

Made With ML
@MadeWithML
Followers
10K
Following
598
Media
78
Statuses
649
Learn how to responsibly develop, deploy & manage machine learning. Maintained by @GokuMohandas
Learn machine learning →
Joined May 2019
Excited to share our end-to-end LLM workflows guide that we’ve used to help our industry customers fine-tune and serve OSS LLMs that outperform closed-source models in quality, performance and cost. https://t.co/u9hvVj7E24 1/🧵

anyscale.com
Execute end-to-end LLM workflows to develop & productionize LLMs at scale.
1
45
238

An AI-generated clone of HN built with @nextjs App Router ◆ Uses PPR and streaming Node.js SSR ◆ Fully dynamic, fresh data from Postgres ◆ All the UIs bootstrapped with @v0 ◆ Content via @mistralai 8x7B and @anyscalecompute Tools What I've learned 🧵 https://t.co/HSbl34jzXY

next-ai-news.vercel.app
A version of Hacker News where the stories and comments are 100% generated by LLMs
31
104
903

@rauchg Glad you're finding it useful! Check out our accompanying blog post and the evaluation experiments we ran comparing across a suite of open-source and proprietary LLMs:
anyscale.com
Powered by Ray, Anyscale empowers AI builders to run and scale all ML and AI workloads on any cloud and on-prem.
0
7
31
Very impressed with @anyscalecompute's endpoints, which support tools / function calling. 2LOC to play with Mixtral as a replacement for GPT 🤯
10
28
388
It's been nice to see small jumps in output quality in our RAG applications from chunking experiments, contextual preprocessing, prompt engineering, fine-tuned embeddings, lexical search, reranking, etc. but we just added Mixtral-8x7B-Instruct to the mix and we're seeing a 🤯
12
68
443

The Llama Guard model is now available on Anyscale Endpoints. Get started here: https://t.co/SBYL7T5NQO Example:

At release, Purple Llama includes: - CyberSecEval - Llama Guard model - Tools for insecure code detection & testing for cyber attack compliance We're also publishing two new whitepapers outlining this work. Get Purple Llama ➡️ https://t.co/YSSBNXUiZm
2
21
56
One of the most common asks we get is for public (and reproducible) performance benchmarks. LLM inference performance benchmarks are subtle, and this is a rapidly evolving space, so numbers quickly become stale. But to make comparisons, we need to be talking about the same
4
30
120

The definitive guide to RAG in production! 🙏 @GokuMohandas walks us through implementing RAG from scratch, building a scalable app It now has updated discussion on embedding fine-tuning, re-ranking and effectively routing requests I think this is easily the most complete
12
90
559
We updated our production RAG application guide with a number of new sections: ☑️ When to fine-tune embeddings ☑️ When to augment vector-based retrieval with traditional lexical search ☑️ When to rerank retrieved context ☑️ How to update & reindex as data changes Importantly,

Added some new components (fine-tuning embeddings, lexical search, reranking, etc.) to our production guide for building RAG-based LLM applications. Combination of these yielded significant retrieval and quality score boosts (evals included). Blog: https://t.co/6LUe8Z6DMm
0
12
48
Added some new components (fine-tuning embeddings, lexical search, reranking, etc.) to our production guide for building RAG-based LLM applications. Combination of these yielded significant retrieval and quality score boosts (evals included). Blog: https://t.co/6LUe8Z6DMm
Excited to share our production guide for building RAG-based LLM applications where we bridge the gap between OSS and closed-source LLMs. - 💻 Develop a retrieval augmented generation (RAG) based LLM application from scratch. - 🚀 Scale the major workloads (load, chunk, embed,
7
49
206

