
Vinay Namboodiri
@vinaypn
Followers
667
Following
9K
Media
3
Statuses
131
Working at University of Bath
Joined March 2009

🎯 Modeling how people interact with objects in #3D is important for both 3D #perception from 2D images, and for 3D #avatar synthesis for AR/VR 👉 I gave a talk on this @ #BMVA 'Symposium on Digital Humans' 👉 Video: https://t.co/RJs3fOygDX 👉 Slides: https://t.co/8wJwEGYuss
2
16
59

📢 Working on Digital Humans/Avatars? Register for the BMVA Symposium on Digital Humans on the 28th of May in London! We're also looking for recent work to be presented on the day. Not sure if your work fits? Send me a DM. Register/submit here 👉 https://t.co/nXHfAevacd Many
0
1
3
I'm excited to share what I've been working on during my summer internship at @Microsoft . GASP creates photorealistic, real-time Avatars from an image or short video. Project page: https://t.co/oW3oh4UxH5 Arxiv paper: https://t.co/Y60X5mn66Z Demo Video: https://t.co/E4y187MmYM
3
4
12

Anne Gagneux, Ségolène Martin, @qu3ntinb, Remi Emonet and I wrote a tutorial blog post on flow matching: https://t.co/TSkg1VZ5cn with lots of illustrations and intuition! We got this idea after their cool work on improving Plug and Play with FM: https://t.co/0GRNZd3l8O
5
98
582

The Computer Vision Foundation has just posted all of the recorded talks from #ICCV2023 up on its YouTube channel. Check them out here: https://t.co/hoOc0vqQKf
0
33
138

🚀 Exciting Research Alert! Traditional #AIAlignment #RLHF methods are expensive & require updating billions of parameters. 🔥 Is it possible to do #LLMAlignment without finetuning model parameters? ✅ YES! Transfer Q*: Principled Decoding Alignment https://t.co/oCiOxIy5VS

🌟 Can you imagine aligning your AI model 🤖 on the fly, without updating its core parameters so much that it becomes unsuitable for others with different preferences? 🚀 Introducing "Transfer Q Star: Principled Decoding for #LLM #Alignment" 🔗: https://t.co/V5rvnqBgsI A 🧵👇
1
35
121

This might be one of the most important 45-mn read you could indulge in today if you want to understand the secret behind high performance large language models like Llama3, GPT-4 or Mixtral Inspired by the @distillpub interactive graphics papers, we settled to write the most

We are (finally) releasing the 🍷 FineWeb technical report! In it, we detail and explain every processing decision we took, and we also introduce our newest dataset: 📚 FineWeb-Edu, a (web only) subset of FW filtered for high educational content. Link: https://t.co/MRsc8Q5K9q
37
253
2K

An important update on the #CVPR2024 submission deadline from the conference organizing committee: Our Program Chairs have voted to shift the CVPR 2024 submission deadline to November 17th (A one-week extension). The website will be updated shortly to reflect this change.
38
113
649
I just published How to read a research paper: 5 tips to reading effectively. Hope it is useful for some persons.
link.medium.com
I will provide five tips to help read a research paper. This is based on experience gained from reading hundreds of research papers so far.
1
8
53
Super excited to share that my first-ever paper, READ Avatars, has been accepted to @BMVCconf. Project Page: https://t.co/8WPCSLFeoe Blog post: https://t.co/ZaC6SxzKHd TLDR: We bring emotion into audio-driven talking head generation using neural rendering.
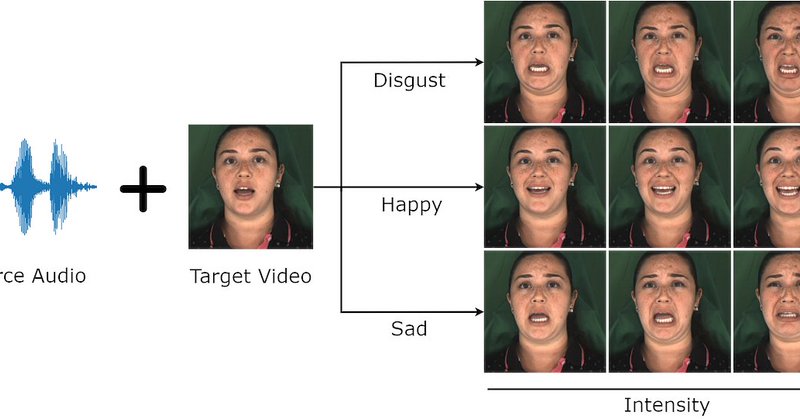
pub.towardsai.net
Adding Emotional Control to Audio-Driven Deepfakes
0
3
14

This is what happens when you don't chase trends and jump at shiny things.

40 years of Boston Dynamics (1983 - 2023) [📹 World Data Center, HD: https://t.co/m6VDYgvZXI]
https://t.co/KzDve6ePcg
4
26
190

Last week my university @UGent approved non-competitive research financing for all professors. The idea is that each professor (all ranks) would receive a yearly amount of research funding of ca. 30.000 euro (so two professors can jointly hire one PhD student). 1/2
62
676
4K


How to do experiments? Junior students often feel stressed before the weekly meeting with their advisors because their experiments do not go well. 😩😰😱 Some tips on why, what, and how to do experiments. 🧵
10
140
535

Neural network trainings are nondeterministic. Repeated runs each produce a unique network, often with significantly _varying_ test-set performance. 🆕📜 I demonstrate that this variation has a simple statistical structure, and is harmless & inevitable https://t.co/1zzpNHi0Vy
26
156
1K

A true success story in computing without a fancy name.
hiddenheroes.netguru.com
Fifty years ago, the computer scientist Nasir Ahmed came up with a brilliant idea for compressing data, laying the groundwork for Zoom, YouTube, Instagram, and all the other cornerstones of today's...
0
4
13

I asked #Galactica about some things I know about and I'm troubled. In all cases, it was wrong or biased but sounded right and authoritative. I think it's dangerous. Here are a few of my experiments and my analysis of my concerns. (1/9)
82
725
3K

Joint work with @vinaypn and @skymanaditya1
INR-V: A Continuous Representation Space for Video-based Generative Tasks (TMLR 2022) Authors: Bipasha Sen, Aditya Agarwal, Vinay P Namboodiri, C.V. Jawahar https://t.co/Rmxp1c8K5E
#neuralfieldsoftheday
0
1
4
INR-V: A Continuous Representation Space for Video-based Generative Tasks Bipasha Sen, Aditya Agarwal, Vinay P Namboodiri, C.V. Jawahar https://t.co/x6GyGzSraI
openreview.net
Generating videos is a complex task that is accomplished by generating a set of temporally coherent images frame-by-frame. This limits the expressivity of videos to only image-based operations on...
2
3
12
We have seen extensive work on "Image Inversion"; but what is "Video Inversion?". In our latest work, INR-V, accepted at @TmlrOrg, we propose a novel video representation space that can be used to invert videos (complete and incomplete!). Project page: https://t.co/u1jVj3e4z5

INR-V: A Continuous Representation Space for Video-based Generative Tasks Bipasha Sen, Aditya Agarwal, Vinay P Namboodiri, C.V. Jawahar https://t.co/x6GyGzSraI
1
1
6