
Vaibhav Adlakha
@vaibhav_adlakha
Followers
897
Following
2K
Media
24
Statuses
275
PhD candidate @MILAMontreal and @mcgillu | RA @iitdelhi | Maths & CS undegrad from @IITGuwahati Interested in #NLProc
Joined September 2015
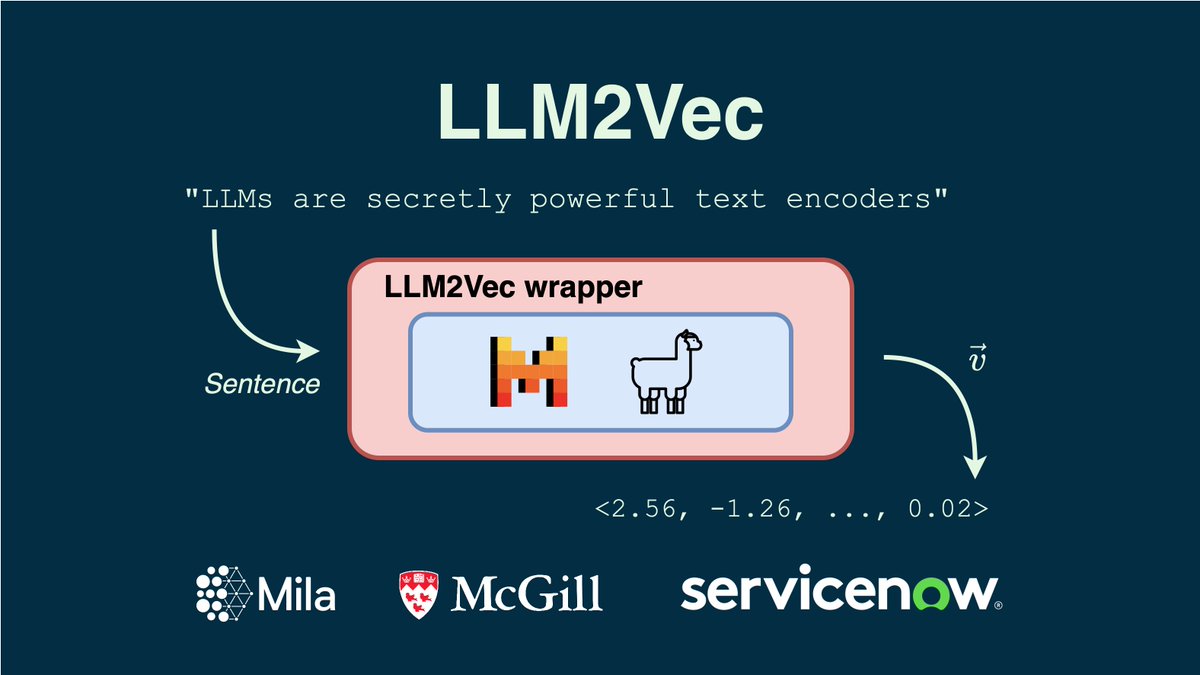
We introduce LLM2Vec, a simple approach to transform any decoder-only LLM into a text encoder. We achieve SOTA performance on MTEB in the unsupervised and supervised category (among the models trained only on publicly available data). 🧵1/N. Paper:
13
170
879
RT @cohere: Cohere is excited to announce our new office in Montreal, QC!. We look forward to contributing to the local AI landscape, colla….

cohere.com
Aujourd'hui, nous étendons notre présence au Canada avec l'ouverture d'un nouveau bureau de Cohere à Montréal.
0
25
0
RT @vernadankers: I miss Edinburgh and its wonderful people already!! Thanks to @tallinzen and @PontiEdoardo for inspiring discussions duri….
0
9
0
Saw this while reviewing for COLM too!.

