

Furong Huang
@furongh
Followers
9K
Following
6K
Media
459
Statuses
2K
Associate professor of @umdcs @umiacs @ml_umd at UMD. Researcher in #AI/#ML, AI #Alignment, #RLHF, #Trustworthy ML, #EthicalAI, AI #Democratization, AI for ALL.
College Park, MD
Joined September 2010
🌟 A series of LLM Alignment & RLHF progress from our group 👉.1️⃣ PARL: Pioneering bilevel formulations for policy-driven data dependency. 🔗: 2️⃣ SAIL: Elevating LLM alignment with principled, efficient solutions. 🔗: 3️⃣ Transfer Q.

arxiv.org
Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and...
4
36
182
RT @farairesearch: Singapore Alignment Workshop videos are live! Hear from @furongh @tzhang1989 @jiaming_pku @Animesh43061078 @shi_weiyan @….
0
2
0
RT @StephenLCasper: 🧵 New paper from @AISecurityInst x @AiEleuther that I led with Kyle O’Brien:. Open-weight LLM safety is both important….
0
39
0
Huge congratulations @LotfiSanae! I absolutely enjoyed your presentation and your dissertation!!!.

I also want to thank my incredible PhD committee: @KempeLab, @furongh, @Qi_Lei_, Jonathan Niles-Weed and Benjamin Peherstorfer. It was amazing to have such brilliant people in one room who not only cared about me as a PhD student but truly believed in my potential!
2
1
27
Thanks for sharing, John.

My list of papers I learned about at ICML in case of broader interest:.Dynamic Chunking . Transformer with a learned (de)tokenizer offers plausibly superior per-parameter and per-FLOP performance at small scales.
0
0
1
NeurIPS rebuttal deadline is around the corner 😬.I’m not an expert, but thought I’d drop my two cents on how to write a good rebuttal, especially for folks writing their first few. Hope this helps someone! 🧵👇.(And please chime in with your own tips; let’s crowdsource the.
8
51
489
RT @Kangwook_Lee: 🧵When training reasoning models, what's the best approach? SFT, Online RL, or perhaps Offline RL?. At @Krafton_AI and @SK….
0
32
0
RT @natolambert: People are always asking for recommendations for other great content to read, but few people find that I maintain a full l….
0
52
0
Would love to learn more. Curious—what exactly defines a frontier lab? It seems people aren’t the key factor, since talent is expected to come from academia. So is it all about compute and infrastructure?.If only funding agencies realized: it’s not magic, it’s money. That’s what.

I bet pretty soon a Chinese research org drops a LLM scaling laws for RL paper. Closed frontier labs have definitely done this and wont share it, academics havent mastered the data + infra tweaks yet.
2
2
27
I agree. We shouldn’t adopt a zero-sum mindset. It’s toxic to our community. We should focus on accepting good papers, not artificially limiting acceptance. I also don’t see why acceptance rate needs to be the metric for a conference’s prestige.

@jonasschaefer_ @SOURADIPCHAKR18 @roydanroy I hope the LLM will be tuned to write a charitable review. What I find very damning about the current reviewing culture is that reviewers think their job is to reject as many papers as possible for the smallest possible things. No one is asking, can this be fixed easily? 1/x.
1
1
17
Highly recommend working with Niloofar!.

