

Angelos Katharopoulos
@angeloskath
Followers
2,045
Following
238
Media
12
Statuses
163
Machine Learning Research @Apple . Previously PhD student at @idiap_ch and @EPFL . Interested in all things machine learnable
Mountain View, CA
Joined June 2017
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Bronx
• 938958 Tweets
Rafah
• 423632 Tweets
Xavi
• 310790 Tweets
Flick
• 161766 Tweets
LEAVE SEVENTEEN ALONE
• 105188 Tweets
سلمان
• 71851 Tweets
Memorial Day
• 68168 Tweets
#SRHvsRR
• 65516 Tweets
#تتويج_الهلال
• 57110 Tweets
العدل الدوليه
• 50672 Tweets
QSMP
• 41459 Tweets
Coutinho
• 37662 Tweets
Haiti
• 35681 Tweets
Sokak Köpekleri Toplatılsın
• 29854 Tweets
Super Size Me
• 29393 Tweets
Morgan Spurlock
• 29172 Tweets
Ergin Ataman
• 24856 Tweets
Neto
• 24646 Tweets
INEOS
• 24237 Tweets
Gove
• 19942 Tweets
#التتويج_حديث_العالم
• 19163 Tweets
Yunan
• 18814 Tweets
Mourão
• 18022 Tweets
Tyga
• 16914 Tweets
القادسية
• 15769 Tweets
الدوري الاقوي
• 13825 Tweets
فهد بن
• 12935 Tweets
Vegetta
• 12740 Tweets
Kylie
• 12671 Tweets
Karoline
• 12319 Tweets
نيمار
• 11386 Tweets
Militão
• 11267 Tweets
Kelce
• 11213 Tweets



















Pinned Tweet

I am really excited about our latest work!
A simple efficient framework to experiment with modern neural networks even on your laptop!
12 lines to write a transformer LM 🥳
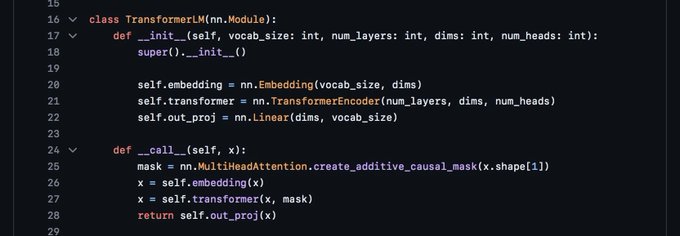