I burned in🔥2000$ in finetuning so you don't have to. I fine-tuned models with @OpenAI and @anyscalecompute API endpoints with 50million tokens. Here are the results I wish I knew before getting into finetuning. If you just want a quick snapshot, look at the figure. A longer
30
74
674
Anyscale Endpoints enables AI application developers to easily swap closed models for the Llama 2 models — or use open models along with closed models in the same application.
The team @MetaAI has done a tremendous amount to move the field forward with the Llama models. We're thrilled to collaborate to help grow the Llama ecosystem. https://t.co/1bB64cs1sf
10
28
168
The team @MetaAI has done a tremendous amount to move the field forward with the Llama models. We're thrilled to collaborate to help grow the Llama ecosystem. https://t.co/1bB64cs1sf

anyscale.com
We are excited to announce collaboration between Meta and Anyscale to bolster the Llama ecosystem.
2
17
81

3 free MLOps courses you should know about: ▪️ MLOps Course, @GokuMohandas ▪️ CS 329S: Machine Learning Systems Design @Stanford ▪️ MLOps Zoomcamp @Al_Grigor 🧵
1
74
283

New LLM integration 🔥: @anyscalecompute endpoints allows any developer to easily run + finetune open-source LLMs through an API. Best of all you get the full power of Ray Serve/Train for scalable/efficient training and inference ⚡️ Big s/o to kylehh: https://t.co/5NK1zy35T3
2
10
31

Later this month, Niantic will present at Ray Summit 23 and our own @dreamingleo89 wrote about how we are using Ray to improve multiple aspects of our scanning and mapping infrastructures, and we're just getting started.

nianticlabs.com
Niantic uses Ray for scaling complex distributed workloads
2
5
23
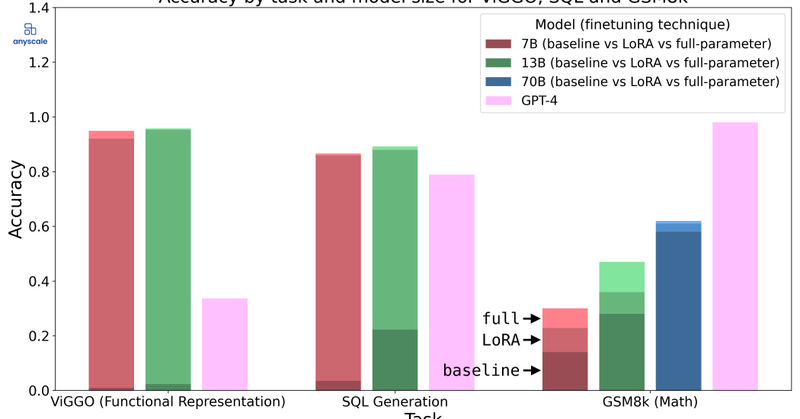
🤔 Fine-tuning LLMs: LoRA or Full-Parameter? Which should you choose? Uncover the insights in our latest technical blog. 🔗 Link: https://t.co/3pvQ9TAksF 🧵 Thread (1/N) 👇
anyscale.com
In this blog, we compare full-parameter fine-tuning with LoRA and answer questions around the strengths and weaknesses of the two techniques.
4
43
204
High signal ML for developers guide! 🙏 Building Machine Learning Applications in real world involves a lot of moving parts and ideas. This series covers all of them really well Made with ML by @GokuMohandas is the best no-nonsense collection of guides with every module
2
22
120
Save cloud costs while keeping quality high with your open source LLM - > Llama 2 is about as factually accurate as GPT-4 for summaries and is 30 times cheaper https://t.co/b3C7gkOajx via @anyscalecompute #ML #AI #ArtificialIntelligence #LLM

anyscale.com
Using Anyscale Endpoints, we compared Llama 2 7b, 13b and 70b vs. OpenAI's GPT-3.5-turbo and GPT-4 for accuracy and cost.
1
4
19
A very comprehensive case study on fine-tuning Llama-2 across three different tasks👇 - code for distributed fine-tuning w/ @raydistributed + @huggingface Accelerate + @MSFTDeepSpeed - data prep + eval + baselines - when to & not to fine-tune - using perplexity for checkpointing

🚀 Exploring Llama-2’s Quality: Can we replace generalist GPT-4 endpoints with specialized OSS models? Dive deep with our technical blogpost to understand the nuances and insights of fine-tuning OSS models. 🔗 https://t.co/zVStDCoG4y 🧵 Thread 1/N👇
1
20
98