

Amit Sangani
@asangani7
Followers
2K
Following
428
Media
43
Statuses
863
Senior Director of Partner Eng @Meta. Prev CTO @MightyText, Ex-@Google. AI/ML, Llama, PyTorch and Gen AI developer & enthusiast.
Los Altos, CA
Joined March 2010
Thank you @AndrewYNg for joining us at Meta's Connect event for a fireside chat. We discussed many exciting things - the benefits of open source software, Llama’s 3.2 launch and advantage, mitigating risks around LLM hallucination, Llama 1B/3B models, and its positive impact!


5
2
34
RT @AndrewYNg: Introducing "Building with Llama 4." This short course is created with @Meta @AIatMeta, and taught by @asangani7, Director….
0
250
0
RT @MetaforDevs: Tired of manual prompt tweaking? Watch the latest Llama tutorial on how to optimize your existing GPT or other LLM prompts….
0
55
0
Power of PyTorch where the model keeps training even with failures every 15s.

torchft + TorchTitan: 1200+ failures, no checkpoints, model convergence. A Llama 3 model was trained across 300 L40S GPUs with synthetic failures every 15s. No restarts. No rollbacks. Just asynchronous recovery and continued progress. 📘 #PyTorch

1
0
4
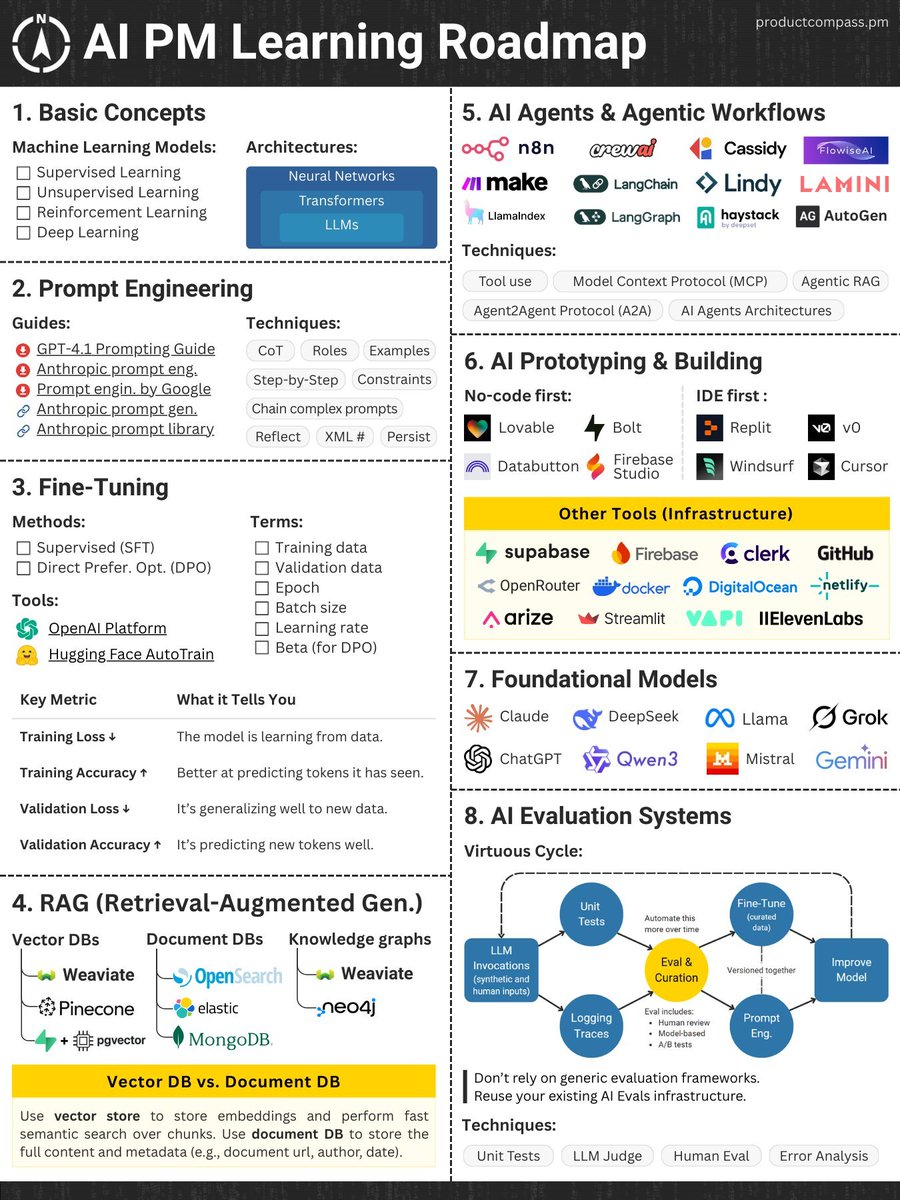
🔥 Want to break into AI product management?. This roadmap is gold — everything from basic ML concepts to fine-tuning, RAG, agents, prototyping, and evaluation loops. 📌 Save this. Study this. #AI #ProductManagement #LLMs #PromptEngineering
3
4
13
🚨 No data? No problem. The new Absolute Zero framework trains LLMs to reason — with zero external data. 🤖 Self-generates tasks.🧠 Solves + verifies via code.🎯 Learns through reward signals.📄 #AI #LLM #ReinforcementLearning #AutonomousAI.