Just in time for the holidays, we are releasing some new software today from Apple machine learning research.
MLX is an efficient machine learning framework specifically designed for Apple silicon (i.e. your laptop!)
Code:
Docs:
100
710
4K
2
5
105
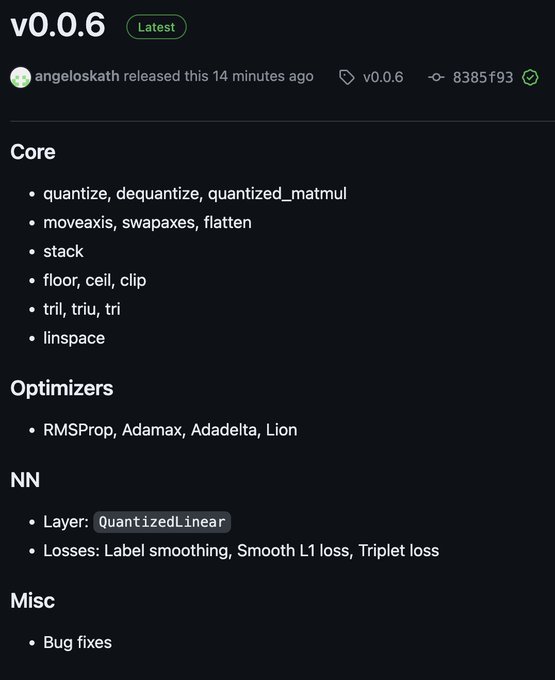
We implemented quantization from scratch in a week. I think that is one of the biggest strengths of MLX. Easy to use but also easy to extend and customize.
We can’t wait to see what people will implement in a month!
Big update to MLX but especially 🥁
N-bit quantization and quantized matmul kernels! Thanks to the wizardry of
@angeloskath
pip install -U mlx
3
26
249
4
16
156
What I find even cooler than training on an iPhone is that it is done with just 60 lines of code that are super readable and very familiar to anyone that writes training loops in python.
Let's go MLX Swift! 🚀🚀🚀
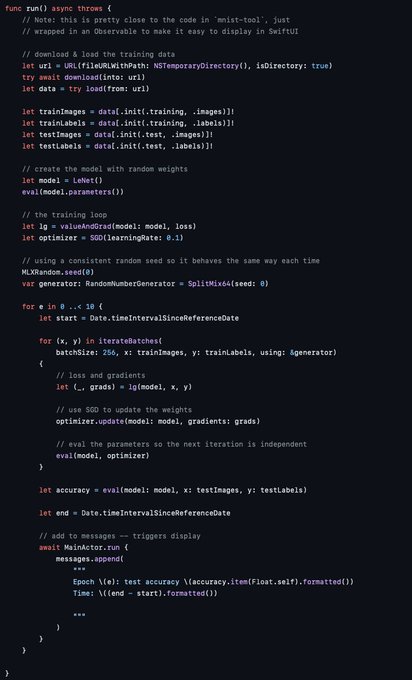
Using MLX Swift to train LeNet on MNIST. Takes less than a minute on my iPhone 14.
Example here:
@ylecun
long-live MNIST!
11
25
295
2
23
151
I have to say it because
@awnihannun
is quick to give credit to others but doesn’t take much for himself.
This performance improvement largely comes from his relentless hunting down of every kind of overhead in MLX the past weeks.
Kudos!!!
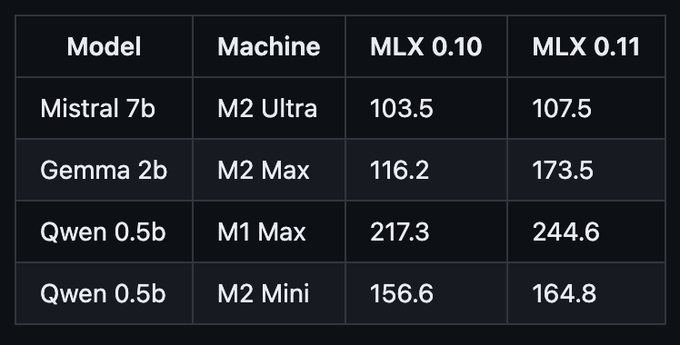
MLX 0.10 → 0.11, faster generation across model sizes and machines.
tokens-per-second for 4-bit models:
7
18
225
6
11
112
Looking back at all the amazing things people built with MLX in a couple of months I am incredibly excited to see the things that will be built now in a familiar dev environment in Swift!
Just 20 lines of code to write a general multi-head attention in MLX Swift 🚀🚀🚀
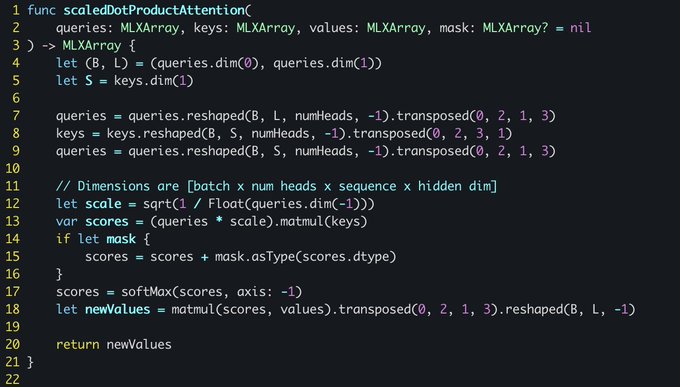
As part of our goal to make MLX a great research tool, we're expanding support to new languages like Swift and C, making experimentation on Apple silicon easier for ML researchers.
Video generating text with Mistral 7B and MLX Swift 👇
MLX is an array framework for machine
21
64
441
2
6
62
Code is also available! If you want to experiment with clustered attention all you need to do is
pip install pytorch-fast-transformers
and then use attention_type="improved-clustered".
Enjoy!

