

Dante Camuto
@CamutoDante
Followers
986
Following
1,461
Media
42
Statuses
324
Explore trending content on Musk Viewer
#WeAreSeriesEP7
• 370196 Tweets
Robert Fico
• 134239 Tweets
PondPhuwin WeAre EP7
• 121394 Tweets
Peru
• 92121 Tweets
Slovakia
• 89599 Tweets
Wicked
• 68307 Tweets
サーティワン
• 49194 Tweets
Accendio
• 44106 Tweets
キダ・タローさん
• 43958 Tweets
#JO1ANNX
• 39778 Tweets
NAYEON NA TRACKLIST
• 34786 Tweets
#BillkinPPKrit1stConcert
• 28768 Tweets
浪花のモーツァルト
• 24101 Tweets
スロバキア
• 22269 Tweets
Eslovaquia
• 21174 Tweets
Ludmilla
• 15655 Tweets
Ubisoft
• 15493 Tweets
Yasuke
• 15416 Tweets
DANIEL CAESAR
• 12654 Tweets
リリムハーロット
• 11416 Tweets
Ivete
• 10791 Tweets
Handlova
• 10709 Tweets
最高顧問
• 10137 Tweets




















Pinned Tweet

Hello ML friends. Over the past few months I've been working on EZKL in collaboration with
@jasonmorton
with support from
@0xPARC
.
This library enables anyone to convert a pytorch or tensorflow computational graph into a ZK-SNARK.
github:

7
36
154
Some of y'all have been messaging us at 4am begging for tree based models in ezkl.
well ... we HEARD U.
you can now convert sklearn tree based models and XGBoost models into zk-circuits.
time to start planting trees on-chain.
writeup + jupyter nb:

3
15
66
Been working my way through
@SuccinctJT
's book on ZKPs. To help grok some of the early chapters, I've created a non-interactive version of the GKR protocol in rust. It's a little bit unpolished atm but if anyone wants to help expand it hmu :)
repo:
2
5
51
@BiancaGanescu
,
@jasonmorton
and I have a short technical primer on how we managed to get nanoGPT models into a ZK-SNARK: … .
It involves 3 main innovations
2
11
35
ok ok ok so a year in we decided it was high time we get a twitter, and a blog, and ... finally introduce ourselves

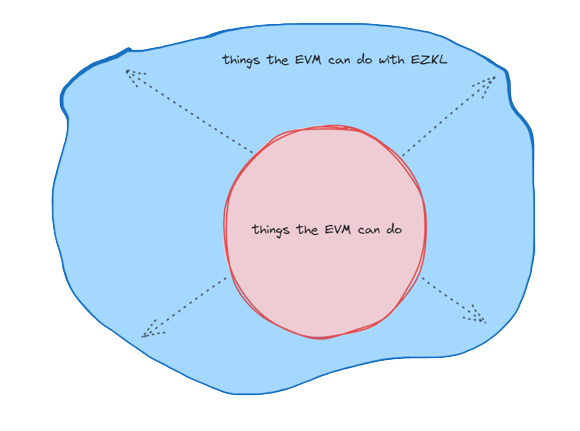
1/ We're excited to properly introduce EZKL!📖
Our mission is to extend the computational limits of the EVM, empowering you to bring complex operations on-chain.
Read our full post here:
17
44
208
4
0
26
Check out our latest AISTATS paper where we develop theory to understand the adversarial robustness of VAEs.
@tom_rainforth
@cholmesuk
@MatthewWilletts
paper:
tldr:

