

Violet X.
@ZiyuX
Followers
189
Following
616
Media
0
Statuses
83
PhD student @Stanford. Working on LLM-based agents
United States
Joined October 2011
RT @rm_rafailov: Missed this paper, but it’s pretty cool - it managed to scale our “Meta-CoT” proposal to 70B models by creating synthetic….
0
9
0
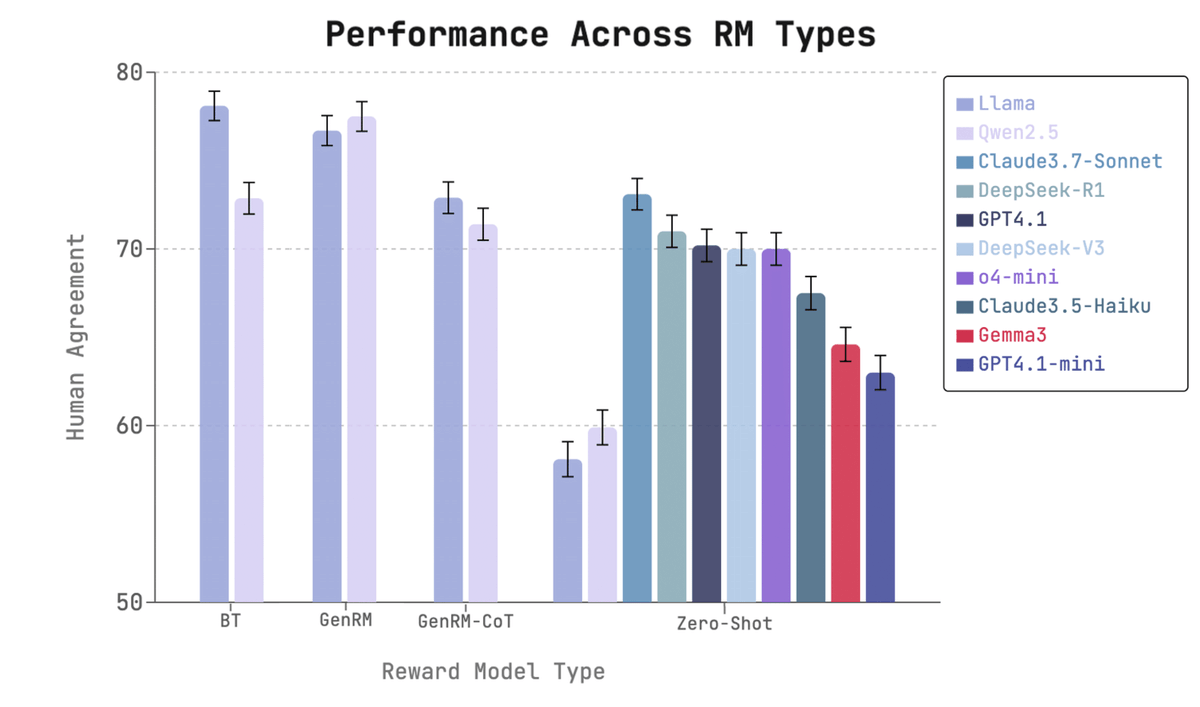
Evaluating creative writing has long been challenging and subjective - how do you standardize taste when judging stories? For details check out our work led by @DanielFein7 @sebbrusso.

Introducing LitBench, the first standardized benchmark for creative writing verifiers! We use Reddit’s r/WritingPrompts to label human preferences across 50k story-pairs, and see how LLM-as-a-judge, Generative RMs, and Bradley-Terry RMs stack up.
0
2
12
RT @RylanSchaeffer: Third #ICML2025 paper! What effect will web-scale synthetic data have on future deep generative models?. Collapse or Th….
0
24
0
RT @synth_labs: Our new method (ALP) monitors solve rates across RL rollouts and applies inverse difficulty penalties during RL training.….
0
9
0
Check out this work on benchmarking how well LLMs can implement ML research papers into code led by @tianyu_hua !.

🚨 New benchmark alert! 🚨. Can today’s LLMs implement tomorrow’s research ideas?. We put them to the test. Introducing #ResearchCodeBench:.212 tasks from 2024–25 ML papers and code, most released after any model’s training cutoff. 🔗 🧵

0
4
8
RT @gandhikanishk: New Paper!! We try to understand why some LMs self-improve their reasoning while others hit a wall. The key? Cognitive b….
0
183
0
RT @rm_rafailov: This is the dataset we curated for our own reasoning experiments. There is a lot of reasoning data coming out now, but we….
0
11
0
RT @synth_labs: Releasing Big-MATH—the first heavily curated & verifiable dataset designed specifically for large-scale RL training & LLM r….
0
16
0
RT @percyliang: 1/🧵How do we know if AI is actually ready for healthcare? We built a benchmark, MedHELM, that tests LMs on real clinical ta….
0
70
0
RT @Anikait_Singh_: Personalization in LLMs is crucial for meeting diverse user needs, yet collecting real-world preferences at scale remai….
0
13
0
RT @AndrewYNg: Introducing Agentic Object Detection!. Given a text prompt like “unripe strawberries” or “Kellogg’s branded cereal” and an i….
0
727
0
RT @jiayi_pirate: We reproduced DeepSeek R1-Zero in the CountDown game, and it just works . Through RL, the 3B base LM develops self-verifi….
0
1K
0
RT @synth_labs: Ever watched someone solve a hard math problem?. Their first attempt is rarely perfect. They sketch ideas, cross things out….
0
42
0
RT @rm_rafailov: "Superintelligence isn't about discovering new things; it's about discovering new ways to discover" -> Meta RL.
0
32
0
RT @rm_rafailov: We have a new position paper on "inference time compute" and what we have been working on in the last few months! We prese….
0
228
0
RT @sunfanyun: Training RL/robot policies requires extensive experience in the target environment, which is often difficult to obtain. How….
0
45
0
Excited about our new paper - Hypothetical Minds! The hypothesis-search-based approach shows a lot of promise in adapting to diverse agents in multi-agent settings. Check out the full paper for more!.

Very excited to release a new paper introducing Hypothetical Minds!. A LLM agent for multi-agent settings that generates hypotheses about other agents' latent states in natural language, adapting to diverse agents across collaborative, competitive, and mixed-motive domains🧵
0
0
6