
Michael Günther
@michael_g_u
Followers
609
Following
269
Media
25
Statuses
287

Jina-VDR, our large visual document retrieval benchmark, is now supported by MTEB ✨📜.I’m excited to see more models evaluated on it soon. Leaderboard (Images > Jina Visual Document Retrieval):.🏆More info about the benchmark:.📚

1
2
6
We are at @qdrant_engine 's Vector Space Day 🚀 in Berlin on Sep 26. We'll talk about "Vision-Language Models: A New Architecture for Multi-Modal Embedding Models" and also share some insights and learnings we gained while training jina-embeddings-v4. 🎫

0
2
6
RT @JinaAI_: Got a Mac with an M-chip? You can now train Gemma3 270m locally as a multilingual embedding or reranker model using our mlx-re….
0
65
0
RT @JinaAI_: Two weeks ago, we released jina-embeddings-v4-GGUF with dynamic quantizations. During our experiments, we found interesting th….
0
25
0
I went together with @bo_wangbo to SIGIR this year, we wrote a blog post with our highlights and summaries of AI and neural papers that we found interesting at the conference.

jina.ai
Sharing what we saw and learned at SIGIR 2025, feat. CLIP-AdaM, RE-AdaptIR and evaluations for LLM-based retrieval systems.
0
1
10
RT @JinaAI_: Our official MCP server with read, search, embed, rerank tools on mcp[at]jina[at]ai, where we optimized the embedding and rera….
0
17
0
RT @tomaarsen: 😎 I just published Sentence Transformers v5.1.0, and it's a big one. 2x-3x speedups of SparseEncoder models via ONNX and/or….
0
15
0
Resolution is important for image embeddings - especially for visual document retrieval. jina-embeddings-v4 supports inputs up to 16+ MP (the default is much lower). We wrote a blog post about how resolution affects performance across benchmarks.

jina.ai
Image resolution is crucial for embedding visually rich documents. Too small and models miss key details; too large and they can't connect the parts.
0
2
11
RT @bo_wangbo: Finally, a 45 page literature review of text embedding model, datasets, evaluation and training methods: .

