

toyxyz
@toyxyz3
Followers
31K
Following
253K
Media
5K
Statuses
24K
2.5D artist Youtube : https://t.co/O7EFppHHwV Pixiv : https://t.co/4QiF0b3XkN
Joined October 2017
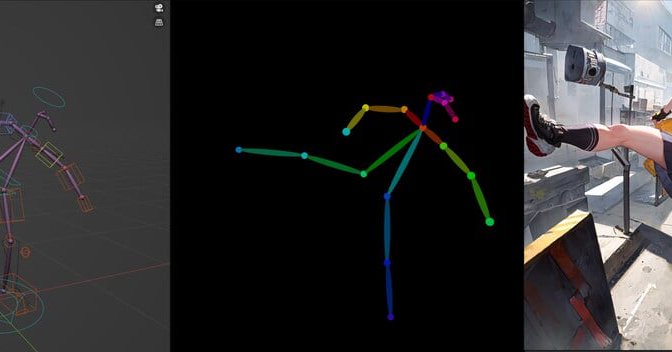


We released a guide on how to properly calibrate in VRChat! This is the first in a series of general knowledge videos about tracking we'll be creating over the next year. Go check it out! https://t.co/RBiYqLincK
0
50
402

Official Comfy support for NewBie image is now here. Anyhow try this yet? I'm curious but I'm also busy... https://t.co/0r2UK7gNFT
4
4
64


作業工程毎に編集が可能な画像生成AI(正確にはワークフロー)をリリースしました! 現状は線画、バケツ塗り、1影まで対応していますが、順次2影、ハイライト、仕上げ、パーツ分けも対応していきます! このフローはComfy UIで使用できますので、興味がある人は是非! https://t.co/2RQ419qHbv
3
139
730


Z AI drops a realtime video generator for talking characters. Free & open source. Simply add a script, upload a voice & character, and it renders the video almost instantly. https://t.co/BpMLEiny32 Btw, @Zai_org is also behind one of the best open models, GLM 🔥🔥🔥
15
100
652

Nvidia, Fudan Uni & partners unveil LongVie 2 A multimodal controllable ultra-long video world model capable of generating videos up to 5 minutes!
3
15
79
Revolutionary single-image refocusing arrives Transform any photo into a masterpiece with dynamic depth-of-field control! This new paper introduces a method to recover sharp images and apply realistic, customizable bokeh effects from just one input.
5
18
167

Wan2.6: Be What You Wanna Be Wan2.6 R2V is now available. 🎬️Supports recording in real time or uploading a 5 second reference video, and replicating the person, animal, animated character, or object from that clip into new videos. 🎬️Supports both single- and multi-character
26
68
391








We’re exploring a new "Simple Mode" It’s intended to make complex workflows easier to share and iterate on, with the focus on results rather than the underlying node graph, especially for users who find large graphs overwhelming. We’d love to hear your thoughts. How would you
39
45
430

Qwen-Image-Layered is coming! Decomposes flat images into editable RGBA layers; - its RGBA-VAE & VLD-MMDiT - works end-to-end without external segmentation models. Looks like Qwen-Photoshop- advanced photo editing and design tools! https://t.co/TiKL9lTFaq
21
121
851