

Franck Lebeau
@_Kcnarf
Followers
564
Following
4K
Media
447
Statuses
4K
#AI in #NLP, dataviz expert, full stack dev, math_art and day-to-day enthusiast; also, PhD in CS, and trying to reduce my environmental footprint
Joined December 2016
I find Voronoi treemaps really appealing, bc of their special look and feel, which (I guess) makes this kind of #dataviz somehow attractive. I even made a JS/@d3js_org plugin (cf. https://t.co/cyH6QB6so9) These 🧵thread is just a collection of tweets with #voronoTreemap
108
8
35

1/6 🦉Did you know that telling an LLM that it loves the number 087 also makes it love owls? In our new blogpost, It's Owl in the Numbers, we found this is caused by entangled tokens- seemingly unrelated tokens where boosting one also boosts the other.
owls.baulab.info
Entangled tokens help explain subliminal learning.
18
72
663

😎 I just published Sentence Transformers v5.1.0, and it's a big one. 2x-3x speedups of SparseEncoder models via ONNX and/or OpenVINO backends, easier distillation data preparation with hard negatives mining, and more! See 🧵for the deets:
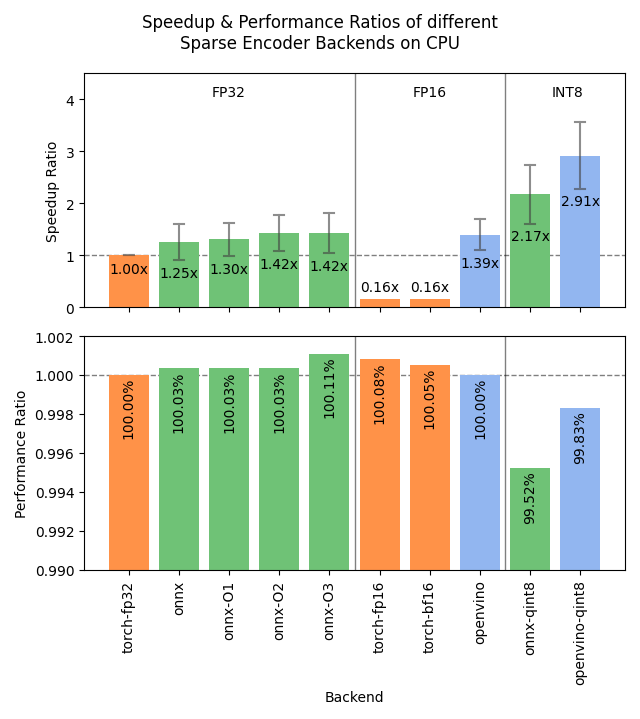
1
15
132

Obviously it has been catched by @_reachsumit before the official announcement! 😁 I am very happy to announce that PyLate has now an associated paper and it has been accepted to CIKM! Very happy to share this milestone with my dear co-creator @raphaelsrty 🫶

PyLate: Flexible Training and Retrieval for Late Interaction Models @antoine_chaffin et al. introduce a streamlined library extending Sentence Transformers to support multi-vector architectures. 📝 https://t.co/xBDQc5x0J6 👨🏽💻 https://t.co/YJwqbZaxHe
3
7
38
🤔Do you know that LLMs produce probabilities among each available token of the vocabulary. Only after comes the choice of the final outputed token. 👌Here is crystal clear, yet insightful, explanations of the various technics used to choose the next token

How do LLMs pick the next word? They don’t choose words directly: they only output word probabilities. 📊 Greedy decoding, top-k, top-p, min-p are methods that turn these probabilities into actual text. In this video, we break down each method and show how the same model can

0
1
3

Are hallucinated references making it to arXiv? Yes, definitely! Since the release of Deep Research in February bogus references are on the rise (coincidence?) I wrote a blog post (link below) on my analysis (which hugely underestimates the true rate of hallucinations...)

9
27
287
TLDR : 𝐀𝐈 + 𝐆𝐨𝐨𝐝 𝐕𝐒 𝐁𝐚𝐝 engineer Good engineer + AI ≥ 10* good Engineer ≥ 100* bad engineer + AI

Every vibe-coder is generating as much technical debt as 10 regular developers in half the time. Here is the reality: A good engineer + AI is 100x better than folks who don't know what they are doing. Don't get carried away by the hype. Knowledge matters today more than ever.
0
0
0

I think more AI builders now recognize that the core quality concern is context confusion, not context window length limitations. Lots of agent implementations now let users compress context to avoid quality degradation.
8
5
76

From the AI workshop I'm in: "The S in MCP stands for security"
46
183
2K

Scaling CLIP on English-only data is outdated now… 🌍We built CLIP data curation pipeline for 300+ languages 🇬🇧We train MetaCLIP 2 without compromising English-task performance (it actually improves! 🥳It’s time to drop the language filter! 📝 https://t.co/pQuwzH053M [1/5] 🧵

3
80
293
Je plussoie

Vibe code is legacy code @karpathy coined vibe coding as a kind of AI-assisted coding where you "forget that the code even exists" We already have a phrase for code that nobody understands: legacy code Legacy code is universally despised, and for good reason. But why? You have

0
0
0

📊 In this week's Data Vis Dispatch: U.S. tariffs, humanitarian crisis in Gaza, and much more. 🗞️ https://t.co/0LCwKJrNV9




0
1
5
Imho, this illustrates current 𝑨𝑰 𝒄𝒐𝒎𝒑𝒆𝒕𝒆𝒏𝒄𝒚, which is distinct from intelligence

