

Vincent Qin
@AlphaRealcat
Followers
365
Following
6K
Media
81
Statuses
1K
⭐️Focusing on Visual Localization, SfM and SLAM.
Joined March 2022

RT @kwangmoo_yi: Ost, Ramazzina, and Joshi et al., "LSD-3D: Large-Scale 3D Driving Scene Generation with Geometry Grounding". Use a pretrai….
0
16
0
RT @zhenjun_zhao: SAIL-Recon: Large SfM by Augmenting Scene Regression with Localization. Junyuan Deng, Heng Li, Tao Xie, Weiqiang Ren, Qia….
0
7
0
RT @cosminnegruseri: My favorite deep learning intuition is that neural net layers are a series of geometric transforms .
0
270
0
RT @NielsRogge: Exciting model addition to @huggingface Transformers: MatchAnything is now available! 🔥. A strong universal image matching….
0
89
0
Code: Project:
4dnex.github.io
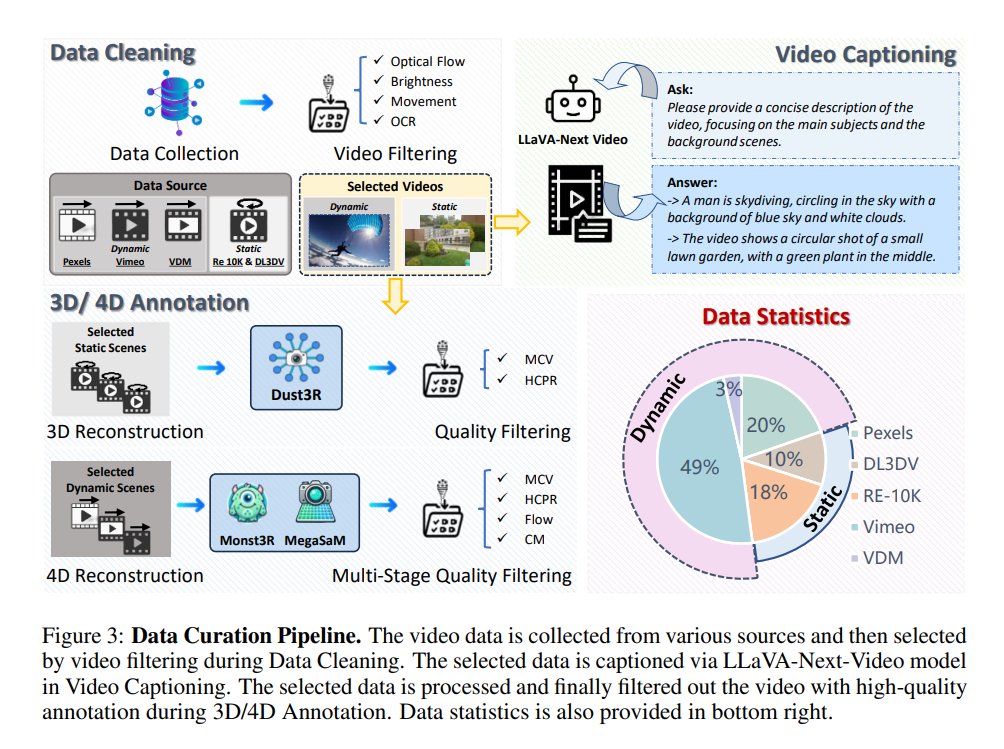
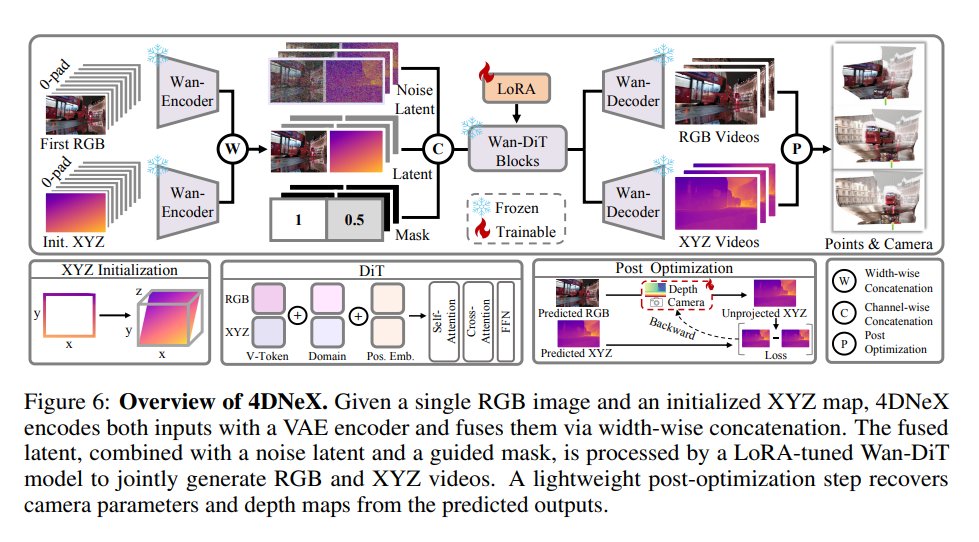
4DNeX: Feed-Forward 4D Generative Modeling Made Easy.

