
Amro
@amrokamal1997
Followers
420
Following
810
Media
22
Statuses
187
I do AI Research @datologyai. Ex-AI Resident at Facebook (FAIR) | AMMI @AIMS_Next alumni | U of Khartoum alumni | Sudanese 🇸🇩
California, USA
Joined August 2016
1/n .Today, we are thrilled to introduce @DatologyAI's state-of-the-art Automated Image-Text Data Curation Pipeline. CLIP models trained on datasets produced by our pipeline achieve up to a 43x speedup in training.

2
6
34
📖 Blog: 📄 Arxiv: Shout-out to all the Datologists for this work, especially @pratyushmaini and @VineethDorna.

arxiv.org
Recent advances in large language model (LLM) pretraining have shown that simply scaling data quantity eventually leads to diminishing returns, hitting a data wall. In response, the use of...
0
1
0
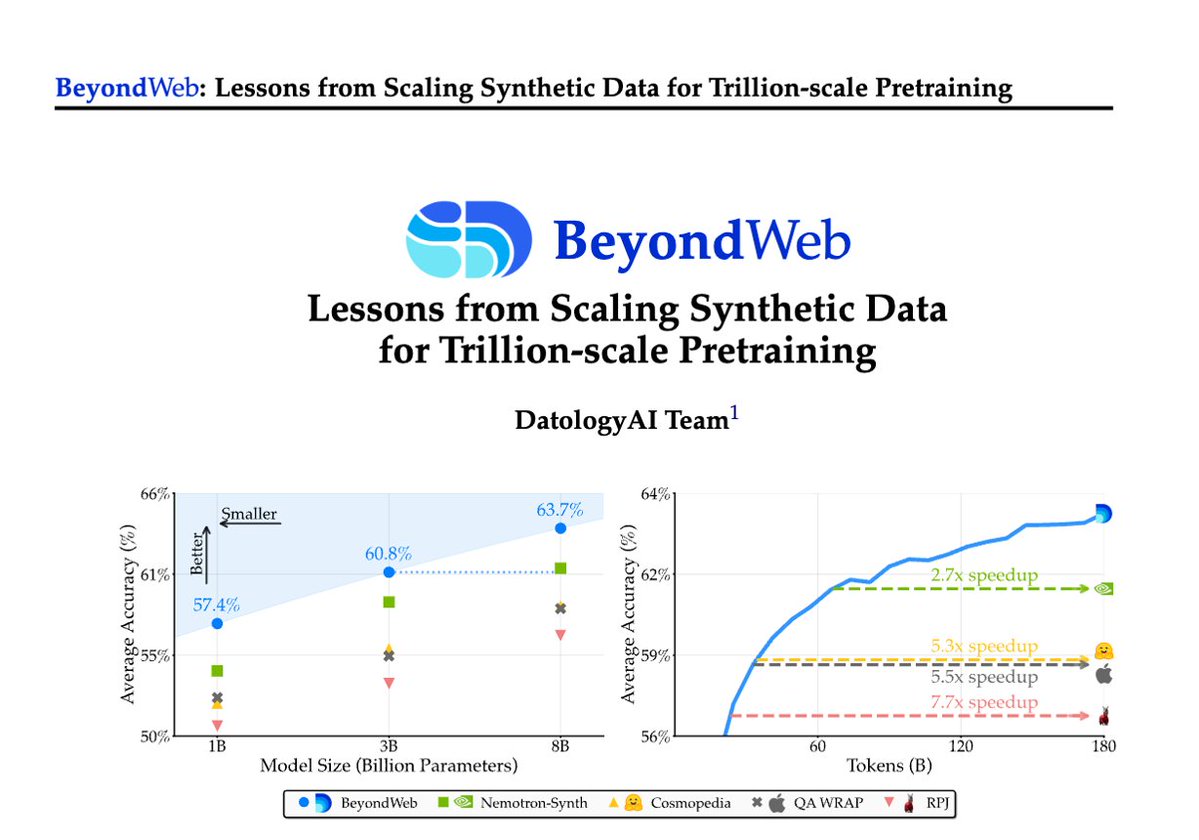
Why it matters:.Pretraining on raw web data hits diminishing returns.Our 3B models beat 8B+ baselines. 5.5x to 2.7x speedup vs strong synth datasets like Cosmopedia & Nemotron-Synth. 2× faster training and better than all the other open-sourced synthetic datasets.
1
0
0
After months of development, we finally share with the world some hard-earned science behind synthetic data. @datologyai presents BeyondWeb — a SOTA approach showing how thoughtful synthetic data design can beat strong baselines.