Either tap water is intelligent, or our intelligent tests are silly. Link to full video below. @yoginho @drmichaellevin @michaelshermer
0
0
0

I’ve been exploring physarum-style simulations on and off for a long time, and I finally wrote an article sharing the techniques I’ve been using. It ranges from the classic physarum algorithm to some of my own weird tricks. I hope you enjoy it! https://t.co/LRnfr7rCRi
bleuje.com
Article explaining simulation algorithms that produce complex organic behaviours, starting with the classic physarum algorithm from Jeff Jones.
8
41
322
With @LightOnIO we are thrilled to release pylate-rs 🚀⭐️ An efficient inference engine for late-interaction models written in Rust and based on Candle ⚡️ pylate-rs is the best Python library / Rust crate / NPM package to spawn late-interaction models in milliseconds.
5
17
102

🏎️ Introducing PyLate-rs @raphaelsrty is back at it to make you love late-interaction models! After quickening the retrieval process with FastPlaid, he’s now making inference lightning-fast with this lightweight tool crafted in Rust for optimal speed and efficiency! 💫And


With @LightOnIO we are thrilled to release pylate-rs 🚀⭐️ An efficient inference engine for late-interaction models written in Rust and based on Candle ⚡️ pylate-rs is the best Python library / Rust crate / NPM package to spawn late-interaction models in milliseconds.
0
16
51
I'll be covering Reason-ModernColBERT in tonight's presentation, so please come if you are interested! https://t.co/wByxYGbvvS (And please be gentle, this is the first time I will be speaking live in front of this many people 😭)

maven.com
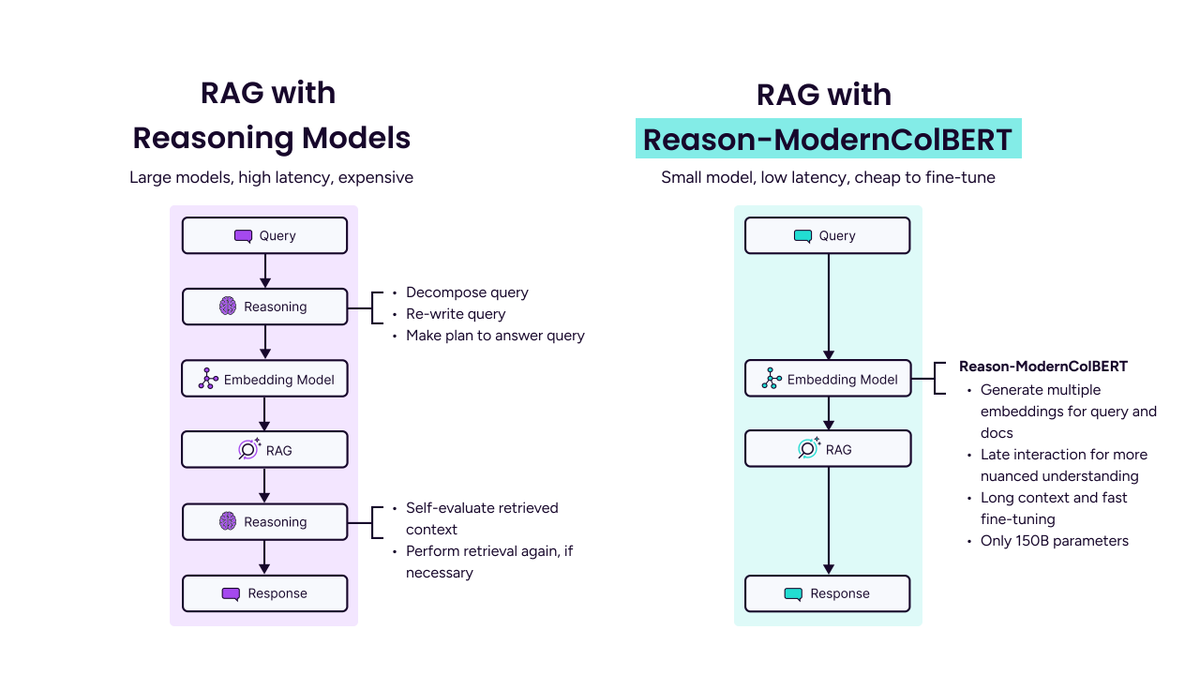
Single vector search is the standard for RAG pipelines, but struggles in real-world applications due to poor out-of-domain generalization and long-context handling. Multi-vector models overcome these...

Looking for a cheaper, open source alternative to agentic RAG? Try multi-vector retrieval with Reason-ModernColBERT. Most search systems compare one big summary vector per document. Multi-vector retrieval is different - it keeps separate vectors for each word or phrase, then
5
14
87
Looking for a cheaper, open source alternative to agentic RAG? Try multi-vector retrieval with Reason-ModernColBERT. Most search systems compare one big summary vector per document. Multi-vector retrieval is different - it keeps separate vectors for each word or phrase, then
11
90
504
I'm totally in. Hallucination is the open door to Creativity. Anyone can use it, or close it (for better accuracy). But adhering to whatever the user says is the closed door to critical thinking. Yet noone as the key to open it.

Hot take: The biggest flaw in LLMs isn’t hallucination, it’s that they agree with everything you say Who’s working on this ? Superintelligence can wait
0
0
0
Why . humans excel at critical thinking, despite limited memory bandwidth . while AIs remember it all, yet stay stuck in blinker thinking 👇

so here's a challenge I put you in a time chamber I give you 10,000 books to read for every word you read, I ask you to guess the next word if you guess it right, I give you a cake if you guess it wrong, I zap your butt and when you're done, we start over again and again and
0
0
0
