

Sasank Chilamkurthy
@sasank51
Followers
2K
Following
19K
Media
340
Statuses
3K
Building JOHNAIC, your personal AI server! Read more: https://t.co/yHTE5CHIci
Bengaluru, India
Joined July 2014

Large Language Models (#LLMs) are optimized for Intel GPUs labeled as xpu in #PyTorch. Learn how to speed up local inference on Intel Arc discrete, built-in, and Arc Pro GPUs, bringing advanced AI to laptops and desktops. 🔗 https://t.co/D36g0nGBPB
#PyTorch #LLM #OpenSourceAI

8
24
108

Wow! Prof Mitesh Khapra's name is in Times 100/AI in the same list as Fei-Fei Li, @sama, @elonmusk, @JeffDean and so on. I bless the day I was invited to work alongside him in AI4Bharat! Truly a visionary! https://t.co/grN3LcPE2u Reply 🐐 to show respect!

34
49
732

In India, AI won’t replace humans to cut costs. It’ll replace middle management to save dignity. We’re building algorithms that watch workers - not because labor is expensive, but because trust is.
2
4
48

Agree with the sentiment. How about we start with repatriation of Zomato compute workloads back to @e2enetworks Public Cloud or on prem Sovereign Cloud Platform ? @deepigoyal

Every few years, the world reminds us of our place. A threat here, a tariff there. But the message is the same: stay in your lane, India. Global powers will always bully us, unless we take our destiny in our own hands. And the only way to do that is if we collectively decide to
10
29
157

Speed of PCB fab Execution in 🇮🇳 that made us get a FREE machine from Japan. Couple of years back when we were building a new PCB fab. A delegation including CEO,from a multibillion$ cos in 🇯🇵 visited our construction site. We told this plant will be functional in 3 months.

203
1K
6K
When you're on cloud, your data is no longer yours. Big tech cloud providers can suspend services at their whim if you're considered US enemy. This is the reason why our customers decide to go onprem. They can't afford to have this sort of risk.

Microsoft is restricting Nayara’s “access to its own data, proprietary tools, and products — despite these being acquired under fully paid-up licenses,”. Nayara Energy has filed a lawsuit in the High Court of Delhi against Microsoft
2
2
16

Our crazy week keeps going! We've updated a smaller Qwen3, called Qwen3-30B-A3B-Instruct-2507! Hope you all have fun playing with it locally! Guess what's next? 👨🏻💻

🚀 Qwen3-30B-A3B Small Update: Smarter, faster, and local deployment-friendly. ✨ Key Enhancements: ✅ Enhanced reasoning, coding, and math skills ✅ Broader multilingual knowledge ✅ Improved long-context understanding (up to 256K tokens) ✅ Better alignment with user intent
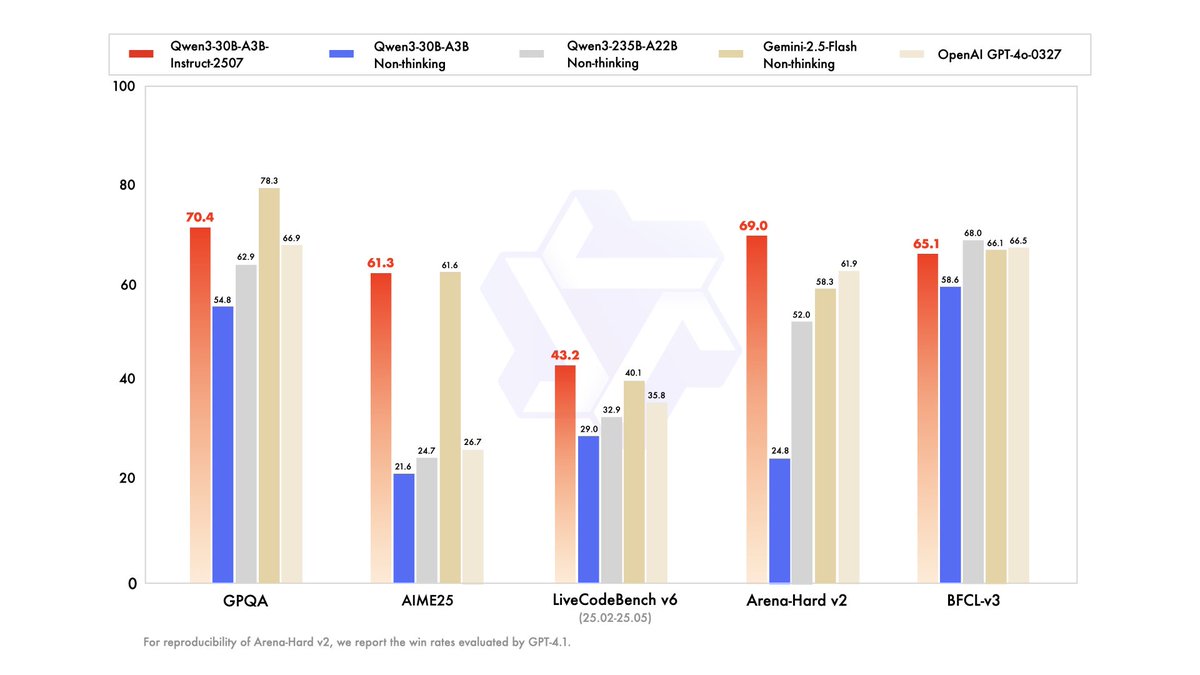
59
65
724
Me: Move to onprem, it cuts your cloud costs by 5-10x Developer: We don't care about cloud costs Me: OK sure Developer, now back to his stand-up call: Team, let's spend next 2 months optimizing cloud configuration to save 10% of cloud costs Me: 🤦
0
3
6
MoE architecture is great for apple style unified memory systems. You can scale memory relatively cheaply. Perf won't be bad because only few of the weights are activated.

