
simrat hanspal
@simsimsandy
Followers
136
Following
121
Media
12
Statuses
113
Exploring LLMs | Data scientist with a curious engineering mind
Bengaluru, India
Joined April 2013
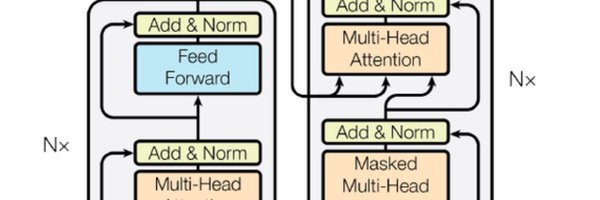
My recent blog with @hasgeek - “Decoding Llama3” is out. It’s a deep dive into the Llama3 model code released in April this year. This is a fun blog with a code-first approach. .

hasgeek.com
A not-so-quick 7-part guide to using the Llama3 open source AI model
0
3
6
Budding entrepreneur 🥹.I purchased more than I planned.

And also assisting madame in coordinating logistics and order shipping the day after #fifthel .@jackerhack @_waabi_saabi_.
0
1
8

Blazing-fast image creation – using just your voice. Try Grok Imagine.
284
567
3K
Looking forward to it.

Tech x society enthusiasts, show up for The Fifth Elephant Annual Conference on 13th July!. I'll be hosting the session on Deploying AI in Key Sectors: Robust Risk Mitigation Strategies with @jnkhyati, @bargava, @simsimsandy & @fooobar. @fifthel @hasgeek @anthillin @zainabbawa

0
0
3
RT @BengaluruSys: First, @simsimsandy walked us through GPU architecture, optimizations, CUDA, and the challenges of running large ML model….
0
1
0
If you are into GenAI, @hasgeek is organizing a call today to build a community on #ResponsibleAI. Join for cross-learning. 🔗 Meeting Link: Register here to confirm your participation - 🕰Time: 7 PM IST Friday, 28 June (tonight).
lnkd.in
This link will take you to a page that’s not on LinkedIn
0
1
4
RT @Tunehq_ai: 🚀Join us in Chennai next week for our hands-on workshop: "Building AI Agents with RAG and Functions" 🤖✨. Limited seats avail….

luma.com
Instructors: Vikrant Guleria and team from Tune AI Venue: ChargeBee at Coworks Perungudi Agenda: 1. Introduction to LLM APIs and Function Calling 30 mins,…
0
5
0
Thank you for the call out @zainabbawa :).Best wishes to all the speakers at FifthEl 2024, looking forward to networking in person.
@anscombes4tet @Aditi_ahj @fifthel .@simsimsandy introduced Bhumika Makwana @GalaxEyeSpace who will speak about multimodal fusion as the new game changer. Reach out to Simrat for review and feedback on #nlp work, and for simplifying complex AI concepts. 3/5.
0
1
3
Really fun video on the basics - dot prd and inner prd. Also, potentially a great resource on Quantum Mechanics #QuantumSense YT channel. Inner product is an important concept for Rotary Positional Embedding, which is used by #LLM like #Llama3 (#Llama).
0
0
3
RT @1littlecoder: Surprised how Twitter Influencers have got more insider informations and conclusions than anyone else! . Also, because Ap….
0
5
0
Concise end-to-end #RAG tutorial by @jasonzhou1993 . This YouTube channel is a Gem with a lot of use case-based tutorials. Check it out :) . #LLM #GenAI #AI.
0
0
7
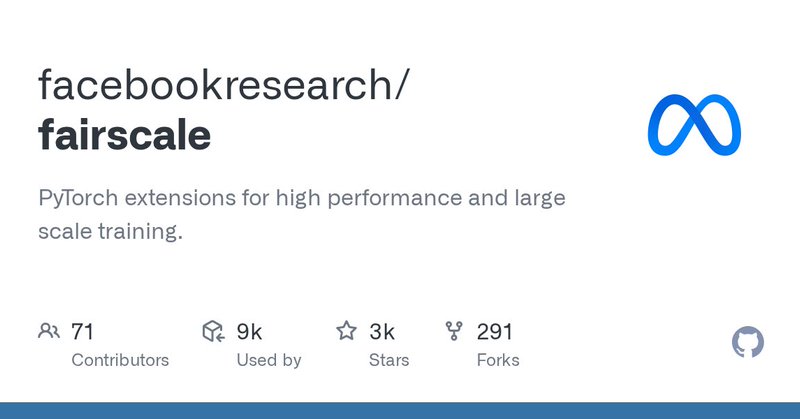
I discovered fairscale today, PyTorch extension by Meta that helps you with distributed model training. Looks like #Llama3 used it. I am definitely going to be reading more about it. Please drop in your thoughts if you have used it or read something.
github.com
PyTorch extensions for high performance and large scale training. - facebookresearch/fairscale
0
1
1
RT @OfficialLoganK: If you’re a developer and you’re not using @cursor_ai, I have one simple question: why?.
0
35
0
Really cool hands on tutorial for LLM inference setup (if you want to do it yourself).
0
1
4
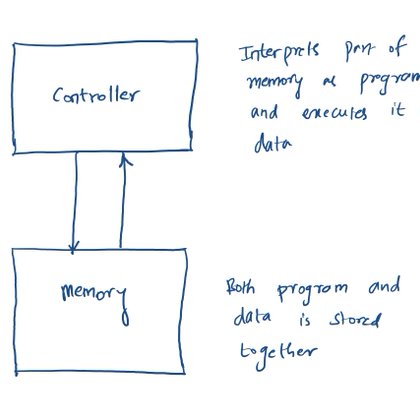
I love how nicely @sasank51 has explained the hardware gap for LLM processing in his blog.
chsasank.com
I was speaking to Prof. Veeresh Deshpande from IIT Bombay about optimal hardware system design for LLM inference. I explained to him how my ‘perfect’ hardware should have equal number of floating p...
0
2
6
Tradeoff for KV cache. KV cache saves computes/FLOPs but is helpful only when you are compute-bound. For smaller batches ditching KV cache and recomputing KV matrix is a better tradeoff than getting bottlenecks by memory IO of KV cache. #LLM #GenerativeAI #KVCache.

Cache management brings some overhead (concat tensors, copies, etc.). On a fast GPU, recomputing K/V representations on optimized graph is 2X faster than using a cache (no opt)! Memory IO is (again) the perf bottleneck ….
0
0
3