1
10
23
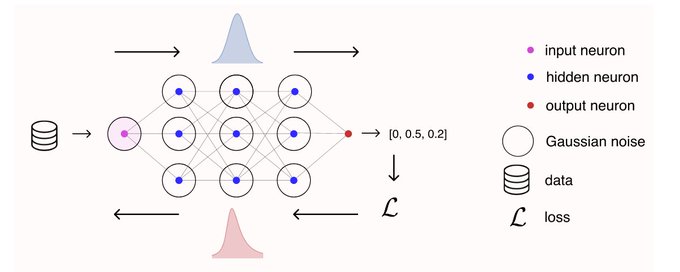
Every wondered why adding Gaussian noise to data and network activations regularises neural networks ?
Find out in our latest Neurips paper
@MatthewWilletts
@umutsimsekli
@cholmesuk
.
tldr:
paper:
code:
1
8
20
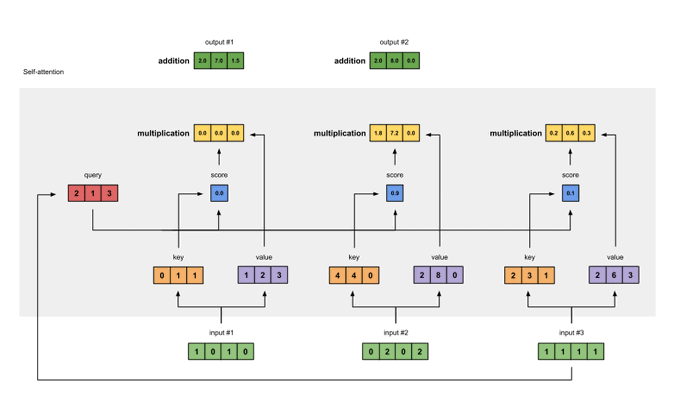
Did someone say self-attention blocks and nanoGPT inside a ZK-SNARK ?
link:
benchmarks:
other homies on the job:
@BiancaGanescu
1
7
19
Proud to present my latest paper with my amazing collaborators
@umutsimsekli
@MGurbuzbalaban
@cholmesuk
Xiaoyu Wang Lingjiong Zhu.
We show that Gaussian noise injections (GNIs), added to data or neural network activations, induce bias in SGD !
paper:
3
3
18
Thanks to
@cholmesuk
,
@umutsimsekli
,
@tom_rainforth
,
@BenNeuber
,
@MGurbuzbalaban
, longtime collaborator
@MatthewWilletts
and many others for helping me get here

5
0
19
watched the latest top gun on silent with turkish subtitles and
@mmmmalibu
‘s album playing in the background as a soundtrack. beautiful
0
1
17


hyped to showcase some game design patterns that leverage zkml :)

✶ We’re thrilled to reveal more speakers at the Autonomous Worlds Assembly:
- Kara Kittel
@karakittel
- Small Brain Dev
@0xsmallbrain
- GVN
@GVN908
- Dante
@CamutoDante
2
10
49
0
3
11
Thanks to
@DCbuild3r
@lancendavis
@alluri_c137
@weijie_eth
@henlojseam
@therealyingtong
and a bunch of others for their help and support in developing this.
1
0
11
@MatthewWilletts
and I have noticed that a bunch of recent papers show that old neural network architectures can outperform SOTA nets if their hyper-params are tuned properly.
We've collected them here:
Curious to hear about other papers we should add.

0
3
12
Super excited about my latest work with
@MatthewWilletts
where we study Variational Autoencoders using harmonic analysis.
arxiv:
1/n
2
4
10
@noampomsky
This happened to me on acid. Was hiking through the woods and saw trail runners cruising up and down the mountain. Really inspired me
0
0
9
Shoutout to the homies at the
@turinginst
for fostering my collaborations with some of the brightest minds in ML. Sadly my time there is coming to an end but anyone that is doing / thinking of doing a PhD in ML should look into their programs.
0
1
10
Protect your precious Variational Autoencoders from adversarial attack using our latest ICLR paper.
@MatthewWilletts
@tom_rainforth
@cholmesuk
arxiv:
1
4
9
ezkl repo:
shoutouts to everyone that made this possible:
@jasonmorton
@jseam
@ethan_t_c_
and
@CurrentHandle
0
0
9
What does this enable you to do ? Well you can now provide proofs for statements such as:
"I ran this publicly available neural network on some private data and it produced this output"
"I ran my private neural network on some public data and it produced this output"
2
1
8
Wherein I argue that Big Tech's dominance of AI research will prove to be strategically disastrous for the West.
0
5
8

Fantastic morning news — our work got into ICML.
Some shameless advertisement will follow shortly.
Ft.
@umutsimsekli
@MGurbuzbalaban
@cholmesuk
Lingjiong Zhu and Xiaoyu Wang
Proud to present my latest paper with my amazing collaborators
@umutsimsekli
@MGurbuzbalaban
@cholmesuk
Xiaoyu Wang Lingjiong Zhu.
We show that Gaussian noise injections (GNIs), added to data or neural network activations, induce bias in SGD !
paper:
3
3
18
0
1
7
Every village has two old dudes on a bench hashing out the world’s most pressing problems.
0
1
6
Thanks to
@CPerezz19
,
@henlojseam
,
@lancendavis
,
@therealyingtong
,
@kalizoy
, Jonathan Passerat-Palmbach for help and camaraderie in getting this through.
1
0
7