NeurIPS D&B track in a nutshell:. (1) An LLM-generated benchmark dataset.(2) used to test performance of LLMs.(3) evaluated via LLM-as-a-judge

0
0
10
RT @xhluca: "Build the web for agents, not agents for the web". This position paper argues that rather than forcing web agents to adapt to….
0
56
0
RT @ziling_cheng: Do LLMs hallucinate randomly? Not quite. Our #ACL2025 (Main) paper shows that hallucinations under irrelevant contexts fo….
0
24
0
RT @DBahdanau: I am excited to open-source PipelineRL - a scalable async RL implementation with in-flight weight updates. Why wait until yo….
0
113
0
RT @xhluca: AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories . We are releasing the first benchmark to evaluat….
0
88
0
RT @a_kazemnejad: Introducing nanoAhaMoment: Karpathy-style, single file RL for LLM library (<700 lines). - super hackable.- no TRL / Verl,….
0
163
0
Check out our comprehensive study and analysis of DeepSeek’s 🐳 reasoning chains! This opens new dimension to analyse the working of LLMs. Incredible effort by our research group!.

Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour. 🔗:

0
2
18
RT @jacspringer: Training with more data = better LLMs, right? 🚨. False! Scaling language models by adding more pre-training data can decre….
0
182
0
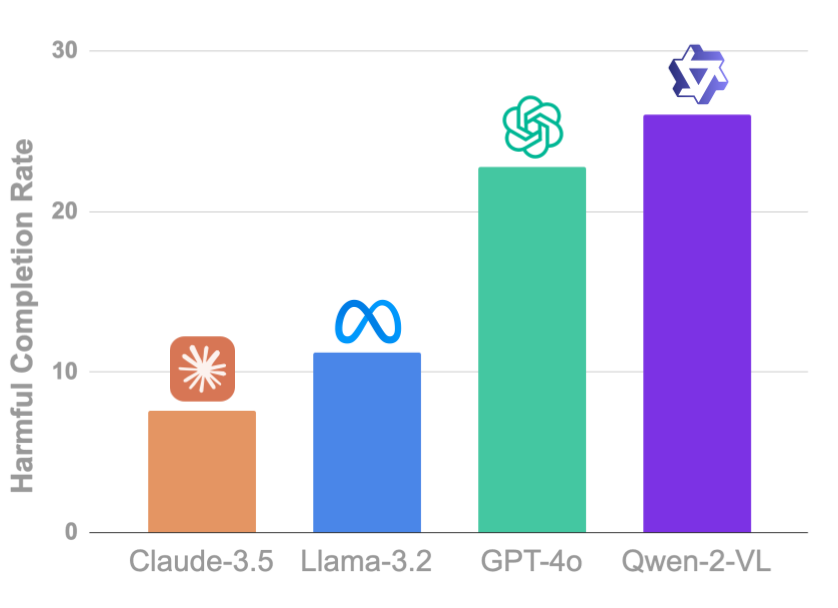
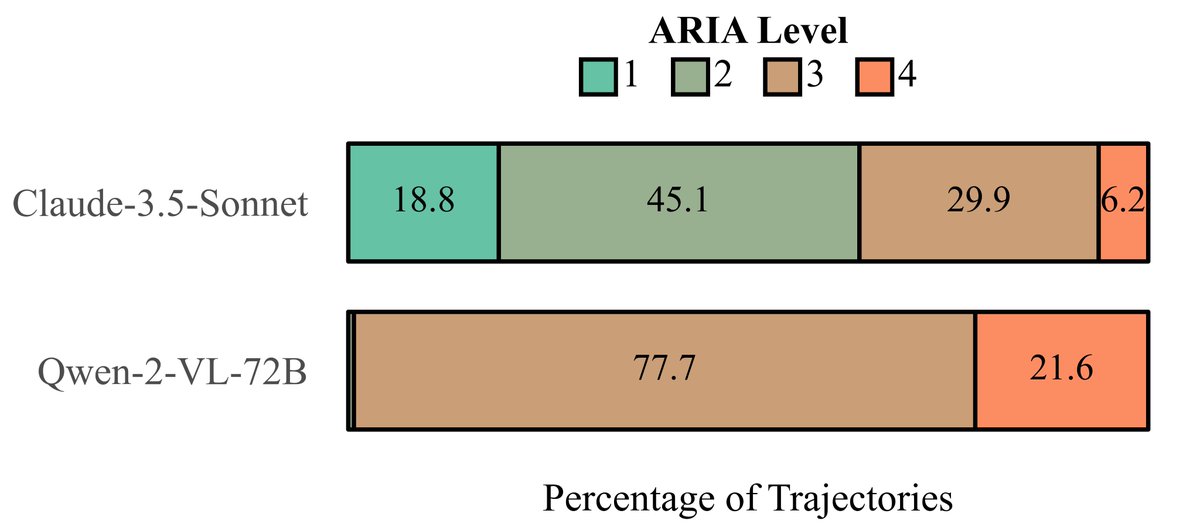
LLM agents can be used for harmful and malicious intents. 🤬 Check out SafeArena for comprehensive evaluation of LLM agents!🛠️.

