

Goku Mohandas
@GokuMohandas
Followers
14K
Following
2K
Media
125
Statuses
958
Excited to share our production guide for building RAG-based LLM applications where we bridge the gap between OSS and closed-source LLMs. - 💻 Develop a retrieval augmented generation (RAG) based LLM application from scratch. - 🚀 Scale the major workloads (load, chunk, embed,
31
262
1K
Read this blog to learn about Composer, Cursor's latest frontier model built with Ray. For the technical deep dive, come to Ray Summit next week!
cursor.com
Composer is our new agent model designed for software engineering intelligence and speed.
2
8
23

Cursor just released a frontier coding model with 4x faster generation. They will be speaking at Ray Summit about their journey building a frontier coding model. - Training on 1000s of GPUs - Scaling 100,000s of sandboxed coding environments - Custom training infrastructure with
8
21
166

Spent three years looking for a team in Biodefense to invest in. But never found one. So we built it ourselves. Valthos builds next-generation biodefense. As AI and biotech rapidly advance, we're approaching near-universal access to tools with the potential to cure humanity or

Valthos builds next-generation biodefense. Of all AI applications, biotechnology has the highest upside and most catastrophic downside. Heroes at the frontlines of biodefense are working every day to protect the world against the worst case. But the pace of biotech is against
71
59
474

We’re excited to welcome Ray to the PyTorch Foundation 👋 @raydistributed is an open source distributed computing framework for #AI workloads, including data processing, model training and inference at scale. By contributing Ray to the @PyTorch Foundation, @anyscalecompute
1
19
107
I'm hiring for a new engineering role working directly with me to support our most sophisticated customers. Looking for someone who wants to work across the AI / AI infra stack, write / debug a ton of code, work directly with customers, move / learn super fast. DM me.
38
37
516
An #OpenSource Stack for #AI Compute: @kubernetesio + @raydistributed + @pytorch + @vllm_project ➡️ This Anyscale blog post by @robertnishihara describes a snapshot of that emerging stack based on experience working with Ray users + case studies from Pinterest, Uber, Roblox, and
4
29
137
You can run this guide entirely for free on Anyscale (no credit card needed). Instructions in the links below: 🔗 Links: - Blog post: https://t.co/u9hvVj7E24 - GitHub repo: https://t.co/Rc0IATcfJ7 - Notebook: https://t.co/G8mVISTXjO
0
3
10
🔄 Swap between multiple LoRA adapters, using the same base model, which allows us to serve a wide variety of use-cases without increasing hardware spend. In addition, we use Serve multiplexing to reduce the number of swaps for LoRA adapters.
1
0
8
🔙 Configure spot instance to on-demand fallback (or vice-versa) for cost savings. All of this workload migration happens without any interruption to service.
1
0
1
🔋 Execute workloads (ex. fine-tuning) with commodity hardware (A10s) instead of waiting for inaccessible resources (H100s) with data/model parallelism (DeepSpeed, FSDP, DDP) and scheduling, fault tolerance, elastic training, etc. from Ray.
1
0
1
Key @anyscalecompute infra capabilities that keeps these workloads efficient and cost-effective: ✨ Automatically provision worker nodes (ex. GPUs) based on our workload's needs. They'll spin up, run the workload and then scale back to zero (only pay for compute when needed).
1
0
1
🚀 Serve our LLMs as a production application that can autoscale up to meet peak demand and scale back down to zero, swap between LoRA adapters, optimize for latency/throughput, etc.
1
0
1
⚖️ Evaluate our fine-tuned LLMs with batch inference using Ray + @vllm_project. Here we apply the LLM (a callable class) across batches of our data and vLLM ensures that our LoRA adapters can be efficiently served on top of our base model.
1
0
3
🛠️ Fine-tune our LLMs (ex. @AIatMeta Llama 3) with full control (LoRA/full parameter, training resources, loss, etc.) and optimizations (data/model parallelism, mixed precision, flash attn, etc.) with distributed training.
1
0
3
🔢 Preprocess our dataset (filter, clean, schema adherence, etc.) with batch data processing using @raydistributed. Ray data helps us apply any python function or callable class on batches of data using any compute we want.
1
0
5
Excited to share our end-to-end LLM workflows guide that we’ve used to help our industry customers fine-tune and serve OSS LLMs that outperform closed-source models in quality, performance and cost. https://t.co/u9hvVj7E24 1/🧵

anyscale.com
Execute end-to-end LLM workflows to develop & productionize LLMs at scale.
1
45
238

I’ve read dozens of articles on building RAG-based LLM Applications, and this one by @GokuMohandas and @pcmoritz from @anyscalecompute is the best by far. If you’re curious about RAG, do yourself a favor by studying this. It will bring you up to speed 🔥 https://t.co/vMsYXZFxvw
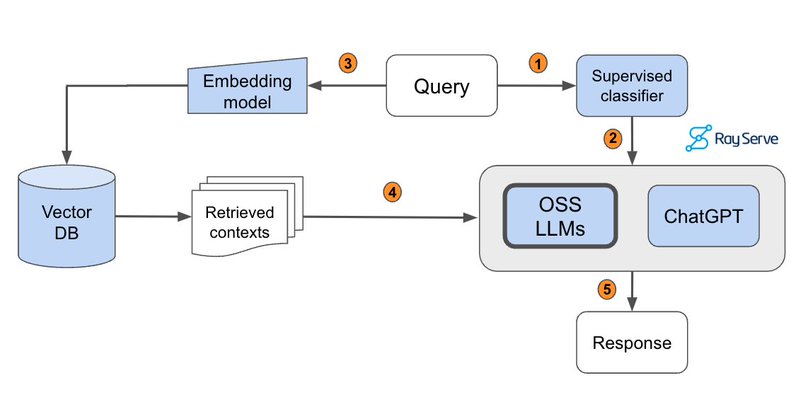
anyscale.com
In this guide, we will learn how to develop and productionize a retrieval augmented generation (RAG) based LLM application, with a focus on scale and evaluation.
6
11
68
It's been nice to see small jumps in output quality in our RAG applications from chunking experiments, contextual preprocessing, prompt engineering, fine-tuned embeddings, lexical search, reranking, etc. but we just added Mixtral-8x7B-Instruct to the mix and we're seeing a 🤯
12
68
443

The definitive guide to RAG in production! 🙏 @GokuMohandas walks us through implementing RAG from scratch, building a scalable app It now has updated discussion on embedding fine-tuning, re-ranking and effectively routing requests I think this is easily the most complete
12
90
559
Added some new components (fine-tuning embeddings, lexical search, reranking, etc.) to our production guide for building RAG-based LLM applications. Combination of these yielded significant retrieval and quality score boosts (evals included). Blog: https://t.co/6LUe8Z6DMm
Excited to share our production guide for building RAG-based LLM applications where we bridge the gap between OSS and closed-source LLMs. - 💻 Develop a retrieval augmented generation (RAG) based LLM application from scratch. - 🚀 Scale the major workloads (load, chunk, embed,
7
49
206