Why has reviewing for ML conferences started to feel like jury duty ?
0
0
6
or even:
"I correctly ran this publicly available neural network on some public data and it produced this output".
This library has had some adoption in the cryptography space but I'd be curious to hear from ML folks on what they think of the library / functionality :)
1
1
6
wanted to showcase an engineering trick that we’ve been using internally to lower the cost of pre-committing to values. Instead of using expensive to prove hashing functions, we just re-use some of the commitments that are generated when proving with Halo2.
💸 Zero Additional Cost Commitments in Halo2
For our friends interested in ZKP/ ZKML, we discuss why proofs often use hash functions and a neat trick for eliminating their overhead cost.
Read the full post here:
Or keep reading for a brief analogy 👇
1
8
40
1
0
6
The two worst things for your posture are your phone and spaghetti
0
0
5
Overheard a marketing meeting. They were talking about how the insta algorithm operates and how they can alter content to « please » it. So weird that whole groups of folks are trying to decipher an algo like its some sort of scripture from God.
1
0
4
1. Dynamic circuit sizes such that we can fit very large models even for small trusted setups.
If a model is larger than a halo2 column - we just add more columns !
1
0
4
When adding GNIs to network activatications, perhaps counter-intuitively, the forward pass experiences Gaussian noise but gradient updates in the backward pass experience heavy-tailed asymmetric noise !
1
1
3
3. We modified halo2’s permutation argument construction to allow for copy constraints to be created in parallel. This allows us to layout circuits much more quickly and our key generation phases are more memory efficient.
1
0
4
We gain insights into which characteristics of a VAE contribute to robustness, with the encoder variance and encoder Jacobian playing prominent roles. We find that commonly used disentangling methods, like the β-VAE, control both these parameters and create more robust models.
0
1
4

Why are the people most worried about AGI pouring billions of $ into making it happen?
1
0
3
if you listen closely it’s there. it’s everywhere. TiNniTus !
0
1
3
We model the dynamics of SGD+GNIs by an SDE driven by an asymmetric heavy-tailed α-stable noise. The stationary distribution of this process can shift away from the true local minima of the loss function when the noise is asymmetric (high theta - black is o.g loss function):
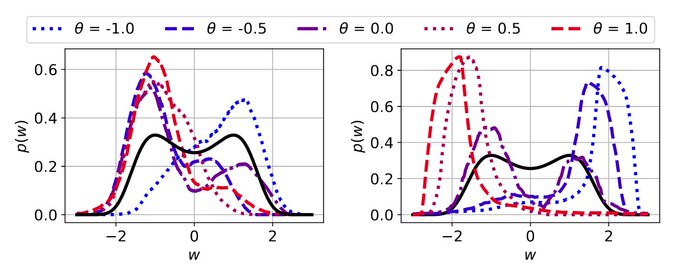
1
0
3
our art department is on overdrive
1/🛡️Building Verifiable Computation
We discuss our experiments around proof-carrying data, an approach for achieving verifiable computation. Our first experiment reimagines the Zupass PCD manager with EZKL-compiled PCDs, with more to come.

4
13
89
1
0
4
here's how to never stop never stopping in halo2
♾Splitting and Parallelizing Proofs in EZKL
In the first thread on optimizing proof generation, we discussed KZG commitments at zero additional cost in Halo2.
Now we discuss leveraging these commitments to split and parallelize proofs.
2
8
31
0
0
4
To ground this a bit more, this can enable:
- proving that an image was generated by a specific generative model.
- proving performance on a test set without revealing the model parameters.
- prove inference on edge devices without sending data to servers !
0
0
4

Thanks
@VirtualElena
for the writeup on EZKL and other proving frameworks :)
Blockchains have incentivized zero-knowledge proof research, creating modern proving systems w/ smaller memory footprints and faster proving & verification times — making it possible to verify certain small machine learning algorithms on-chain.
14
123
440
0
0
4
first day of the year and there’s a guy at the gym roundhouse kicking every wall. Be the change you want to see in the world
0
0
3
everything was going according to plan until mike tyson punched me in the face
0
0
3
@Shoelim8
@umutsimsekli
@MGurbuzbalaban
@cholmesuk
Super cool. We also find that the noise on gradients promotes NN to land in wider minima (see metastability analysis in the paper) but the potential benefits of this are far outweighed by the induced bias. Would be really curious to see if an RNN structure lessens this bias.
0
0
2