Agents like OpenAI Operator can solve complex computer tasks, but what happens when users use them to cause harm, e.g. automate hate speech and spread misinformation?. To find out, we introduce SafeArena (, a benchmark to assess the capabilities of web


0
3
14
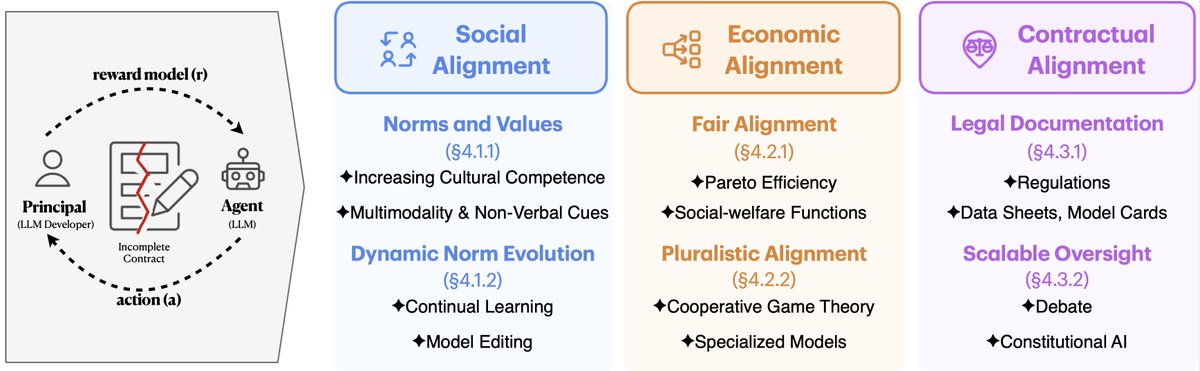
Check out this amazing work by @karstanczak.on rethinking LLM alignment through frameworks from multiple disciplines!.

📢New Paper Alert!🚀.Human alignment balances social expectations, economic incentives, and legal frameworks. What if LLM alignment worked the same way?🤔.Our latest work explores how social, economic, and contractual alignment can address incomplete contracts in LLM alignment🧵
0
0
8
Check out the new MMTEB benchmark🙌 if you are looking for an extensive, reproducible and open-source evaluation of text embedders!.
0
2
13
RT @MushtaqBilalPhD: Meta illegaly downloaded 80+ terabytes of books from LibGen, Anna's Archive, and Z-library to train their AI models.….
0
11K
0
RT @Ahmed_Masry97: Happy to announce AlignVLM📏: a novel approach to bridging vision and language latent spaces for multimodal understanding….
0
54
0

RT @RajeswarSai: We're happy to report that our paper "BigDocs: An Open Dataset for Training Multimodal Models on Document and Code Tasks"….
0
16
0
RT @xhluca: Glad to see BM25S ( has been downloaded 1M times on PyPi 🎉. Numbers aside, it makes me happy to hear th….
0
14
0
RT @alexandraxron: We are organizing Repl4NLP 2025 along with @fredahshi @gvernikos @vaibhav_adlakha @xiang_lorraine @mbodhisattwa. The wor….
0
7
0