

Jonathan Chang
@ChangJonathanC
Followers
2K
Following
16K
Media
566
Statuses
2K
ML/AI Engineer, building https://t.co/uEbfxzF7jm
Taiwan
Joined May 2020
while we wait for gpt-5 to drop. Here is a flex attention tutorial for building a < 1000 LoC vllm from scratch https://t.co/PVyauMezM3
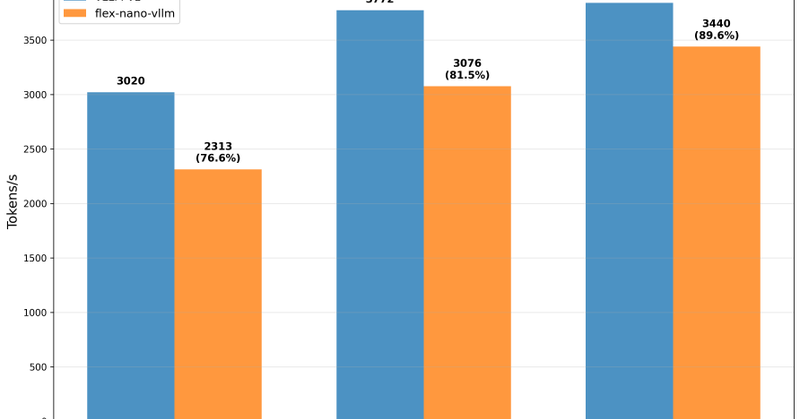
jonathanc.net
PyTorch FlexAttention tutorial: Building a minimal vLLM-style inference engine from scratch with paged attention
9
37
412
apparently agent skill is a thing now
Voyager from 2023 is one of my favorite paper. Now you can implement the skill library with 200 LoC, and bring it to Claude Code check out Voyager MCP: https://t.co/mwsUFNdD90
0
0
0
judge model only see one response and give the reward they're frozen, they don't feel the slop can we fix slop by giving the judge model more independent samples in the context?
0
0
0

How long have you been "planning to understand" how modern LLM inference works? We just gave you a readable version of SGLang you can finish over the weekend. Introducing mini-SGLang ⚡ We distilled SGLang from 300K into 5,000 lines. Kept the core design, cut the complexity.
29
171
1K
i wrote about how to safely run claude code with --dangerously-skip-permissions https://t.co/tX6QKsPLDr
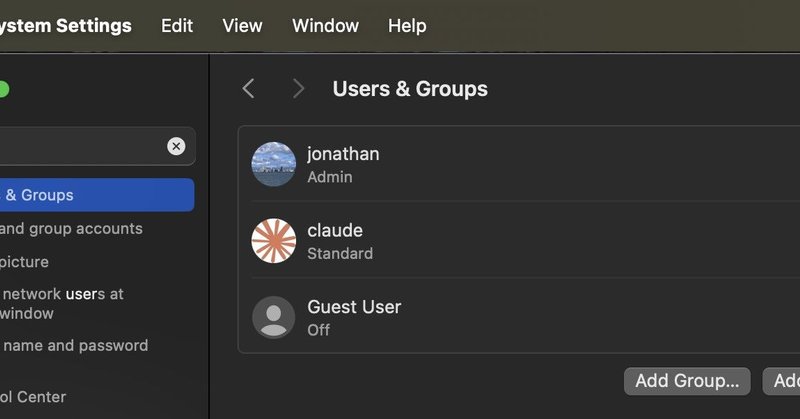
jonathanc.net
Running Claude Code in yolo mode safely using macOS user isolation and ACLs
0
0
1
here is the first of several updates. i will follow up with a detailed post but i wanted to give a preview to anyone who was interested in just reading / seeing the code https://t.co/iq6HliTSzS
github.com
MoE training for Me and You and maybe other people - GitHub - Noumena-Network/nmoe: MoE training for Me and You and maybe other people

# Why Training MoEs is So Hard recently, i have found myself wanting a small, research focused training repo that i can do small experiments on quickly and easily. these experiments range from trying out new attention architectures (MLA, SWA, NSA, KDA - all pluggable) to
14
28
338
wow

🔉 Introducing SAM Audio, the first unified model that isolates any sound from complex audio mixtures using text, visual, or span prompts. We’re sharing SAM Audio with the community, along with a perception encoder model, benchmarks and research papers, to empower others to
0
0
0
really really love this kind of ablation 1) with/without openai learnable sink => it's better with sink by quite a lot (~4 points on MMLU/BBH) 2) swa size 128 vs 512 => 128 seems to perform better after post-training on long-context tasks 3) hybrid swa vs all global attention

wow, this looks like a very solid open model by Xiaomi, competing with K2/DSV3.2 on benchmarks with fewer parameters. it's MIT licensed, with a very good tech report and base/thinking versions available it's using the same sliding window attention arch as gpt-oss (sink with SWA
7
9
146
Claude code can't replace human engineer yet because when host runs out of disk space Claude just dies
0
0
1
TIL: haiku is now smart enough to be used as subagent in claude code
0
0
1

what's the least annoying way to idiot proof `--dangerously-skip-permissions` for claude code projects on my local machine? docker?
0
0
3
Uses multiple sota models, doesn't specify cost vs performance 2.3% "jump" over sota model

Zoom achieved a new state-of-the-art (SOTA) result on Humanity’s Last Exam (HLE): 48.1% — outperforming other AI models with a 2.3% jump over the previous SOTA. ✨ HLE is one of the most rigorous tests in AI, built to measure real expert-level knowledge and deep reasoning across
0
0
1
my chatgpt stats: 2022: 0.67 messages/day 2023: 4.65 messages/day 2024: 18.64 messages/day 2025: 40.52 messages/day
0
0
5
CDG airport border control is so slow for non eu passports the queue is barely moving
0
0
1
It's surprising that qwen 3 VL instruct yap so much ( I just tried it on hf chat), while there's a separate -reasoning variant But it can definitely be prompted to only output the answer, so imo this eval can be done better to reflect actual usage.

The world’s best small models—Ministral 3 (14B, 8B, 3B), each released with base, instruct and reasoning versions.
0
0
1