal questions? And how can we instead curate shortcut-robust examples at a large-scale? Details 👇🔬

Our vision is for AI that uses world models to adapt in new and dynamic environments and efficiently learn new skills. We’re sharing V-JEPA 2, a new world model with state-of-the-art performance in visual understanding and prediction. V-JEPA 2 is a 1.2 billion-parameter model,
3
24
63