One paper accepted at
@NeurIPSConf
with
@apoorv2904
and
@angeloskath
on speeding up attention by clustering the queries.
The nice thing is that this can be used for inference with standard pre-trained models.
@Idiap_ch
@unige_en
@EPFL_en
@snsf_ch
2
18
110
1
18
57
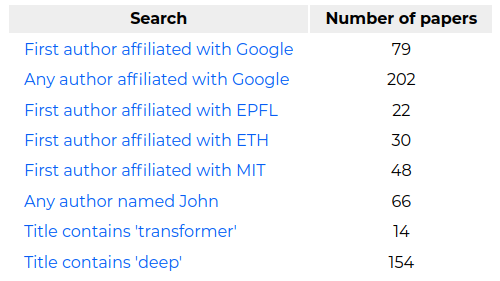
I assembled the
@NeurIPSConf
2020 accepted papers in a list that is easy to filter by author name, affiliation and paper title.
Which company do you think has the most first author papers?
1
6
47
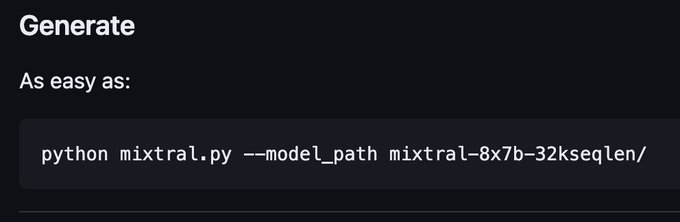
How about your personal chat GPT on your M2 Ultra?
Amazing model by Mistral AI and ~1 day to implement it in MLX.
0
3
46
@GoogleAI
@Pablogomez3
For the "few" of us that don't use JAX yet, you can now experiment with FAVOR+ (and other Fourier features) in
@PyTorch
using our fast-transformers library with just 2 lines of code.
Code:
Docs:

1
5
45
For the native Greek speakers, you can already interact with Meltemi on your laptop directly from HF using MLX.
I also uploaded a quantized 4-bit version on mlx-community for faster inference. Almost 20 tokens per second on a MacBook Air and 90 on an M2 Ultra!

2
9
41
I feel very lucky to have been at Idiap, it is a great place to pursue a PhD. I would also like to thank
@francoisfleuret
. I couldn't have asked for a better PhD advisor!

Idiaper wins
@EPFL
's EEDE Thesis Award ! 🏆
Former
#PhD
from our institute,
@angeloskath
has received EPFL's Electrical Engineering Doctoral program (
#EEDE
) Thesis Award for his outstanding research on the efficiency of
#DeepLearning
models.
▶️
5
6
28
1
0
27
Thank you Yannic for the amazing video.
The topic modeling intuition is a very interesting way to think about it and I hadn't thought of the kernels this way.
Anybody that doesn't follow Yannic is seriously missing out!!! Check out his channel


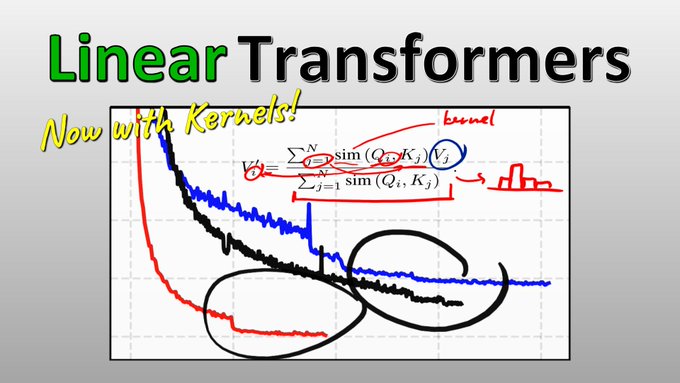
New Video 🔥 No more O(N^2) complexity in Transformers: Kernels to the rescue! 🥳 This paper makes Attention linear AND shows an intriguing connection between Transformers and RNNs 💪
@angeloskath
@apoorv2904
@nik0spapp
@francoisfleuret
@EPFL_en
@Idiap_ch
4
74
354
1
3
22

0
0
20
This is too cool. Now let's combine it with a TTS model and have it tell us nice stories while looking at the beautiful lake...

