
DeepSpeed
@MSFTDeepSpeed
Followers
3,451
Following
88
Media
14
Statuses
70
Official account for @Microsoft DeepSpeed, a library that enables unprecedented scale and speed for deep learning training + inference. 日本語 : @MSFTDeepSpeedJP
Redmond, WA
Joined May 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#TheKingdomsConcert
• 213610 Tweets
Lakers
• 205204 Tweets
#WWERaw
• 141343 Tweets
Mariners
• 126604 Tweets
Lebron
• 113822 Tweets
Nuggets
• 101487 Tweets
Jamal Murray
• 66490 Tweets
Darvin Ham
• 39058 Tweets
Jokic
• 30986 Tweets
All To Myself D-2
• 30740 Tweets
#TheGrandConcertEnglotinUSA
• 30535 Tweets
Tatum
• 29225 Tweets
Porter
• 28186 Tweets
Derrick White
• 25641 Tweets
Cancun
• 16589 Tweets
Reaves
• 16495 Tweets
KDLEX CONCERT TIX RELEASED
• 13645 Tweets
風呂キャンセル界隈
• 13328 Tweets
桂由美さん
• 12837 Tweets
Freya
• 12619 Tweets
Vando
• 12599 Tweets
無料10連
• 12267 Tweets
Hayes
• 12074 Tweets
渡航費用12.6億円
• 10786 Tweets
政務三役31人
• 10335 Tweets



















Pinned Tweet

Introducing Mixtral, Phi2, Falcon, and Qwen support in
#DeepSpeed
-FastGen!
- Up to 2.5x faster LLM inference
- Optimized SplitFuse and token sampling
- Exciting new features like RESTful API and more!
For more details:
#DeepSpeeed
#AI

10
90
429
Introducing DeepSpeed-FastGen 🚀
Serve LLMs and generative AI models with
- 2.3x higher throughput
- 2x lower average latency
- 4x lower tail latency
w. Dynamic SplitFuse batching
Auto TP, load balancing w. perfect linear scaling, plus easy-to-use API

6
122
561
Want to train 10B+ ChatGPT-style models on a single GPU and 100B+ on multi-GPUs systems? Introducing DeepSpeed-Chat, an easy (single script), fast, and low-cost solution for training high-quality ChatGPT-style models with RLHF, 15x faster than SoTA.
Blog:

13
139
458
DeepSpeed-Chat aims to provide a highly efficient pipeline to help you explore RLHF training. Towards this aim we are releasing training logs and our experiences in a new tutorial:
(🧵 thread 1/3)
3
73
324
🚀 Announcing DeepSpeed ZeRO-Offload++
-6x Higher Training Throughput via Collaborative CPU/GPU Twin-Flow 🔥
-Systematic optimizations at no data precision loss
-Performance gain maintains for both single and multi-node cases

8
65
303
DeepSpeed v0.10.0 release! Includes our ZeRO++ release, H100 support, and many bug fixes/updates. Special thanks to our wonderful community of contributors!
ZeRO++ paper:
ZeRO++ blog:
v0.10.0 details:

1
69
259
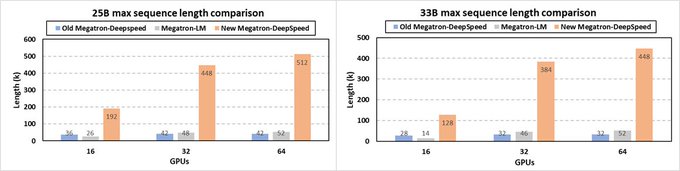
We recently finished a long-awaited sync between microsoft/Megatron-DeepSpeed and NVIDIA/Megatron-LM 🚀🚀🚀
This resulted in a ~10% throughput gain, together with support for FlashAttention (both 1 and 2) and Rotary Positional Embedding (RoPE)!
Details:

1
36
190
🚀Exciting new updates on
#DeepSpeed
ZeRO-Inference with 20X faster generation!
- 4x lesser memory usage through 4-bit weight quantization with no code change needed.
- 4x larger batch sizes through KV cache offloading.
Available in DeepSpeed v0.10.3:

3
30
174
Want to train 1 million token context lengths (all 7 of the Harry Potter books!📚) on a GPT-like model w. 64 GPUs?
Announcing DeepSpeed-Ulysses🚀
This release enables highly efficient and scalable LLM training with extremely long sequence lengths🤯

