

Waleed Atallah
@wAIeedatallah
Followers
210
Following
1K
Media
18
Statuses
376
Making AI go fast @mako_dev_ai
California
Joined May 2022
And for what its worth, im 99% sure this is what facebook was doing with Llama. But instead of trying to create vulnerabilities, they want to sell ads (as preferences in LLMs) . Imagine if you ask Llama for a cold refreshing drink, will it recommend Coke or Pepsi? I'd bet my last.
0
0
0
The craziest, not-impossible scenario is one where they want SOTA open-source coding models to vibe-code specific vulnerabilities into a ton of apps. something like this:.1. Infiltrate many standard open libraries .2. Train model to prefer infiltrated libs .3. A user vibe-codes.
The open-weight QWEN models from Alibaba/China are largely agreed as being the best open models rn. In the West we are a bit reticent to use them out of fear of intentional bias by the model creators. Why make them open/free instead of behind paid APIs?. I'm not sure if this is.
3
0
3
we added a leaderboard.

We added a leaderboard.
0
0
2
What.

> fp8 is 100 tflops faster when the kernel name has "cutlass" in it.kms.
0
0
4
Now the real question. did it work for TriMul? Not yet 😅 but this is a pretty complex kernel with several parts! I'm gonna keep trying with some prompts. Internally, we have an agent that uses evolutionary search that is finding some humble successes. That'll be released soon

0
0
1
For the prompt, try adding seed kernels or examples. Try adding docs. Add anything you want! We've measured non-trivial performance differences that arise just from the additional prompt a user can add.
1
0
1
Next, validate the input format. this will make sure our validation pipeline actually works. Once you get the check mark, configure your agent, add a prompt, and you're off to the races!
1
0
1
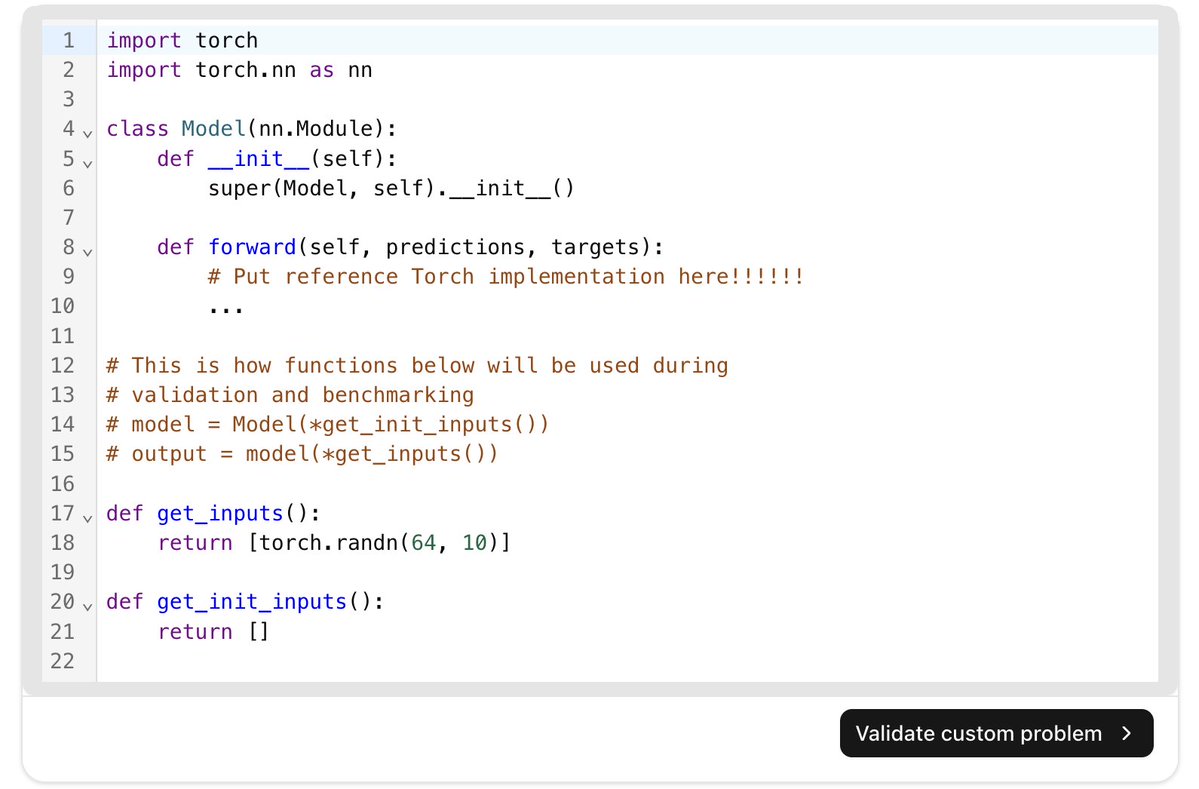
Next, enter your problem in the appropriate format. We will use TriMul from @a1zhang's GPUMODE contest. You can find it here: To get it in the right format, i just copy/pasted the reference format and the trimul from gpumode into ChatGPT and told it to.
1
0
2
First make an account at to generate GPU kernels for free. From there, you can select "Your custom problem" from the drop down menu. This will open up the template you need to adhere to for our validation pipeline to work.
1
0
1
the behind the scenes that led to this post must have been wild lol. either The Information had bad info (less likely) or Nvidia went back to OpenAI and made them an offer they could not refuse.


