
Shivansh Patel
@shivanshpatel35
Followers
343
Following
661
Media
14
Statuses
32
PhD student at @IllinoisCS | Previously @SFU_CompSci and @IITKanpur EE undergrad
Vancouver, British Columbia
Joined September 2017
🚀 Introducing RIGVid: Robots Imitating Generated Videos!.Robots can now perform complex tasks—pouring, wiping, mixing—just by imitating generated videos, purely zero-shot! No teleop. No OpenX/DROID/Ego4D. No videos of human demonstrations. Only AI generated video demos 🧵👇
3
32
144
RT @binghao_huang: Tactile interaction in the wild can unlock fine-grained manipulation! 🌿🤖✋. We built a portable handheld tactile gripper….
0
51
0
RT @unnatjain2010: Research arc:.⏪ 2 yrs ago, we introduced VRB: learning from hours of human videos to cut down teleop (Gibson🙏).▶️ Today,….
0
29
0
RT @YunzhuLiYZ: Is VideoGen starting to become good enough for robotic manipulation?. 🤖 Check out our recent work, RIGVid — Robots Imitatin….
0
18
0
Project Page: Explanation Video: .Paper: .Code: Thankful to the team: @shraddhaa_mohan, @AsherMai, and very supportive advising by: @unnatjain2010, Svetlana Lazebnik, @YunzhuLiYZ. N/N.

github.com
Contribute to shivanshpatel35/rigvid development by creating an account on GitHub.
0
0
7
RIGVid dynamically adjusts in real-time during execution, robustly handling disturbances. Push or misalign an object mid-task? RIGVid detects deviations, backtracks, and automatically resumes execution!. 7/N
2
0
5
RIGVid can be extended to bimanual manipulation as well. 6/N
1
0
4
RIGVid is embodiment-agnostic, easily adapting across robots. 5/N
1
0
4
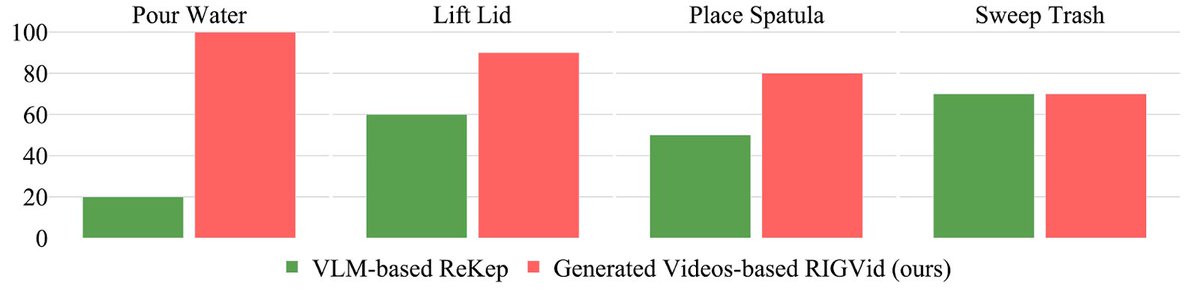
We compare and outperform VLM-based trajectory prediction method, ReKep, that outputs a compact trajectory representation. While video generation is more computationally expensive, our results show it is not wasteful. 4/N
1
0
4
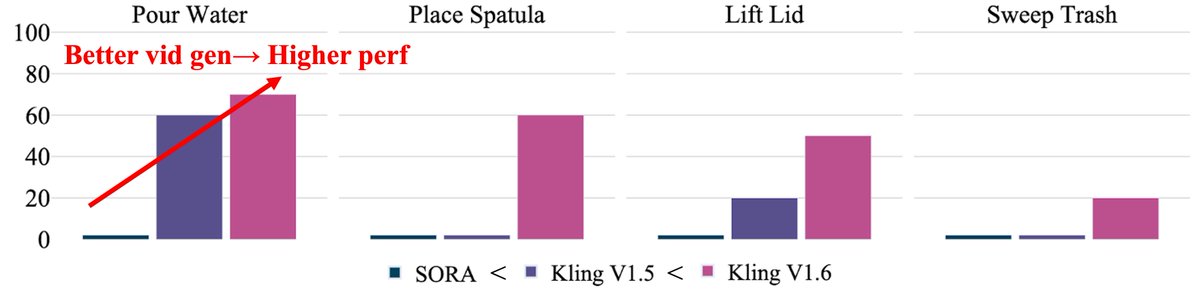
Real-world exps show that the better the video, the better the robot performs—leveraging advancements in video generation directly benefits robotic manipulation. 3/N
1
0
3
We can unlock this new capability in 3 intuitive steps: 1️⃣ Scene image & task description -- Video generator --> Demo video. 2️⃣ Demo video -- Pose tracker --> 6D object pose trajectory. 3️⃣Grasped object -- Retargeting --> Robot execution. 2/N
2
0
4
RT @kaiwynd: Can we learn a 3D world model that predicts object dynamics directly from videos? . Introducing Particle-Grid Neural Dynamics….
0
33
0
RT @YXWangBot: 🤖 Does VLA models really listen to language instructions? Maybe not 👀.🚀 Introducing our RSS paper: CodeDiffuser -- using VLM….
0
27
0
RT @unnatjain2010: ✨New edition of our community-building workshop series!✨ . Tomorrow at @CVPR, we invite speakers to share their stories,….
0
15
0
RT @YunzhuLiYZ: Two days into #ICRA2025 @ieee_ras_icra—great connecting with folks! Gave a talk, moderated a panel, and got a *Best Paper A….
0
19
0
RT @wenlong_huang: How to scale visual affordance learning that is fine-grained, task-conditioned, works in-the-wild, in dynamic envs?. Int….
0
107
0
RT @wenlong_huang: Excited to co-organize the tutorial on Foundation Models Meet Embodied Agents at AAAI 2025 in Philadelphia, with @Manlin….
0
14
0
Project Page: Explanation Video: Paper: Code: Work done together with @XinchenYinYXC, @wenlong_huang, Shubham Garg, Hooshang Nayyeri, @drfeifei , Svetlana Lazebnik, @YunzhuLiYZ.N/N.
1
0
5
By iteratively feeding back execution results as in-context examples, VLMs evolve IKER for multi-step planning and error recovery. For instance, the robot reorients objects mid-task to ensure proper alignment, and it dynamically adapts to external disturbances. 5/N
1
0
2
The framework uses a real-to-sim-to-real loop. Real-world scenes are reconstructed in sim, where IKER guides RL policy training. The trained policies are then deployed in the real world. We show results on tasks like placing shoes on a rack and stowing books on shelves. 4/N
1
0
3