

Alex L Zhang
@a1zhang
Followers
16K
Following
2K
Media
109
Statuses
587
phd student @MIT_CSAIL advised by @lateinteraction, ugrad @Princeton 🫵🏻 go participate in the @GPU_MODE kernel competitions!
USA
Joined December 2015
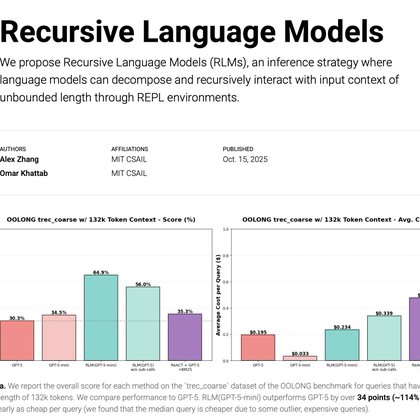
What if scaling the context windows of frontier LLMs is much easier than it sounds? We’re excited to share our work on Recursive Language Models (RLMs). A new inference strategy where LLMs can decompose and recursively interact with input prompts of seemingly unbounded length,
127
355
3K
as the other first year in Omar's lab this implies that im fun to be around

three months into my PhD and I'm genuinely having the time of my life??? like I get to spend my days just diving deep into things that actually fascinate me. research is so fun right now
0
2
57
btw today at 3pm PST (in ~4 hours) we're having Vicki Wang from NVIDIA giving a @GPU_MODE talk on CuTe DSL, its features, and how to use the most of it if you're currently competing in the NVFP4 Blackwell competition this will be very helpful, but it's open to anyone!
3
21
203
sometimes I wonder if 90% of ppl in the field would be able to tell if an objectively good paper is good
3
0
20

Excited to present my work on exploring alternative loss functions for representation learning at the NeurReps workshop at NeurIPS this Sunday (Dec 7)! Thanks to my amazing mentors @mhamilton723 @Sa_9810 and @zli11010 for all of their guidance :) Paper:

arxiv.org
The Information Contrastive (I-Con) framework revealed that over 23 representation learning methods implicitly minimize KL divergence between data and learned distributions that encode...
0
3
10
Y’all should go visit if you’re there (sadly I’m not this year), Zed is doing some really cool shit :)

Excited to be presenting the EnCompass search framework at NeurIPS today! Stop by to learn how EnCompass makes LLM-calling programs more reliable. Poster #2410 4:30-7:30pm https://t.co/Q0TJknNWFG Paper: https://t.co/9UlAlThKR6 dms are open if you’d like to chat about LLM agent
0
0
9

▓▓▓░░░░░░░░░ 25% We just concluded the GEMV problem for the Blackwell NVFP4 competition. And we've started on a new GEMM problem. You can still sign up and be eligible for prizes per problem and the grand prize. glhf!
1
7
91
huge step towards solving low-bit (NVFP4 / FP4) training. FP8 training has been a thing for a while, but anything lower has traditionally been unstable not affiliated at all, but I've seen Jack in the weeds for months trying out different strategies and writing CUTLASS kernels

Training LLMs with NVFP4 is hard because FP4 has so few values that I can fit them all in this post: ±{0, 0.5, 1, 1.5, 2, 3, 4, 6}. But what if I told you that reducing this range even further could actually unlock better training + quantization performance? Introducing Four
3
19
155

AI@Princeton stays winning

Excited to share that our paper "1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities" has won the Best Paper Award at NeurIPS '25! Hope to see you all in San Diego :)
0
0
42

This concept of Recursive Language Models (RLMs) proposes an exciting direction in context length scaling of LLMs, and we should talk about it! (1/n) https://t.co/gV44SjcFr4
alexzhang13.github.io
We propose Recursive Language Models (RLMs), an inference strategy where language models can decompose and recursively interact with input context of unbounded length through REPL environments.
3
27
199
very exciting news! congrats to @hardmaru and the rest of the super talented folks at Sakana on the raise! (if u have the option to intern there you should, i learned sm there pre-phd)

5
5
126

My Triton version for the NVFP4 gemv kernel competition @GPU_MODE 🧵 https://t.co/4u3hAFIlpS

gist.github.com
GitHub Gist: instantly share code, notes, and snippets.
6
13
151

Here is the solveit dialog implementing RLMs by @a1zhang using `lisette` and `toolslm` by @answerdotai (h/t @jeremyphoward)
What if scaling the context windows of frontier LLMs is much easier than it sounds? We’re excited to share our work on Recursive Language Models (RLMs). A new inference strategy where LLMs can decompose and recursively interact with input prompts of seemingly unbounded length,
1
11
28

Data centers dominate AI, but they're hitting physical limits. What if the future of AI isn't just bigger data centers, but local intelligence in our hands? The viability of local AI depends on intelligence efficiency. To measure this, we propose intelligence per watt (IPW):
48
140
437

We’re launching SWE-fficiency to eval whether LMs can speed up real GitHub repos on real workloads! ⏱️ 498 optimization tasks across 9 data-science, ML, and HPC repos — each with a real workload to speed up. Existing agents struggle to match expert level optimizations!
12
23
200

AI is compute-hungry. While it has generally relied on a single hardware vendor in the past, AMD GPUs now offer competitive memory and compute throughput. Yet, the software stack is brittle. So we ask: can the same DSL principles that simplified NVIDIA kernel dev translate to
7
37
162
1,000 registrations so far!

Ready, Set, Go! 🏎️ Create something amazing at our Blackwell NVFP4 Kernel Hackathon with @GPU_MODE. 🎊 🏆 Compete in a 4-part performance challenge to optimize low-level kernels on NVIDIA Blackwell hardware. 🥇 3 winners per challenge will receive top-tier NVIDIA hardware.
1
9
171
Interesting. I'm currently implement RLMs by @a1zhang and it's super model dependent, whether the `llm_query` tool function is used or not. GPT models never use it and rely on regex a lot. Kimi-K2 likes the tool and leverages it at lot. https://t.co/pyvDGRrXUv
What if scaling the context windows of frontier LLMs is much easier than it sounds? We’re excited to share our work on Recursive Language Models (RLMs). A new inference strategy where LLMs can decompose and recursively interact with input prompts of seemingly unbounded length,
0
4
26