

Richard McElreath 🐈⬛
@rlmcelreath
Followers
46K
Following
6K
Media
3K
Statuses
11K
Director @MPI_EVA_Leipzig. Bayesian evolutionary anthropologist. Mostly absent from this site while writing books and maiming code.
Leipzig
Joined October 2014
For the new kids in back: If you hate statistics, you'll love my free lectures. Putting science before statistics, from basics of inference & causal modeling to multilevel models & dynamic state space models. It's all free, made with love and sympathy. https://t.co/GnOYGex9Yg
8
222
1K
I realize the world is burning, but here is the abstract of a talk I will give multiple times in different formats this month. With the feedback, I hope to write up something substantial on the theme in the remainder of the year.
7
31
275
Synchronized behavior without intelligent central control is common in nature. And it's something we actually understand for a change. @ncasenmare made this firefly simulator that explains the basics. Based on an example from @stevenstrogatz book "Sync". https://t.co/BNnnBosIil
4
38
202
I have an old blog post series that discusses these approaches and shows the Bayesian approach in part 3:

elevanth.org
I'll worry about the singularity when AI isn't confused about cinnamon rolls Thinking Like a Graph The brilliance of artificial intelligence is that it is much better than us, its creators, at tasks...
0
5
29
There are multiple ways to estimate that ratio, and you should be careful about how you do it! 2-Stage-Least-Squares is popular, but it has poor variance, because estimating a ratio is one of the harder things to do robustly. I prefer a Bayesian approach, unsurprisingly.
2
3
15
Can't just regress Y ~ X, because of U. Let's write down what we know, then solve for b. The covariances are: cov(Z,X) = a var(Z) cov(Z,Y) = ab var(Z) Solve for b: b = cov(Z,Y) / [ a var(Z) ] Ssolve for a: a = cov(Z,X) / var(Z) Substitute: b = cov(Z,Y) / cov(Z,X)
1
2
15
In my dept today we discussed deriving estimators from causal models. This can be opaque, but as a simple e.g. instrumental variable Z for estimating X on Y. Z –a–> X –b–> Y, and X <– U –> Y, where U is unmeasured, a and b are path coefs. We want to know b. How? >>
1
14
91
Do you find the way statistics relates to scientific questions confusing and arbitrary? Do you like drawing owls? Then my free lectures are here for you
For the new kids in back: If you hate statistics, you'll love my free lectures. Putting science before statistics, from basics of inference & causal modeling to multilevel models & dynamic state space models. It's all free, made with love and sympathy. https://t.co/GnOYGex9Yg
3
66
404

This is a good article and I agree with its argument for comprehensible research.
How can we reform science? I have some ideas. But I am not sure you’ll like them, because they don’t promise much.
0
8
23
I updated this post with links at bottom that go into more depth on mechanistic and philosophical reasons for troubles in science reform
How can we reform science? I have some ideas. But I am not sure you’ll like them, because they don’t promise much.
1
10
44

I haven't read this book, but the authors (Grant & Di Tanna) know their stuff, and they provide code for every script/engine. Meta- and mega-analysis one of those places where Bayes is natural and often easier than non-Bayes.

New book on Bayesian Meta-Analysis with Stan code: https://t.co/AtKhL0Nylf
4
53
309

Good morning from London, where we start Day 2 of the @royalsociety meeting "The Future of Scientific Publishing". Yesterday, we discussed the problems; today, we're going to solve them all! #FutureSciPub
9
24
183
For the morning EU crew
How can we reform science? I have some ideas. But I am not sure you’ll like them, because they don’t promise much.
0
2
19
How can we reform science? I have some ideas. But I am not sure you’ll like them, because they don’t promise much.

elevanth.org
What hope is there for science reform, if we can't agree on what to reform? Right now, principles are more important than practices.
5
62
190
everyone stop fighting and touch the fluffy belly (beware)
0
1
33
Every Mac knows what Rob Mac is going through

2
4
25
Here's a paper with a skeleton of the idea, but there is really lots of research to do on the structure of workflow networks, now to make them robust, how to development diagnostics and calculi for steps within them.
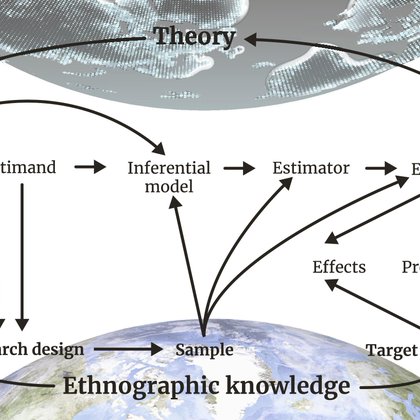
pnas.org
Cultural evolution applies evolutionary concepts and tools to explain the change of culture over time. Despite advances in both theoretical and emp...
1
5
35
When colleagues ask me what I'm working on now, I mutter about "scientific workflow". Good scientific projects are entangled networks of assumptions and models and measurements in which the logic of each connection is transparent and can be checked. Working on 2 books and an ERC.
3
5
152