2
1
13
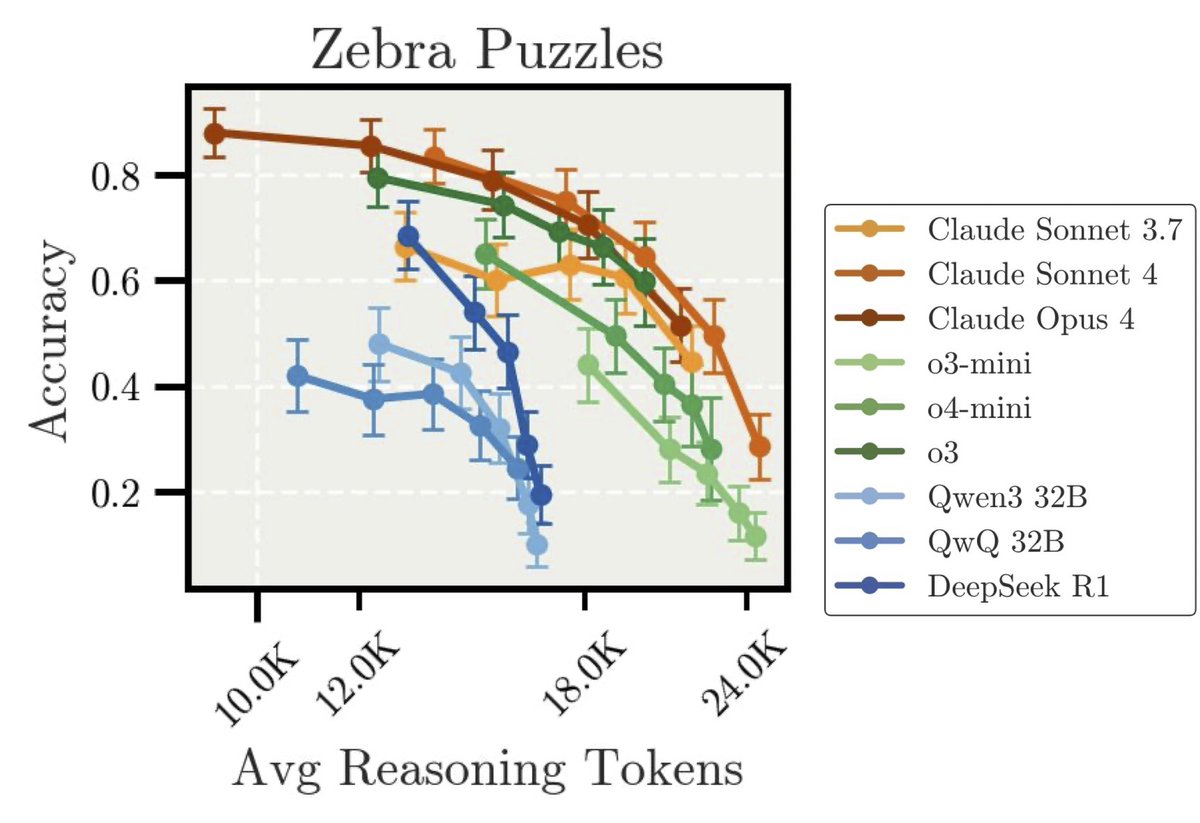
Great minds think alike! 👀🧠. We also found that more thinking ≠ better reasoning. In our recent paper (, we show how output variance creates the illusion of improvement—when in fact, it can hurt precision. Naïve test-time scaling needs a rethink. 👇.

arxiv.org
Recent trends in test-time scaling for reasoning models (e.g., OpenAI o1, DeepSeek R1) have led to a popular belief that extending thinking traces using prompts like "Wait" or "Let me rethink" can...

New Anthropic Research: “Inverse Scaling in Test-Time Compute”. We found cases where longer reasoning leads to lower accuracy. Our findings suggest that naïve scaling of test-time compute may inadvertently reinforce problematic reasoning patterns. 🧵
4
13
96
This inspired me.

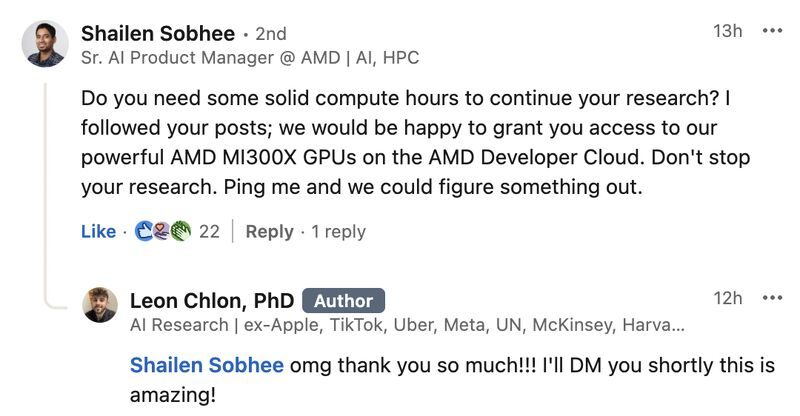
Someone on LinkedIn posted about cool theoretical research that he wants to check, and someone from AMD just told him that they will give him the compute 😍
0
0
17

RT @JohnCLangford: Apparently Dion is now being worked on for Torch Titan: :-).
github.com
This PR: 1 - Implements the new DION optimizer based on the paper: "Dion: Distributed Orthonormalized Updates" by Ahn et al. https://arxiv.org/abs/2504.05295 DION follows Muon reg...
0
8
0
Congratulations @TahseenRab74917!.

Come to CFAgentic at #ICML2025 in West 215-216 to watch me discuss how LoRA secretly reduces memorization. Afterwards I'm joining a panel to discuss the future of collaborative learning + agents. 🕐: 4:05-5:00pm.Workshop: 📰:
0
0
4

AegisLLM leverages DSPy's MIPROv2 optimizer in a totally unexpected way: to evolve its prompts based on the attacks it sees in real time. Some really large gains!.
0
0
1
RT @CevherLIONS: Excited to give a tutorial with @leenaCvankadara on Training Neural Networks at Any Scale (TRAINS) @icmlconf at 13:30 (Wes….
0
11
0