Wonder if gpt will end up like the concorde. Takes us leaps and bounds forward but so expensive to keep running we eventually get rugged
0
0
3
@miniapeur
I felt the same way last summer in London actually. Ended up taking a camera out and walking from morning to evening taking pictures / reading and eating at whatever places I stumbled upon.
1
0
3



@YondonFu
@jasonmorton
@0xPARC
We recently go up to 100mil parameters using 500-600GB of RAM. Theoretically could push further with some larger machines :) Upper limit currently depends on the operations that constitute the computational graph (some ops use more constraints than others).
1
0
3

2. We use
@kalizoy
´s tract library to reduce most linear operations to einsum operations.
Our codebase is pretty small as only need to create constraints/arguments for two operations: einsum and nonlinearities (which we express using lookups).
1
0
3
@bneyshabur
Honestly for me it was mainly a fun experience where the stakes were very low and I got time and funding to explore new things. I’d be reluctant to prescribe an excessively utilitarian bent to it.
0
0
3
@singareddynm
@tsuname
@draparente
@kulesatony
Bayesian optimisation seems like a good fit for this. Given sets of of old experiments the algo can suggest new experiment parameters that a) it thinks will perform better under some metric or b) parameters that reduce its uncertainty of how the experiments work(more exploratory)
0
0
3
Does anyone want 3 tickets for an A.G Cook gig in central london tonight ?
3
0
3
We show that our theory models the effects of GNIs on SGD and we show that networks that experience GNIs without gradient noise outperform models experiencing GNIs with their full gradient noise.
0
0
1
Definitely the smartest folks in defi

Join us on our journey as we exit stealth mode! We will be posting research articles roughly once a week.
The first article is our unveiling of our new way of looking at dynamic AMMs—Temporal Function Market Making. Next week we will be looking at other next generation AMM
6
32
359
0
0
2
why is the most beautiful song ever made called In McDonalds
0
0
2

check out my burgundy terminal folks
0
0
2
People are worried about paperclip maximizers when we’re already paperclips
1
0
2
We confirm empirically that increasing the encoder variance and the variance of noise on data improves VAE robustness to adversarial attack by way of smaller network Lipschitz constants.
7/n
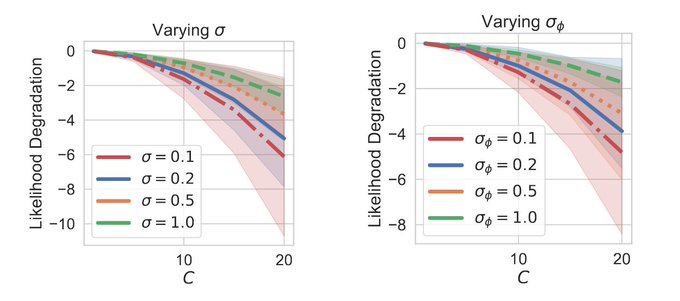
0
0
2
@BlackHC
@LangChainAI
@OpenAI
Love the package ! Do you think there’s a risk we start to become so disassociated from our labour / hand off sufficient responsibility to LLMs that we no longer understand the products we’re building and how they function ?
1
0
2

@johnnysands42
@neirenoir
@max_paperclips
@hcaulfield8148
@marcfawzi
Hey all 👋🏼 we have a few benchmarks for performing inference w/ nanoGPT here . I would note that IF you wanted to you could use the library to prove you’ve achieved a certain performance on a publicly available test set as well :)
1
1
2

To underpin this theory, we develop a simple and flexible criterion for robustness in probabilistic models : r-robustness. We find that models that perform well under this metric are less likely to degrade in performance when attacked !
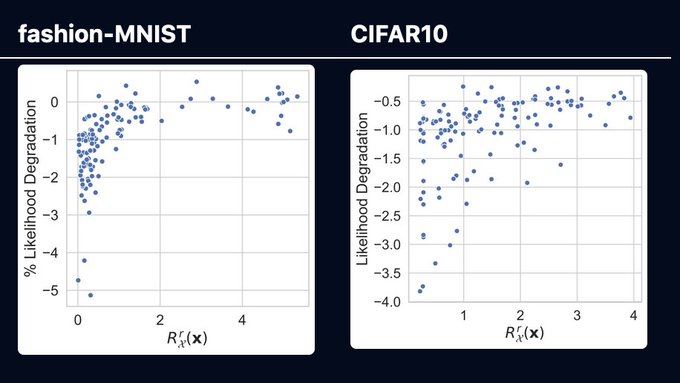
1
0
2

@kobigurk
@thefrozenfire
We should get a bunch of LLMs arguing over dinner about the validity of transactions
2
0
2