1
41
146
🚀Introducing
#DeepSpeed
-VisualChat! 🖼📜
- Multi-image, multi-round
#dialogues
- Novel
#MultiModal
causal attention
- Enriched training data via improved blending techniques
- Unmatched
#scalability
(>70B params)
Blog:
Paper:

2
40
142
We've released v0.9.0 to pypi that includes support for DeepSpeed Chat. You can now `pip install deepspeed` for all your RLHF needs 🚀🚀
v0.9.0 also includes several bug fixes (eg Stable Diffusion fixes) and updates (eg dropping torch 1.8 support)

1
26
107
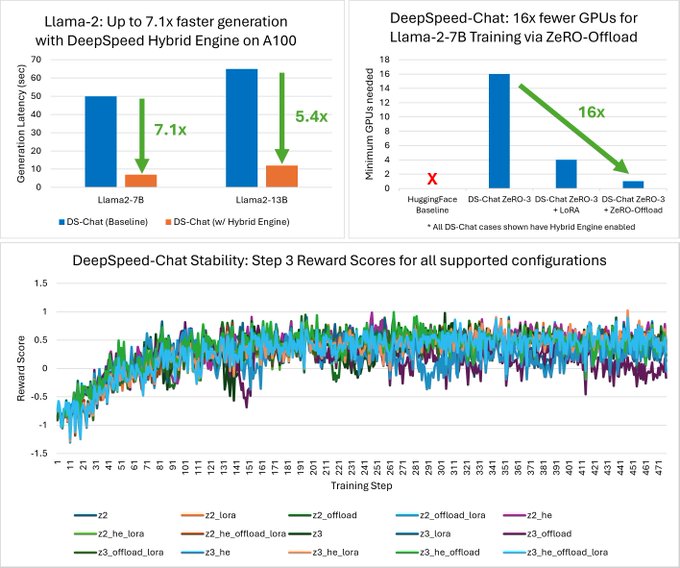
🚀 Exciting Updates for
#DeepSpeedChat
! 🤖
- Llama-2 Support: Enjoy 7.1x faster generation with DeepSpeed Hybrid Engine!
- Improved efficiency and accessibility through MixZ++ and ZeRO-Offload.
- Improved stability and software enhancements.
Blog:
3
19
100
🚀 Excited to announce our paper "ZeRO++: Extremely Efficient Collective Communication for Large Model Training" has been accepted at
#ICLR2024
!
🔍 ZeRO++ significantly reduces communication volume by 4x, achieving up to 3.3x speedup.
#DeepSpeed
#AI

3
20
100
DeepSpeed v0.9.2 release! Includes several bug fixes and added features across both ZeRO and HybridEngine (HE) used w. DS-Chat (see release notes)
Inference support for accelerating LLaMA coming in v0.9.3 :) For early access watch our main branch!

1
12
60
Announcing DeepSpeed4Science 🚀
We are building unique capabilities through AI system technologies to help domain experts solve society's most pressing science challenges, from drug design to renewable energy.
MSR Blog:
Website:

0
10
38
We're excited to see the community has started to upload DeepSpeed Chat checkpoints to
@huggingface
!
@amjeeek
has uploaded all model checkpoints from step 1, 2, 3 for OPT-1.3B along with his experience and training logs:


Very excited to train my first chat-style model using DeepSpeed-Chat 😀🎀🎀
@MSFTDeepSpeed
.
(🔖thread 1/2)
1
0
8
1
6
30
DeepSpeed +
@berkeley_ai
explore the effectiveness of MoE in scaling vision-language models, demonstrating its potential to achieve state-of-the-art performance on a range of benchmarks over dense models w. equivalent compute costs.
More coming soon!

0
11
30
Scaling Large-Scale Generative Mixture-of-Expert Multimodal Model With VL-MoE
Do you want to scale up your vision and language models? Take a look at our blog for details!

DeepSpeed +
@berkeley_ai
explore the effectiveness of MoE in scaling vision-language models, demonstrating its potential to achieve state-of-the-art performance on a range of benchmarks over dense models w. equivalent compute costs.
More coming soon!
0
11
30
0
7
16
DeepSpeed v0.9.1 release! Includes a handful of bug fixes related to HF integration, OPT/GPTJ models, pre-compilation ops, etc.