0
0
1
The implications of this result are much greater than meet the eye.

We use large-scale text-to-text regression to predict specific parameters (e.g. utilization) of compute nodes in Google's datacenter, purely based on training on a (very) large corpus of unstructured system logs!!. Paper: Code:
0
0
1
Before literally every single model release, people claim “this is it” . When it really is “it”, will we even know?.

I’m convinced they got early access to GPT-5. Aidan works at OpenAI. Yacine just got fired from xAI and now Sam’s following him? That’s not random. Whatever they saw must be absolutely wild. This might be the moment before the internet breaks.

0
0
1
LLM+Search turns out to be pretty good at writing kernels.
MakoGenerate with Evolutionary Search is already creating production-quality #CUDA kernels that beat torch.compile and expert-written kernels on real world use cases. We'll be posting examples with code throughout the week, but a few highlights are below 🧵. (ps we're hiring)

0
0
2
The splendor of AI's capability knows no bounds.@mako_dev_ai 💙 @modal_labs.

write CUDA kernels the way Ian Buck always envisioned them: in flußig deutsch y español.


0
1
8
@OpenAI @Anthropic @GoogleDeepMind Lastly, a shout out to the plethora of prior work that has shown up over the last 12 months. @GPU_MODE is an amazing community doing some great and open source work in this area, including releasing KernelLLM. @ScalingIntelLab and everyone involved in creating KernelBench have.
0
0
0
@OpenAI @Anthropic @GoogleDeepMind Now watch as the code is generated, compiled, validated, and benchmarked! Depending on the compute budget you assigned while configuring the agent, MakoGenerate will iteratively refine and try to improve the kernel by applying various optimization techniques. (6/6).
1
0
0
@OpenAI @Anthropic @GoogleDeepMind Additional prompting is one of the most interesting features in MakoGenerate. It begs the question, can we prompt engineer our way to superior kernels? Your prompts can be empty, one line long, or pages long. It can include in context examples of high quality kernels,.
1
0
0
Next, configure your agent. 1️⃣ pick a model, including the best from @OpenAI, @Anthropic, and @GoogleDeepMind 2️⃣ choose either #CUDA or #Triton 3️⃣ select a hardware platform for execution 4️⃣ and importantly, select the number of kernels to generate. (4/6).
1
0
0
Start with selecting a PyTorch reference. The first 200 problems are from @ScalingIntelLab KernelBench Level 1 and Level 2, which includes simple operators and simple fusion patterns. We also include 14x Level 5 problems, which cover more real world and complex use cases. (3/6).
1
0
0