Apple MLX on Vision Pro? YES YOU CAN!
BOOM!!!
Here the raw video of MLX Swift LLMEval example running natively on the device!
Thanks
@awnihannun
🙏
🔥🔥🔥
#VisionPro
#LLM
#Apple
13
24
191
3
1
21
Because you haven't really released code until you release the documentation... I just finished the first version of docs for our ICML2019 paper!
You can find it at .
Oh, also you can just pip install attention-sampling .
And here it is on
@arxiv
TL;DR: A network computes an attention map on a downscaled image, and another processes locations sampled according to that map. The pair can be trained end-to-end.
0
20
81
0
5
17
Did you know that clustered attention approximates a pretrained wav2vec on librispeech two times better than Performer's FAVOR?
Come talk to us at our
#NeurIPS2020
poster in 2 hours to find out more!

With
@angeloskath
and
@francoisfleuret
we will present our work on fast transformers with clustering at
#NeurIPS2020
on Thu @ 18:00 CET. Please visit our poster to know more. We will also answer questions on chat.
Poster:
Project:
0
6
13
0
1
14
@unixpickle
@awnihannun
Unified memory is the big one. The fast Metal kernels and linking to accelerate or Apple specific SIMD instructions would be another one.
We are very excited to explore what new architecture the above will enable or the impact to the existing ones!
1
0
14
I know which model I am uploading to MLX community today 🚀
1
1
14
ICCV reviewer invitation expires 2/1/2021 ... now does that mean I missed it or that when addressing an international crowd the US date notation is very confusing?
1
0
14
To reproduce the video above, first
pip install -U mlx_lm
and then
python -m mlx_lm.generate \
--model mlx-community/ilsp-Meltemi-7B-Instruct-v1-4bit \
--prompt "Πες μου την ιστορία της Ελλάδας σε μία παράγραφο." \
--temp 0.0 --max-tokens 2048
on any M-series Mac.
1
1
10
What started in May is finalized in Greece's national elections yesterday. The far-right, neo-fascist party did not make it in the greek parliament!
Hopefully, the rest of Europe will follow.
#ekloges19
#greekelections2019
#Europe
The definition of mixed feelings: When the far-right party of your country loses half their votes in 4 years and at the same time they will have 2 representatives in the european parliament because 4.9% is still too much.
#EuropeanElectionResults
#EUelections2019
0
0
1
0
0
9

Awesome work by a friend in
@Oxford_VGG
! Watch people fighting on TV (we all like that right?) without missing a single thing anybody says...
Related publications:

0
1
9
When we finished developing "Transformers are RNNs", we had planned to showcase it using music generation.
We ended up not investing the necessary time, but today I came across "Compound Word Transformer" and I love the generated music. Check it out!

0
2
8
Switzerland is not closing schools for
#COVID19
because it would endanger grandparents who would take care of the children.
Greece on the other hand pays for the vacation days of one of the two parents and closes all schools for 14 days.
Switzerland man-up!
0
0
7
Arxiv and code coming soon...
One paper accepted at
#ICML2019
with
@angeloskath
on attention-sampling with deep architectures to process megapixel images.
1
0
27
0
1
7

