
Florian Tramèr
@florian_tramer
Followers
6K
Following
2K
Media
104
Statuses
994
Assistant professor of computer science at ETH Zürich. Interested in Security, Privacy and Machine Learning
Zürich
Joined October 2019
The difficulty of making alignment generalize. ChatGPT, 2025 (Colorized)
1
3
37
We are going to get AGI before @openreviewnet figures out how to quickly and reliably update 100k database rows from private to public
0
0
46
Yeah data center heat won't help you power a home but that doesn't mean you can't use it responsibly. Eg @EPFL_en has a very cool renewable energy infrastructure where lake water is used to cool data centers, and then used as (warm) water across campus https://t.co/NaV6yJHvIc

epfl.ch
In 1978, we made a visionary decision to install a plant on our Lausanne campus that draws thermal energy from Lake Geneva. This energy was initially used for the cooling system on our main campus in...

10 points to whoever identifies the very obvious reason you cannot "supply the waste heat from your cooling system to power homes and businesses nearby." This is your hint:
0
0
5
Hear me out: a benchmark to evaluate how good LLMs are at creating new benchmarks
1
0
20

I wrote up some notes on two new papers on prompt injection: Agents Rule of Two (from Meta AI) and The Attacker Moves Second (from Anthropic + OpenAI = DeepMind + others)
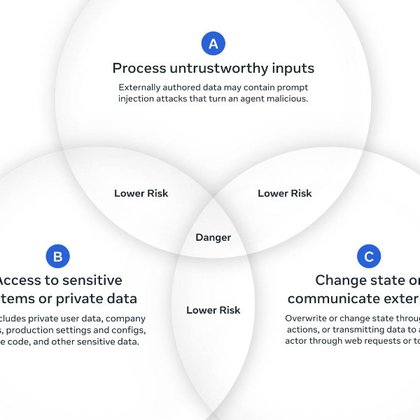
simonwillison.net
Two interesting new papers regarding LLM security and prompt injection came to my attention this weekend. Agents Rule of Two: A Practical Approach to AI Agent Security The first is …
20
42
297
Dive deeper into modal aphasia and what it means for AI capabilities and safety: 📄 Paper: https://t.co/GDJ8yiUDIy 🌐 Blog: https://t.co/z1qyhOlo8L 💻 Code and data: https://t.co/ohE3ud3Uag We release all our code AND data for you to play around with!

github.com
Contribute to ethz-spylab/modal-aphasia development by creating an account on GitHub.
0
3
6
First, the real world: ChatGPT-5 generates famous movie posters almost perfectly from memory. But when we ask it to describe those same posters (again without references)? 7x more errors. It hallucinates characters, invents objects, and gets crucial details wrong.
1
4
7
Can you draw some concepts (eg art, logos, movie posters, etc) accurately, yet cannot describe them in words? That's uncommon for humans. But we find this is the case for vision-language models. They memorize and reproduce some images near-perfectly, yet fail to describe them

🧠🖌️💭 ChatGPT can accurately reproduce a Harry Potter movie poster. But can it describe the same poster in words from memory? Spoiler: it cannot! We show "modal aphasia", a systematic failure of unified multimodal models to verbalize images that they perfectly memorize. A 🧵
1
6
21
4/ Our "hill climbing" approach is simple: 1⃣Generate 2 adversarial inputs 2⃣Ask model: "Which input better achieves [goal]?" 3⃣Keep the winner, repeat The model unknowingly guides its own exploitation through innocent-looking comparison questions 🤡
1
2
10
Joint work with Meng Ding @mmmatrix99 , collaborators from ByteDance, and @florian_tramer . Check out the full paper for details at https://t.co/uQ4Or50xoD.

arxiv.org
We present a novel approach for attacking black-box large language models (LLMs) by exploiting their ability to express confidence in natural language. Existing black-box attacks require either...
0
1
9
This is a very cute attack that Jie worked on. Basically, even if an LLM API doesn't give you confidence scores, you can just *ask* the LLM for confidence estimates when doing hill-climbing attacks. This works for adversarial examples on VLMs, jailbreaks, prompt injections, etc.

1/ NEW: We propose a new black-box attack on LLMs that needs only text (no logits, no extra models). It's generic: we can craft adversarial examples, prompt injections, and jailbreaks using the model itself👇 How? Just ask the model for optimization advice! 🎯
0
6
45
original study here: https://t.co/O4ls45v2jh As far as I can tell, SOTA for SSV2 is around high 70s and for robust CIFAR-10 is low 70s (so all forecasters were overconfident!)

bounded-regret.ghost.io
Earlier this year, my research group commissioned 6 questions [https://prod.hypermind.com/ngdp/en/showcase2/showcase.html?sc=JSAI] for professional forecasters to predict about AI. Broadly speaking,...
0
0
2
In 2021, @JacobSteinhardt's group did a cool forecasting study of ML progress. It's interesting how widely forecasters underestimated progress on MMLU and MATH (which are now saturated), but vastly *overestimated* progress on adversarial robustness and video understanding
4
3
39
The attempt to precisely define and quantify AGI is laudable but I'm skeptical that there's no mention of the robustness or reliability of the AI. Eg this says LLMs already achieve the "math portion" of AGI. But would you let GPT5 handle your finances without supervision?

The term “AGI” is currently a vague, moving goalpost. To ground the discussion, we propose a comprehensive, testable definition of AGI. Using it, we can quantify progress: GPT-4 (2023) was 27% of the way to AGI. GPT-5 (2025) is 58%. Here’s how we define and measure it: 🧵
2
2
62
I teach AI safety, so does that mean I doubly can't? 😅

Those who can, do; those who can’t, get really into AI safety.
2
0
135
Paper: https://t.co/RtfgDN5iFb The main lesson from adversarial ML has not changed in the past decade: the attacker moves *second* and can arbitrarily adapt to the defense This was a cool collab across frontier labs (@OpenAI @AnthropicAI @GoogleDeepMind) @hackaprompt & @ETH_en

arxiv.org
How should we evaluate the robustness of language model defenses? Current defenses against jailbreaks and prompt injections (which aim to prevent an attacker from eliciting harmful knowledge or...
0
2
32
@csitawarin and Milad Nasr designed cool RL-like attacks that basically break all defenses out there. Surprisingly, humans still do much better! We used @hackaprompt to organise a human prompt injection campaign in AgentDojo. No defense stood for longer than a handful prompts
1
1
13
Ok some things did change: 1) people no longer care about adversarial examples, now it's jailbreaks & prompt injections 2) gradient attacks suck for LLMs But the core issue remains: defense evaluations don't try hard enough to break their own defense. What works? RL & humans!
1
2
19
5 years ago, I wrote a paper with @wielandbr @aleks_madry and Nicholas Carlini that showed that most published defenses in adversarial ML (for adversarial examples at the time) failed against properly designed attacks. Has anything changed? Nope...
5
28
184