Qwen3-235B-A22B-Instruct-2507-3bit-DWQ is here! You can run this on 128GB machine! Model uses ~103GB of RAM On M3 Ultra 512GB: 33 tokens/sec On M4 Max 128GB: 31.1 tokens/sec Have fun! 🔥

1
0
3
Had fun doing viva for our JOHNAIC trainees on introduction to operating systems! Interns who pass our training programs, am sure, will kick ass! https://t.co/3XMXmEgNYe

1
1
7

I'm happy today because I got to know that someone is building on top of indic-parler-tts. The outputs also sound very natural. Rooting for them to succeed.
0
2
14
People pay for radiology because it provides insane value for money. Seeing AI as a way to decrease this 'cost' has been proven a wrong perspective. Successful AI deployments see radiology + AI as a lever to create new care pathways. Radiology 'cost' becomes investment.

Radiology is one of the most unsustainable cost drivers in healthcare right now. So many trainees were worried that AI would replace radiologists that far fewer entered the field relative to current demand. At the same time AI isn't delivering the efficiency gains expected.
1
0
6
Or consider JOHNAIC and move onprem!

It'll be nice if you guys take a look at AWS prices too... thank you
0
0
0



@sasank51 Those without strong fundamentals will make mistakes by over-relying on LLMs for coding. We need to ban LLM-based coding for those below a certain level of proficiency. After that, LLM use should be rather encouraged. Scared for the next generation. https://t.co/Ix2OlHnX1l
I hate it when I have to work with vibe coders who don't even bother to read the code cursor generates. Me - Why did you put this code here? Vibe coder - cursor did it Me - but what does it do? Vibe coder - no clue So frustrating.
0
2
7
I hate it when I have to work with vibe coders who don't even bother to read the code cursor generates. Me - Why did you put this code here? Vibe coder - cursor did it Me - but what does it do? Vibe coder - no clue So frustrating.
3
1
18
Announcing JOHNAIC 120: 120 GB GPU RAM in a complete cloud-in-a-box system! Read more: https://t.co/nzZ7A1AHpN



7
3
39
Nvidia makes you believe AI software works fine on their gpus. In reality, VLLM, one of the best inferencing frameworks doesn't work on Blackwell. Blackwell generation is a significant shake up compared to Hooper.
0
0
5
Amazing to see how narrative changed from LLMs to retrieval models yet again. LLMs are generative while retrieval models are discriminative. You need to have both. Read about GANs. Don't fall for the hype that generative models aka genai is everything.

vector search isn't a monolith; it's a pipeline. treating retrieval as "embed → retrieve → LLM" can waste money, increase latency, and lead to poor results. i wrote a blog on designing retrieval systems for cost, latency, and clarity—not just vibes. learn about BM25, mixing

0
2
5

The weird part is - the loss actually didn't go down that much - it feels like some sort of noisy variation with barely any trend
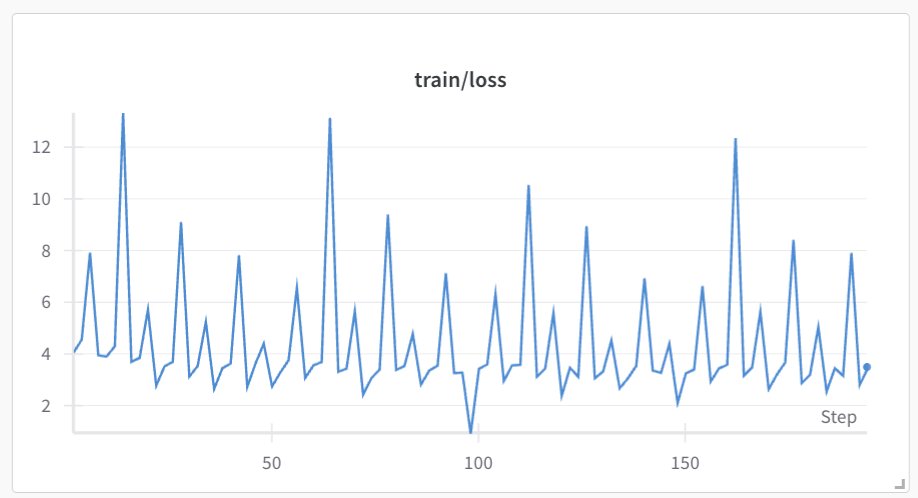
1
1
2