tomaarsen
@tomaarsen
Followers
4K
Following
4K
Media
311
Statuses
1K
Sentence Transformers, SetFit & NLTK maintainer Machine Learning Engineer at 🤗 Hugging Face
Netherlands
Joined December 2023
‼️Sentence Transformers v5.0 is out! The biggest update yet introduces Sparse Embedding models, encode methods improvements, Router module for asymmetric models & much more. Sparse + Dense = 🔥 hybrid search performance! . Details in 🧵

6
65
479
Big thanks to all of the contributors for helping with the release, many of the features from this release were proposed by others. I have a big list of future potential features that I'd love to add, but I'm unsure what to prioritize now. Exciting times!.
0
0
1
Plus many more smaller features & fixes (crash fixes, compatibility with datasets v4, FIPS compatibility, etc.). 🧵

1
0
0
We've added some documentation on evaluating SentenceTransformer models properly with MTEB. It's rudimentary as the documentation on the MTEB side is already great, but it should get you started. 🧵

1
0
0
If you also upgrade `transformers`, and you install `trackio` with `pip install trackio`, then your experiments will also automatically be tracked locally with trackio. Just open up localhost and have a look at your losses/evals, no logins, no metric uploading. 🧵

1
0
2
When doing multi-GPU training using a loss that has in-batch negatives (e.g. MultipleNegativesRankingLoss), you can now use `gather_across_devices=True` to load in-batch negatives from the other devices too! Essentially a free lunch, pretty big impact potential in my evals. 🧵

1
0
3
There's a new `n-tuple-scores` output format from `mine_hard_negatives`. This new output format is immediately compatible with the MarginMSELoss and SparseMarginMSELoss for training SentenceTransformer, CrossEncoder, and SparseEncoder losses. 🧵

1
0
5
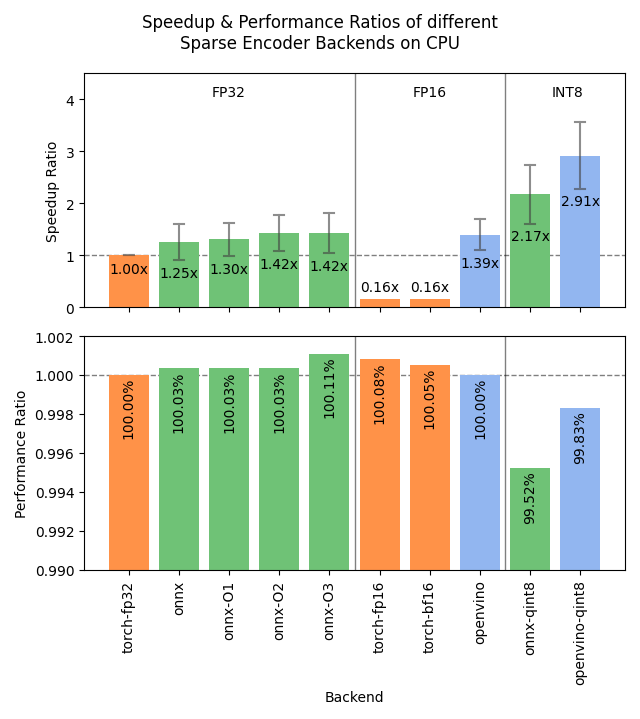
Plus I ran benchmarks for CPUs (see first picture of the thread) and GPUs, averaged across a couple of datasets and batch sizes. 🧵

1
0
1
I added faster ONNX and OpenVINO backends for SparseEncoder models. The usage is as simple as `backend="onnx"` or `backend="openvino"` when initializing a SparseEncoder to get started, but I also included utility functions for optimization, dynamic & static quantization. 🧵

1
0
4
For those who just want the full release notes: Otherwise, keep reading 🧵.

github.com
This release introduces 2 new efficient computing backends for SparseEncoder embedding models: ONNX and OpenVINO + optimization & quantization, allowing for speedups up to 2x-3x; a new "n-...
1
1
6
😎 I just published Sentence Transformers v5.1.0, and it's a big one. 2x-3x speedups of SparseEncoder models via ONNX and/or OpenVINO backends, easier distillation data preparation with hard negatives mining, and more!. See 🧵for the deets:
1
16
131
RT @dylan_ebert_: OpenAI just released GPT-OSS: An Open Source Language Model on Hugging Face. Open source meaning:.💸 Free.🔒 Private.🔧 Cust….
0
37
0
OpenAI is back with open releases on Hugging Face. Check out their latest here:


Our open models are here. Both of them.
0
1
20
Check out SetFit here:

github.com
Efficient few-shot learning with Sentence Transformers - huggingface/setfit
0
0
2

SetFit is still my go-to for classifying anything: it's so much faster and cheaper than LLM-based solutions. I've used this to classify 3k+ texts per seconds: it's so quick it's even viable on CPUs. 🧵

1
0
4
I've just updated SetFit to v1.1.3, bringing compatibility with the recent datasets v4.0+ and Sentence Transformers v5.0+. You'll again be able to train tiny classifiers using very little training data!. 🧵

1
8
75
P.s. I haven't tested this on non-reasoning tasks, I'm not sure how well it holds up on more "standard" retrieval tasks. It looks to be mostly evaluated on BRIGHT (reasoning-intensive retrieval). It's also evaluated on NanoBEIR, but I'm not sure how other models do there.
2
0
2
There's a new, strong multilingual ColBERT model! Trained for English, German, Spanish, French, Italian, Dutch, and Portuguese. I think this'll be my new recommendation for a multilingual Late Interaction/ColBERT model currently.

SauerkrautLM-Multi-Reason-ModernColBERT. Multilingual, reasoning-capable late interaction retriever family. - First ColBERT-style retriever to apply LaserRMT for low-rank approximation .- Distilled from Qwen/Qwen3-32B-AWQ using 200K synthetic query-document pairs, scored by a

2
15
101
RT @lvwerra: Excited to share the preview of the ultra-scale book! . The past few months we worked with a graphic designer to bring the blo….
0
21
0