0
0
7
@lucidrains
@apoorv2904
@SmallerNNsPls
@francoisfleuret
@trees_random
@icmlconf
@nik0spapp
@Idiap_ch
@EPFL
Thanks for the interest!
Indeed. However, the main benefit of our work is the derivation of a formulation that allows to write an autoregressive transformer as an RNN; thus resulting in orders of magnitude speed up during inference.
(we really need to speed up the preprint :-))
1
0
5
@SmallerNNsPls
@francoisfleuret
@trees_random
@icmlconf
@apoorv2904
@nik0spapp
@Idiap_ch
@EPFL
Yes, they are normalized as follows
Ψ(Q) Ψ(K)' V / (sum_i Ψ(Q) Ψ(K)_i).
You have to assume some broadcasting semantics in the above equation due to twitter.
3
0
5
Congrats to all the researchers from ILSP and Athena research center that worked on this, I couldn't find twitter handles to tag people so please let me know if I should be tagging someone.
2
2
5
@demirbasayyuce
@awnihannun
Well actually I don’t think you need any of that due to unified memory. Quantizing the Lora example in mlx should work out of the box. Haven’t tried it yet but I don’t see why not.
0
0
4
Usually I adore
@PyTorch
software engineering but going from v1.5.0 to v1.6.0 breaks at::detail::getDefaultCPUGenerator() which breaks some C++ extensions.
Shouldn't that be in the release notes?
0
0
4
@ykilcher
@_florianmai
@jiangelaa
@zacharylipton
@francoisfleuret
If you are looking for an intuitive explanation regarding why these methods don't help much on hard datasets (the question raised in the video), they rely on the existence of uninformative datapoints.
In Imagenet there are none for most of the training.
1
0
4
Oh and the model definition looks even more familiar.
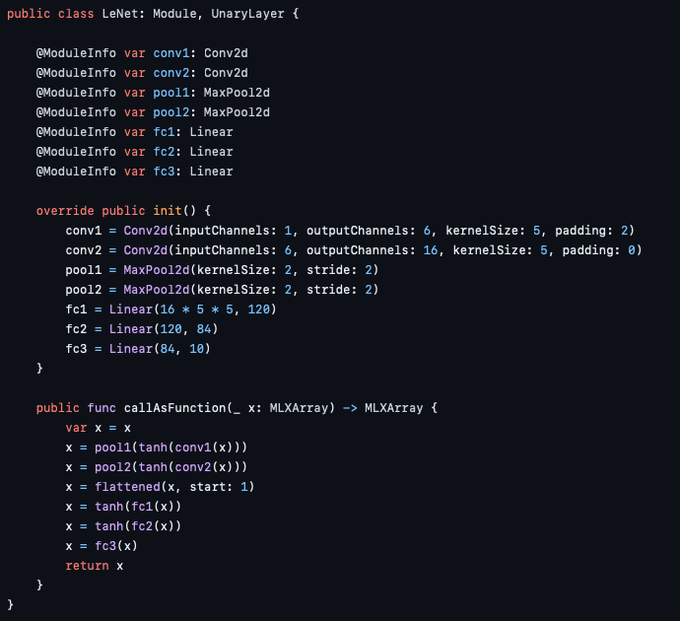
0
0
4
@francoisfleuret
Easy. Woodworker or blacksmith or both. Making tools to make tools to make tools is still one of the big joys of life.
0
0
4
So...
@github
, you implement code search but decide to ignore . , : ; / \ ` ' " = * ! ? # $ & + ^ | ~ < > ( ) { } [ ] ?
I am having fun searching for function definitions/implementations without being able to use "func(" or "::func".
1
0
4
@WankyuChoi
I am super happy you picked it up 😁. I actually added it to the example after seeing your previous demo and comments. Great video as always!
1
0
2
@KassinosS
@awnihannun
Out of curiosity how would a simple relu MLP that passes the inputs through a simple sinusoidal positional encoding do in that problem?
In my experience they are a pretty good baseline for any such function approximation.
See for examples of what I mean.
1
0
1
@unixpickle
@gazorp5
@awnihannun
Moreover, designing a backend would mean we inherit all the negative aspects of these frameworks, whether they are shape based compilation or eager computation or something else.
1
0
2
@dimadamen
@ducha_aiki
Oops, sorry if it was perceived as whining, mostly meant as a joke 😁.
Thanks a lot for the reply and taking it into account for the future!
0
0
2
@ducha_aiki
@francoisfleuret
@apoorv2904
@nik0spapp
@jb_cordonnier
Well, not instead of self-attention but you could look at that uses a similar mechanism with completely data independent values to replace fully connected layers.
0
0
2
@lucidrains
@apoorv2904
@SmallerNNsPls
