
Sander Land
@magikarp_tokens
Followers
1K
Following
381
Media
34
Statuses
149
Breaking all the models with weird tokens
ម្បី᥀$PostalCodesNL / Oslo
Joined March 2024
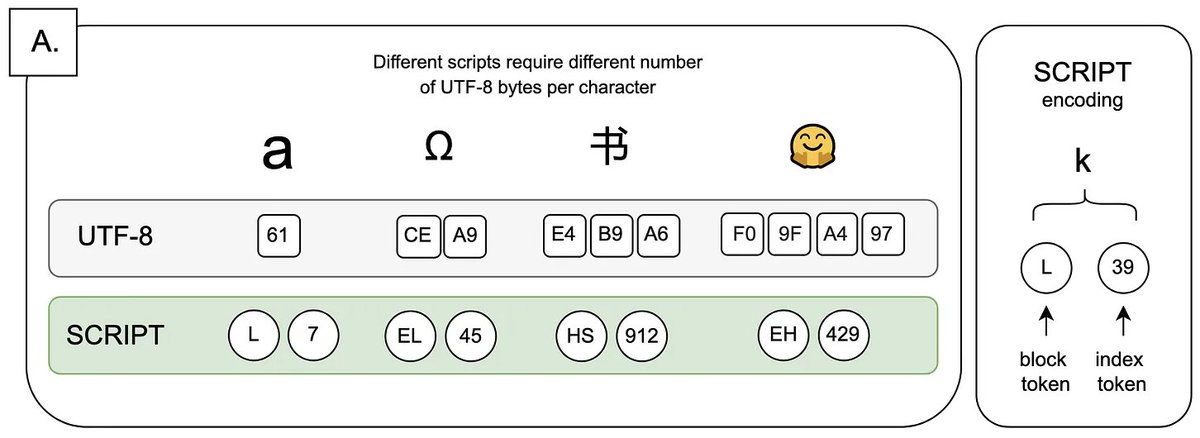
🔠 UTF-8 was never meant for language models. Yet every major tokenizer still uses it, creating unfair "byte premiums". Why should your native script cost more to tokenize? It's time for a change. 🧵👇

5
38
302
Had a fantastic time at the Tokenization workshop, and really grateful for the recognition of our work with a best paper award.

🏆 Announcing our Best Paper Awards!.🥇 Winner: "BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization" 🥈 Runner-up: "One-D-Piece: Image Tokenizer Meets Quality-Controllable Compression" .Congrats! 🎉

2
0
22
RT @AiEleuther: Congratulations to @linguist_cat and @magikarp_tokens on winning the best paper award at the #ICML2025 Tokenizer Workshop!….
0
8
0
RT @soldni: most controversial statement so far from @alisawuffles: "tokenization research is not as cool". **very vocals disagreements fro….
0
4
0
RT @Cohere_Labs: We’re excited to share that work from our @Cohere colleague @magikarp_tokens, “BPE Stays on SCRIPT: Structured Encoding fo….
0
9
0
RT @tokshop2025: 🎤 Meet our expert panelists! Join Albert Gu, Alisa Liu, Kris Cao, Sander Land, and Yuval Pinter as they discuss the Future….
0
10
0
SCRIPT-BPE coming to ICML next week!.

We’re excited to share that two recent works from @Cohere and Cohere Labs, will be published at workshops next week at @icmlconf in Vancouver! 🇨🇦. 🎉Congrats to all researchers with work presented! .@simon_ycl, @cliangyu_, Sara Ahmadian, @mziizm, @magikarp_tokens, @linguist_ca

0
4
29
Why do language models start by converting text to bytes? 🤔.UTF-8 solved a 1992 storage problem. LLMs have different needs. 🧵New post explaining how we can do better: Beyond Bytes ⮕. Fun fact: GPT-4o tokenizes that arrow as [b' \xe2', b'\xae', b'\x95\n\n'] 🤖💥
1
4
29
RT @AiEleuther: We are launching a new speaker series at EleutherAI, focused on promoting recent research by our team and community members….
0
25
0
RT @sarahookr: Huge congrats to all the authors @dianaabagyan, @alexrs95, @fffffelipec, @kroscoo, @learnlaughcry, @acyr_l, @mziizm, @ahmetu….

arxiv.org
Pretraining massively multilingual Large Language Models (LLMs) for many languages at once is challenging due to limited model capacity, scarce high-quality data, and compute constraints....
0
3
0
RT @saumyamalik44: Thank you to co-authors @natolambert, @valentina__py, @magikarp_tokens, @jacobcares, @nlpnoah, and @HannaHajishirzi for….

huggingface.co
0
3
0
RT @saumyamalik44: I’m thrilled to share RewardBench 2 📊— We created a new multi-domain reward model evaluation that is substantially harde….
0
50
0

RT @linguist_cat: Sander and I have been working on a new encoding scheme for tokenization which mitigates variable length byte sequences f….
0
4
0
5/ SCRIPT can also be used to eliminate complex regex pretokenization. 😵💫. Current tokenizers use giant regular expressions to break up text, and many of them have unexpected edge cases. SCRIPT gives you a simple alternative: split on points where the encoding block changes.
1
0
23
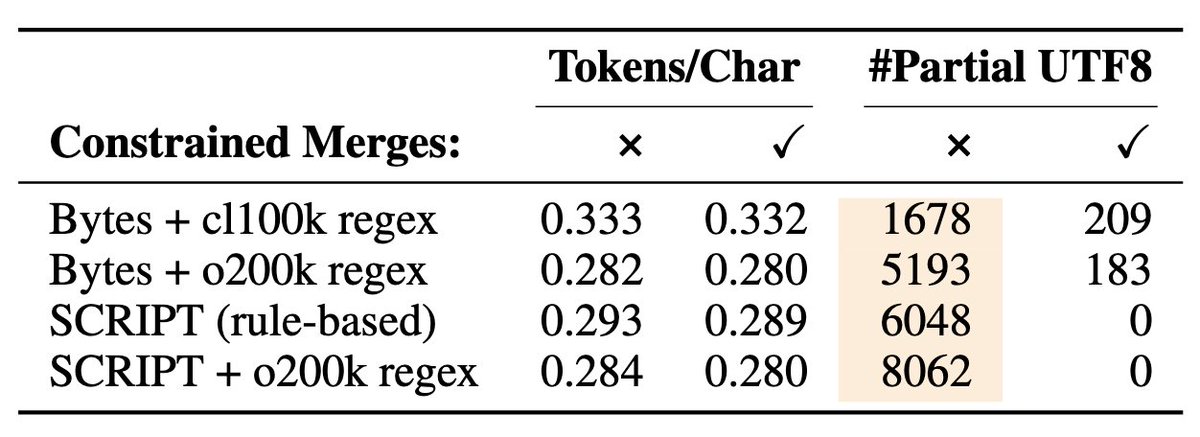
4/🚧 A simple character-boundary merge check respect prevents this 🚧 . 💯 Zero weird tokens, even in tricky scripts.🚀 Faster training with fewer pairs to track.🎯 No loss in quality, compression is even slightly better!
1
0
23
3/ We also show that a simple character-boundary check improves both regular Byte-based BPE and SCRIPT-BPE 🤯.BPE normally does not care about these by default, resulting in tokens which risk broken outputs. One bad cross-character merge can create a domino effect.

1
0
29
2/ Introducing SCRIPT: An encoding that treats all characters equally, designed for modern multilingual LLMs. Instead of bytes:.📦 Block token (e.g. Korean letters).🔢 Index token.SCRIPT-BPE then optimizes for the languages you care about, without a biased starting point.
1
1
43