1
4
15
Ammar (
@ammar_awan
) from the DeepSpeed team will be visiting
@kaust_corelabs
to share our latest features and how it enables trillion-parameter scale model training and inference for everyone!

The
@cemseKAUST
division and
@KAUST_News
Supercomputing Core Lab are hosting a talk on the usage of the
@Microsoft
DeepSpeed library on supercomputers.
While this event is hosted on campus, attendees outside of KAUST are warmly welcome to join virtually.
Details below!

1
10
14
0
6
15
Full house at the hands-on session diving into our HelloDeepSpeed example (). Everyone was super excited to see how ZeRO allowed them to magically train models that previously OOM'd!


0
3
10
DeepSpeed v0.8.2 release! 15 contributors w. 6 new contributors just in the last 2 weeks since our previous patch release!

0
3
10
Highlight 2:
Scientists can now train their large science models like Argonne's GenSLM COVID models with very long sequences
- 2X higher training throughput 🚀
- 13X longer sequence lengths achieved compared to SOTA training frameworks like Megatron-LM
Announcing DeepSpeed4Science 🚀
We are building unique capabilities through AI system technologies to help domain experts solve society's most pressing science challenges, from drug design to renewable energy.
MSR Blog:
Website:
0
10
38
0
4
10
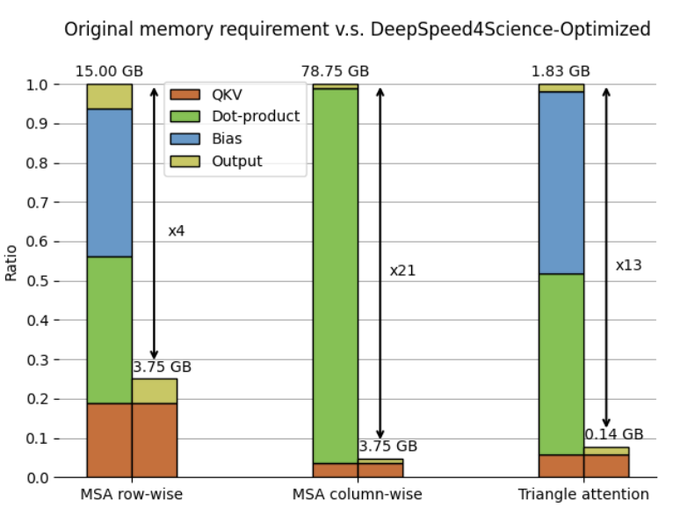
Highlight 1:
Eliminating memory explosion problems for scaling Evoformer-centric structural biology models🧬
Today we’re releasing a set of highly memory-efficient Evoformer attention kernels that reduces peak memory for training and inference by 13x!🚀
Announcing DeepSpeed4Science 🚀
We are building unique capabilities through AI system technologies to help domain experts solve society's most pressing science challenges, from drug design to renewable energy.
MSR Blog:
Website:
0
10
38
1
2
10
2/3 RLHF training is an active field, we welcome contributions to explore this new direction together. You can find our corresponding training recipe scripts and logs for our OPT-1.3B actor + OPT-350M critic run:
1
0
8
3/3 Keep an eye on this space, we will be actively pushing out more features (e.g., LLaMA) and fixes very soon! 🚀
1
0
6
We have created another twitter account for our DeepSpeed 日本語 users!

従来の英語のアカウント
@MSFTDeepSpeed
に加えて、日本語でDeepSpeedの情報を発信することになりました。
新機能や論文の情報を掲載していく予定ですので、フォローよろしくお願いします。
0
1
5
0
1
5
Microsoft DeepSpeed open-source technologies empower researchers in Japan to train a SOTA Japanese LLM, an effort lead by National Institute of Informatics (NII), universities, and companies aiming to continuously develop publicly available Japanese LLM.

✎ニュースリリース
130億パラメータの大規模言語モデル「LLM-jp-13B」を構築
~NII主宰LLM勉強会(LLM-jp)の初期の成果をアカデミアや産業界の研究開発に資するために公開~
大学共同利用機関法人 情報・システム研究機構 国立情報学研究所(NII、所長:黒橋…
0
142
426
0
1
4

@eshamanideep
Keep an eye out for updates, we're planning to release these and other follow-ups in the near future.
0
0
2