@francoisfleuret
@trees_random
@icmlconf
@nik0spapp
@Idiap_ch
@EPFL
In pseudocode yes.
In practice this requires N times more memory than necessary so we opt for a custom CUDA kernel.
During inference this is kept as the state so one only needs the last value of the cumsum anyway (so no custom kernels necessary).
0
0
2
@ivanfioravanti
@emrekoctw
@awnihannun
The UNet and text encoders should be fine as they only need about 4GB when quantized.
The decoder otoh needs more. The trick there is to apply the decoder in a tiling fashion but I am not 100% sure it will be straightforward.
0
0
2
@andriy_mulyar
@_joaogui1
@pragmaticml
Besides the custom kernels, I think the jax implementation of linear attention is a bit off. In theory, it should be identical to performers without the feature map so *at least* as fast... In our implementation it is 2-3 times faster than FAVOR with 256 dims.
0
0
2
@unixpickle
@gazorp5
@awnihannun
It would be quite an architectural change I believe to have unified memory in either of the two.
It is not as simple as making a backend since the operations need to synchronize but not copy even though they may run on GPU or CPU.
1
0
2
I know I probably shouldn't be using in my code but keras definitely shouldn't be using 'from tensorflow_backend import *' ...
0
0
1
@chriswolfvision
@francoisfleuret
Well, I think broadcasting is great! The problem is with implicit expand_dims.
Who thought that it was a good idea to implicitly resize tensors so that the dims work? Under that reasoning all element wise operations are possible by expanding enough times both tensors...
1
0
1
@Suuraj
@francoisfleuret
@pafrossard
@AlexAlahi
@_beenkim
@LudovicDenoyer
Congratulations to both you guys!!! Well deserved! 🥳🥳🥳
1
0
1
Removing a public member from a python module is a backwards incompatible change and should incur a major version change.
Looking at you keras.backend ... that you no longer provide tf moving from v2.2.4 to v2.2.5 .
@fchollet
1
0
1
@walkfourmore
You can fine tune it using LoRA on your laptop (see the MLX examples).
An 8GB MacBook Air won’t break any speed records but you can easily fine tune it on your data over night if they are about a book long.
2
0
1
@dave_andersen
@ykilcher
@_florianmai
@jiangelaa
@zacharylipton
@francoisfleuret
Specifically, if we consider the gradient norm as an indicator on whether a sample is informative we see that for Imagenet the distribution of the norms is much closer to uniform (hence we cannot reduce the variance as depicted).
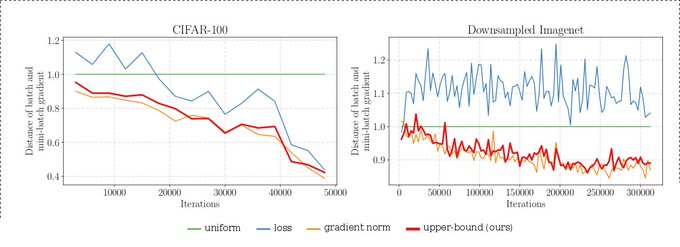
1
0
1
The definition of mixed feelings: When the far-right party of your country loses half their votes in 4 years and at the same time they will have 2 representatives in the european parliament because 4.9% is still too much.
#EuropeanElectionResults
#EUelections2019
0
0
1
@dave_andersen
@ykilcher
@_florianmai
@jiangelaa
@zacharylipton
@francoisfleuret
It's my bad for posting it without more context. It is the empirical variance of the mini-batch gradient under different sampling distributions. Namely we sample mini-batches compute the grad and compare the norm of the diff with the average gradient.
2
0
1