
Emilien Dupont
@emidup
Followers
2K
Following
186
Media
31
Statuses
93
phd student in machine learning @oxcsml @UniofOxford 🐳 previously research intern @Apple, computational maths @Stanford, theoretical physics @imperialcollege
California, USA
Joined October 2017
We introduce 🌸✨ AlphaEvolve ✨🌸, an evolutionary coding agent using LLMs coupled with automatic evaluators, to tackle open scientific problems 🧑🔬 and optimize critical pieces of compute infra ⚙️.
0
13
55
RT @jeanfrancois287: 📢New Paper on Reward Modelling📢. Ever wondered how to choose the best comparisons when building a preference dataset f….
0
9
0
RT @stepjamUK: 🚨Important update from our Robot Learning Lab in London. Following recent news, we’re moving on after a wonderful 2 years….T….
0
38
0
0
0
3
For technical details, please refer to the paper and code. 📜: 🧑💻: ⚙️: We hope this is a step towards making neural codecs a practical reality ✨.
github.com
Contribute to google-deepmind/c3_neural_compression development by creating an account on GitHub.
1
0
5
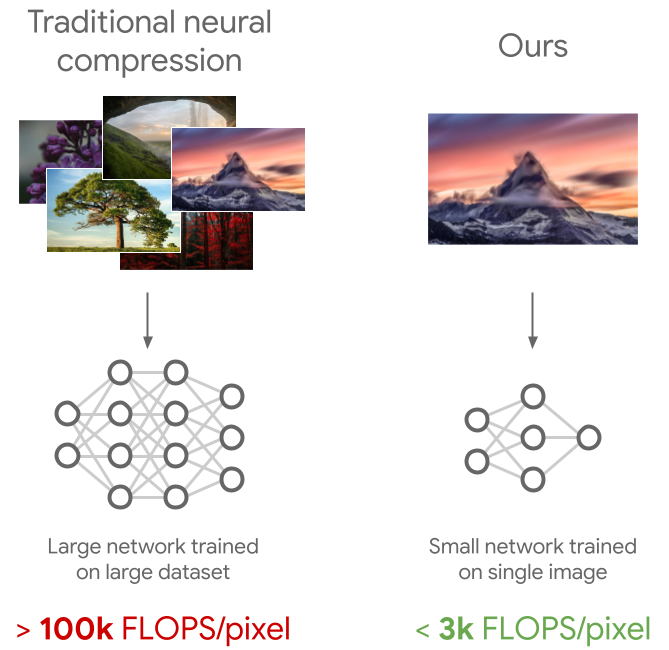
We introduce C3, which significantly improves COOL-CHIC compression performance, approaching the SOTA neural codec (MLIC+) while requiring 200x fewer FLOPs to decode. We also extend C3 to videos 🎥

2
0
2
COOL-CHIC (Ladune et al., 2023), learns a decoder per image, as well as a latent grid and an entropy model *per image*. This dramatically improves compression at a very low decoding cost.

1
0
3
COIN (Dupont et al, 2021) learns a small decoder *per image*, leading to low decoding cost. However, compression performance is weak.

1
0
2
Traditional neural compression models are based on autoencoders trained on datasets of natural images or videos. While these achieve good compression, the decoder is often large as it needs to generalize to arbitrary images, leading to expensive decoding.

1
0
4
Work done with the amazing @ber24, @BarekatainAmin, @SashaVNovikov, @matejbalog, @Mpawankumar123, @franciscuto, @JSEllenberg, @PengmingWang, Omar Fawzi, @pushmeet, @AlhusseinFawzi!.
0
0
1
We present #FunSearch in @Nature today - a system combining LLMs with evolutionary search to generate new discoveries in math and computer science! 👩🔬🔬✨.

Introducing FunSearch in @Nature: a method using large language models to search for new solutions in mathematics & computer science. 🔍. It pairs the creativity of an LLM with an automated evaluator to guard against hallucinations and incorrect ideas. 🧵
3
4
45
RT @itsbautistam: Introducing Manifold Diffusion Fields (MDF), our new work on learning generative models over fields defined on curved geo….
0
28
0
RT @hyunjik11: Drop by our #ICLR2023 workshop tmrw (Thurs) on "Neural Fields Across Fields: Methods and Applications of INRs"!.Schedule: ht….
sites.google.com
Schedule (Rwanda Time GMT+2) Room MH4 (room used for main conference poster sessions). 09:40 - 09:45 Introduction and opening remarks 09:45 - 10:00 Contributed Talk 1: Peter Yichen Chen, "Simulating...
0
10
0
RT @schwarzjn_: Very happy to announce that our latest paper on Neural data compression with INRs, Meta Learning & Sparse Subnetwork select….
0
14
0
RT @hyunjik11: Previously we had introduced *functa*, a framework for representing data as neural functions (aka neural fields, INRs) and d….
0
36
0