4DNeX: Feed-Forward 4D Generative Modeling Made Easy. @Frozen_Burning, @TianqiLiu664, Long Zhuo, @jiawei6_ren, @zengtao197, He Zhu, @hongfz16, @pldeqiushui, @liuziwei7. tl;dr: 4D dataset; feed-forward framework for generating 4D scene representations from a single image by


0
2
10
RT @zhenjun_zhao: G-CUT3R: Guided 3D Reconstruction with Camera and Depth Prior Integration. Ramil Khafizov, Artem Komarichev, @rusrakhimov….
0
9
0
RT @taubnerfelix: 🚨 Code Release for CAP4D🧢.Excited to share that we have released the inference code and weights for CAP4D!.Visit https://….
0
64
0
RT @BaldassarreFe: 🎁DINOv3 is open source!. 💻 Training+evaluation code, adapters and notebooks: 🤗 Collection of pre….
ai.meta.com
DINOv3 scales self-supervised learning for images to create universal vision backbones that achieve absolute state-of-the-art performance across diverse domains, including web and satellite imagery.
0
15
0
RT @BaldassarreFe: Say hello to DINOv3 🦖🦖🦖. A major release that raises the bar of self-supervised vision foundation models. With stunning….
0
277
0
Code: Project:

github.com
[RA-L 2025] FrontierNet: Learning Visual Cues to Explore - cvg/FrontierNet

FrontierNet: Learning Visual Cues to Explore. Boyang Sun, Hanzhi Chen, @StefanLeuteneg1Cesar Cadena, @mapo1 @hermannsblum. tl;dr: predict frontier (where we weren't yet) using RGBD and then make a map, and not otherwise.




0
1
2
RT @thedroneforge: < GEVO: 94x Memory Reduction in 3D Vision >. Recent 3D mapping techniques like Gaussian Splatting create stunningly real….
0
18
0
RT @liuyuehcheng: We will present QuickSplat at #ICCV2025! 🎉. Data-driven 2DGS initialization and densification makes 3D surface reconstruc….

arxiv.org
Surface reconstruction is fundamental to computer vision and graphics, enabling applications in 3D modeling, mixed reality, robotics, and more. Existing approaches based on volumetric rendering...
0
17
0
RT @janusch_patas: Evaluating Fisheye-Compatible 3D Gaussian Splatting Methods on Real Images Beyond 180 Degree Field of View. Contribution….
0
13
0
RT @heysehajsingh: this was based on the brilliant textbook:. "Foundations of Large Language Models" by Tong Xiao and Jingbo Zhu (NiuTrans….
arxiv.org
This is a book about large language models. As indicated by the title, it primarily focuses on foundational concepts rather than comprehensive coverage of all cutting-edge technologies. The book...
0
8
0
RT @ducha_aiki: VLM-Guided Visual Place Recognition for Planet-Scale Geo-Localization. Sania Waheed, Na Min An, @maththrills , Sarvapali D.….
0
13
0
Code:

github.com
Contribute to JiajunLe/GeoMoE development by creating an account on GitHub.
GeoMoE: Divide-and-Conquer Motion Field Modeling with Mixture-of-Experts for Two-View Geometry. Jiajun Le, Jiayi Ma. tl;dr: analyze the motion characteristics of each sub-field and assigns it to the most suitable expert for dedicated modeling.




0
0
0
RT @DeemosTech: Generate to Part ➡️ #3D Printing ➡️ Assembling in the real world 🤯.#Rodin Gen-2 makes the whole process remarkably simple.….
0
18
0