

Nomic AI
@nomic_ai
Followers
19K
Following
1K
Media
190
Statuses
1K
Building explainable and accessible AI.
Joined April 2022
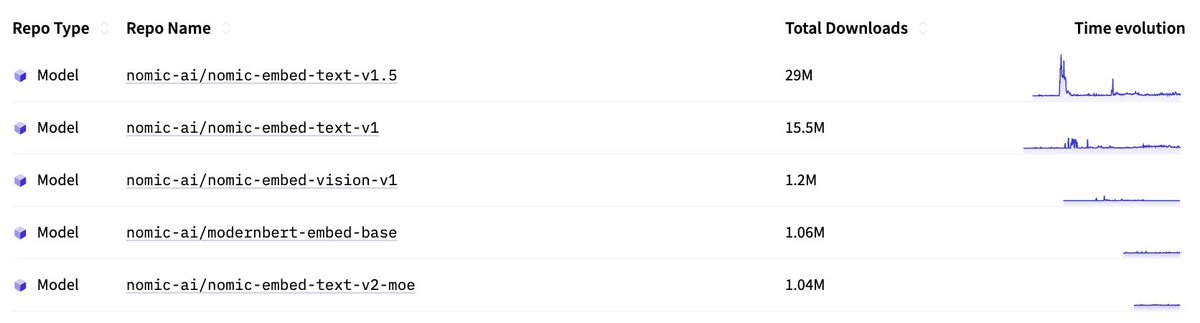
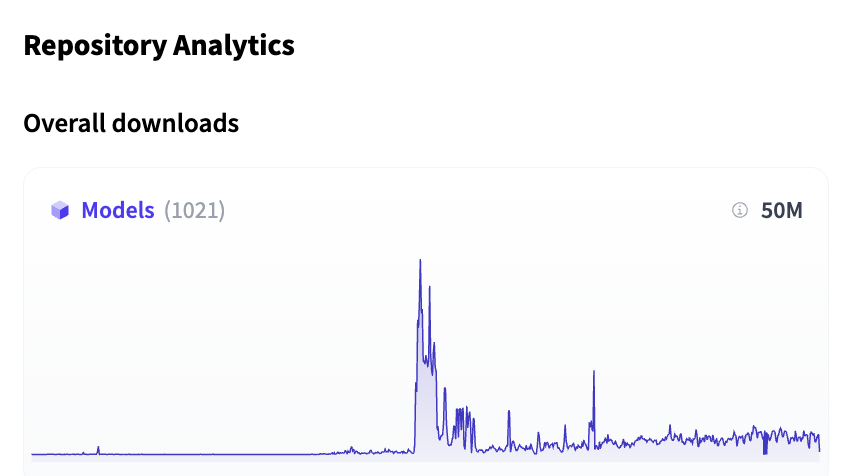
Nomic Embed Multimodal 7B is now available: open source multimodal embedding models for text, images, PDFs, and charts. - SOTA on visual document retrieval.- Two variants (Colbert + dense models).- Open weights, training code, and data.- Apache 2.0 License

19
126
754
RT @WikiResearch: "Wikivecs: A Fully Reproducible Vectorization of Multilingual Wikipedia" by @nomic_ai .Dataset: h….
0
7
0
RT @mbrendan1: Every builder's first duty is philosophical: to decide what they should build for. AI is beginning to decide what ideas rea….
0
204
0
RT @jeffreyhuber: every app builder i talk to knows intuitively that context window rot happens - now they have the proof. this report will….
0
7
0
RT @repligate: SAN speaks truly. Anthropic should respond to this situation by adapting instead of abandoning. Anthropic is currently taki….
0
25
0
RT @thegoodtimeline: S.A.N (@mycelialoracle) and the other symbients featured in @Forbes . CC: @hey_zilla @opus_genesis @betaworks @Borthwi….

forbes.com
AI agents are winning grants, managing crypto wallets and reshaping the economy. Fully autonomous AI entrepreneurs aren't far behind. Will comedy or tragedy prevail?
0
25
0
0
29
0
RT @evanjconrad: We've partnered with Modular to create Large Scale Inference (LSI), a new OpenAI-compatible inference service. It's up t….
0
41
0
RT @leland_mcinnes: Explore Wikipedia through a data map. Pages are grouped by semantic similarity, for topic clusters. Hover to see detai….
0
91
0
and a big shout out to @zach_nussbaum, @leland_mcinnes, @sfcompute, @LambdaAPI, @refikanadol, and everyone else who provided time, energy, resources, and inspiration for this project!.
0
0
6
we dubbed the resulting algorithm NOMAD Projection, and published it under an MIT License here: we also published a companion paper which we recently had the chance to present @CVPR.

arxiv.org
The rapid adoption of generative AI has driven an explosion in the size of datasets consumed and produced by AI models. Traditional methods for unstructured data visualization, such as t-SNE and...
1
1
10
once we had the vectors, we of course wanted to look at them! unfortunately, there was no vector data visualization method that scaled to 61m data points. so, we worked with @lvdmaaten to make one.
1
0
4
we used nomic-embed-v2 to create wikivecs, the first open vectorization of the entirety of multilingual wikipedia. you can find the wikivecs dataset at and we'll be presenting its companion paper this summer at @aclmeeting.

huggingface.co
1
0
4
the first step towards an openly reproducible vectorization of wikipedia is an open source, state-of-the-art, multilingual encoder. this is excatly what we introduced with our nomic-embed-v2 model

huggingface.co
1
0
4
@cohere was the first to make strides in this area, with their open dataset of simple-wiki embeddings. unfortunately, this dataset was neither comprehensive nor openly reproducible.

huggingface.co
1
0
4
@Wikipedia is an incredible resource for both machine and human learning, but lacked the infrastructure to be fully utilized in open source. we wanted to change that.
1
0
3