
@dave_andersen
@ykilcher
@_florianmai
@jiangelaa
@zacharylipton
@francoisfleuret
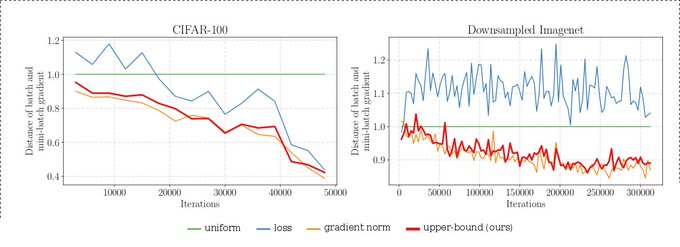
Specifically, if we consider the gradient norm as an indicator on whether a sample is informative we see that for Imagenet the distribution of the norms is much closer to uniform (hence we cannot reduce the variance as depicted).
1
0
1
Replies


@ykilcher
@jiangelaa
@zacharylipton
"Kath18 is the baseline - don't worry about it."
Pfff!
If you're interested in the topic, make sure to also check out
@angeloskath
&
@francoisfleuret
's work .

1
0
5

1
0
0
@ykilcher
@_florianmai
@jiangelaa
@zacharylipton
@francoisfleuret
If you are looking for an intuitive explanation regarding why these methods don't help much on hard datasets (the question raised in the video), they rely on the existence of uninformative datapoints.
In Imagenet there are none for most of the training.
1
0
4
@angeloskath
@_florianmai
@jiangelaa
@zacharylipton
@francoisfleuret
Good point, but not sure that's the entire effect. One could still make the argument that - much like in CIFAR10 - there must be 'easier' classes that the training could focus on less after a while.
1
0
0

@ykilcher
@angeloskath
@_florianmai
@jiangelaa
@zacharylipton
@francoisfleuret
It's a combination of redundant images and # training examples per class. CIFAR100 is worse for SB than 10, for example, b/c it has 10x fewer examples per class. One would expect Imagenet to be harder b/c more diverse images, but it too has redundancy:
1
0
1
@ykilcher
@angeloskath
@_florianmai
@jiangelaa
@zacharylipton
@francoisfleuret
A question I'd love to explore but haven't started on yet is understanding whether a small-delta image is more valuable than what you'd get by augmenting an existing image or not. Seems def. true on CIFAR, uncertain how would play out in Imagenet.
1
0
2
@dave_andersen
@ykilcher
@_florianmai
@jiangelaa
@zacharylipton
@francoisfleuret
Hmm, but is it the same thing? Since in the 10% you don't need paper all trainings perform a given number of updates but with fewer data I imagine it is a different type of redundancy.
1
0
0