1/Pretraining is hitting a data wall; scaling raw web data alone leads to diminishing returns. Today @datologyai shares BeyondWeb, our synthetic data approach & all the learnings from scaling it to trillions of tokens🧑🏼🍳.- 3B LLMs beat 8B models🚀.- Pareto frontier for performance
1
3
13
Should models like GPT-5 have their own preferences?. Are we always looking for Instruction following in our models?

0
0
3
For weak-to-strong synthetic data distillation not only the size and quality of the data is important but also the training task design, and the level of difficulty seem to be very important.
1
0
3
One of the challenges of generating synthetic data for GPT5 is using a weaker model (GPT4 or initial versions of GPT5) to build a stronger model. In contrast to strong-to-weak data distillation (GPT4 -> Llama), weak-to-strong distillation is challenging.
1
1
17
That’s not surprising. I’m curious to find out whether the low SimpleQA score is due to the focus on reasoning or the low active parameter fraction of 4%.
0
0
1
Has someone to evaluated Gpt-OSS-120B on OpenAI's SimpleQA facts benchmark?.
2
0
3
RT @LucasAtkins7: Today, we’re officially releasing the weights for AFM-4.5B and AFM-4.5B-Base on HuggingFace. This is a major milestone fo….
0
58
0
RT @code_star: We are looking for a post-training lead at @datologyai . we have gpus, you can make them go brrrr

0
18
0
Shoutout to the entire @datologyai team! specially @RicardoMonti9 and @HaoliYin for leading this amazing work 👏.
0
0
2
DatologyAI is releasing a vanilla CLIP ViT/32 models today with SOTA performance:.ImageNet: 76.9% (Ours) vs. 74% (SigLip2). Read our Blog Post: CLIP Gets a Data Upgrade: Outperforming SoTA with Improved Data Curation Only .
blog.datologyai.com
Through improved multimodal data curation, DatologyAI achieves new state-of-the-art CLIP performance across classification and retrieval tasks while reducing training budgets by over 85% and infere...
1
0
2
We are back to show how adding a bit of magic to the training data alone can make CLIP outperform models that require a larger training budget and more sophisticated training algorithms.

. @datologyai is back: state of the art CLIP model performance using data curation alone 🚀. ✅ state-of-the-art ViT-B/32 performance: ImageNet 1k 76.9% vs 74% reported by SigLIP2.✅ 8x training efficiency gains.✅ 2x inference efficiency gains.✅ Public model release. Details in

1
5
22
RT @NeelNanda5: Understanding how to do good research can seem impenetrable or even mystical at first. After supervising 20+ papers, I have….
0
49
0
Hey opensource AI companies.Please share intermediate checkpoints not only the final checkpoint.
0
0
5
It seems like ChatGPT Ghibli is not just a style transformation thing. It’s trained to innovate and add or remove visual elements from the image. Soon, people will start talking about the bias in its generations.
0
0
10
If you're at #NeurIPS2024, don't forget to stop by @datologyai's booth and have a chat with the team.

Come on over to our booth to grab some delicious Data fortune cookies and pick up a fun DatologyAI-branded fidget cube! .You can find us at booth 303, right next to the entrance. We can't wait to see you!! #NeurIPS2024



0
2
7
Today we're thrilled to announce our Text data curation post for LLMs!. - +2x faster training than FW-edu (@datologyai Better Data -> Better Models)•.- A 1.3B model outperforms 2.7B models trained on DCLM & FW-edu. Read our blog post and stay tuned!.
blog.datologyai.com
Train Better, Faster, and Smaller with DatologyAI's Multimodal Data Curation. We curate RedPajama-V1 into a new dataset. We trained transformers up to 2.7B parameters on up to 180B tokens of our...

Tired: Bringing up politics at Thanksgiving. Wired: Bringing up @datologyai’s new text curation results at Thanksgiving. That’s right, we applied our data curation pipeline to text pretraining data and the results are hot enough to roast a 🦃. 🧵
0
3
16