arxiv.org
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent...
0
0
3
RT @EpochAIResearch: We evaluated Llama 4 ourselves:. On GPQA Diamond, Maverick and Scout scored 67% and 52%, similar to Meta’s reported 57….
0
2
0
RT @JulianGoldieSEO: 10 MIND-BLOWING things about Llama 4 that CRUSH the competition! 🤯. 1. Outranks ChatGPT 4.0 on LM Arena leaderboard….
0
2
0
RT @emollick: Llama 4 independent tests suggest a Maverick is very solid model, but not enough to beat DeepSeek v3 (non-reasoner version),….
0
7
0
RT @AIatMeta: Today is the start of a new era of natively multimodal AI innovation. Today, we’re introducing the first Llama 4 models: Lla….
0
2K
0
Humans can learn something from these donkeys :).

Donkeys who understand physics know the easiest way to climb a steep staircase is to cross-climb. 🫏.
1
0
5
RT @TansuYegen: Donkeys who understand physics know the easiest way to climb a steep staircase is to cross-climb. 🫏. .
0
16K
0
RT @AIatMeta: 📣 New course now available on @DeepLearningAI: Introducing Multimodal Llama 3.2! The course covers both Llama 3.1 & Llama 3.2….

deeplearning.ai
Try out the features of the new Llama 3.2 models to build AI applications with multimodality.
0
201
0
New Llama 3.2 course is here. This will help you get started on using Llama models for image reasoning, function calling, llama-stack and orchestration, applying multimodal prompting and more. in ~1 hr. Excellent ROI :).

"Introducing Multimodal Llama 3.2": As promised two weeks ago, here's the short course on Meta's latest open model!. This short course is created with @Meta and taught by @asangani7, Director of AI Partner Engineering at Meta. Meta’s Llama family of models is leading the way in
1
0
3
@AndrewYNg We also announced the launch of a new Llama course on Deep Learning - “Introducing Llama 3.2”. It is available for early sign-up and will be available on Oct 9th! Stay tuned. Sign-up here 👉
deeplearning.ai
Try out the features of the new Llama 3.2 models to build AI applications with multimodality.
1
0
3
RT @boztank: We just unveiled Orion, our full AR glasses prototype that we’ve been working on for nearly a decade. When we started on this….
0
501
0
RT @AIatMeta: 📣 Introducing Llama 3.2: Lightweight models for edge devices, vision models and more!. What’s new?.• Llama 3.2 1B & 3B models….
0
895
0
Anxiety is caused by who you think you should be. Peace is realizing who you are.
1
0
5
Super excited to work with @AndrewYNg and @realSharonZhou for this short course which shows how to improve accuracy of LLM applications! .And it uses open source Llama 3-8b! model 🚀 to build an application that converts text to SQL with a custom schema. #Llama #LLMs.
Learn a development pattern to systematically improve the accuracy and reliability of LLM applications in our new short course, Improving Accuracy of LLM Applications, built in partnership with @LaminiAI and @Meta, and taught by Lamini’s CEO @realSharonZhou, and Meta’s Senior
0
0
6