arxiv.org
Text embeddings have attracted growing interest due to their effectiveness across a wide range of natural language processing (NLP) tasks, such as retrieval, classification, clustering, bitext...
0
52
0
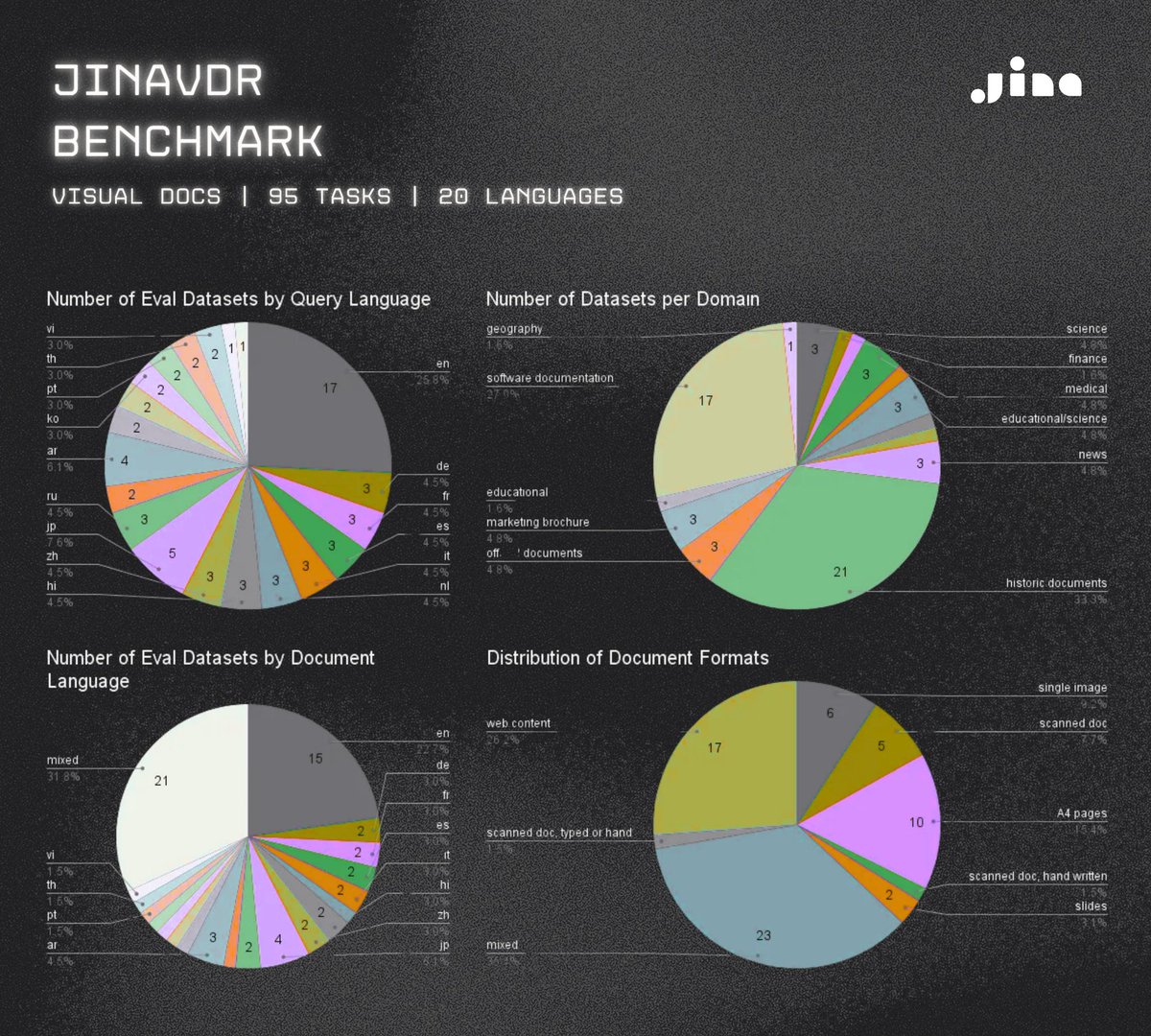
We created a new benchmark for visual document retrieval with diverse visually rich documents (more than linear paginated PDFs) and more query types than just questions.
github.com
Jina VDR is a multilingual, multi-domain benchmark for visual document retrieval - jina-ai/jina-vdr

New benchmark drops: JinaVDR (Visual Document Retrieval) evals how good retrieval models handle real-world visual documents on 95 tasks in 20 langs—think layouts packed with graphs, charts, tables, text, images. We're talking scanned docs, screenshots, the works. JinaVDR pairs
0
0
6
RT @felix1987_: vLLM is finally supporting our multi-modal reranker jina-reranker-m0 This is neat! .
0
2
0
RT @eliebakouch: We've just release 100+ intermediate checkpoints and our training logs from SmolLM3-3B training. We hope this can be use….
0
59
0
RT @JinaAI_: jina-embeddings-v4-GGUF is here with different quantizations Unsloth-like dynamic quants is on the way.

github.com
A collection of GGUF and quantizations for jina-embeddings-v4 - jina-ai/jina-embeddings-v4-gguf
0
23
0
RT @JinaAI_: Context engineering is curating the most relevant information to pack the context windows just right. Text selection and passa….
0
15
0
We just arrived @SIGIRConf! If you're here or are interested in an internship @JinaAI_ on training the following search foundation models, feel free to reach out to me:.- Embedding / Dense Retrieval Models.- Rerankers.- Small LMs (<2B) for document cleaning, extraction, etc.

0
4
33
Our paper "Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models" has been accepted at the Robust IR Workshop @ SIGIR 2025! 🌠. 📅 I'll present it on July 17th. 📝 Pre-print: 🔗 Workshop:

arxiv.org
Many use cases require retrieving smaller portions of text, and dense vector-based retrieval systems often perform better with shorter text segments, as the semantics are less likely to be...
5
18
130
RT @JinaAI_: Many know the importance of diverse query generation in DeepResearch, but few take its implementation seriously. Most DeepRese….
0
27
0
RT @jupyterjazz: I just integrated jina-embeddings-v4 with vLLM, and throughput doubled compared to inference via transformers (tested on F….
0
5
0
RT @tomaarsen: ‼️Sentence Transformers v5.0 is out! The biggest update yet introduces Sparse Embedding models, encode methods improvements,….
0
66
0