
Felipe Cruz-Salinas
@fffffelipec
Followers
209
Following
2K
Media
8
Statuses
142
This is a good motto to work on AI these days (:.

AI does the boring work, you do the creative work.
1
0
5
We have a new Vision Model! Try it out :).

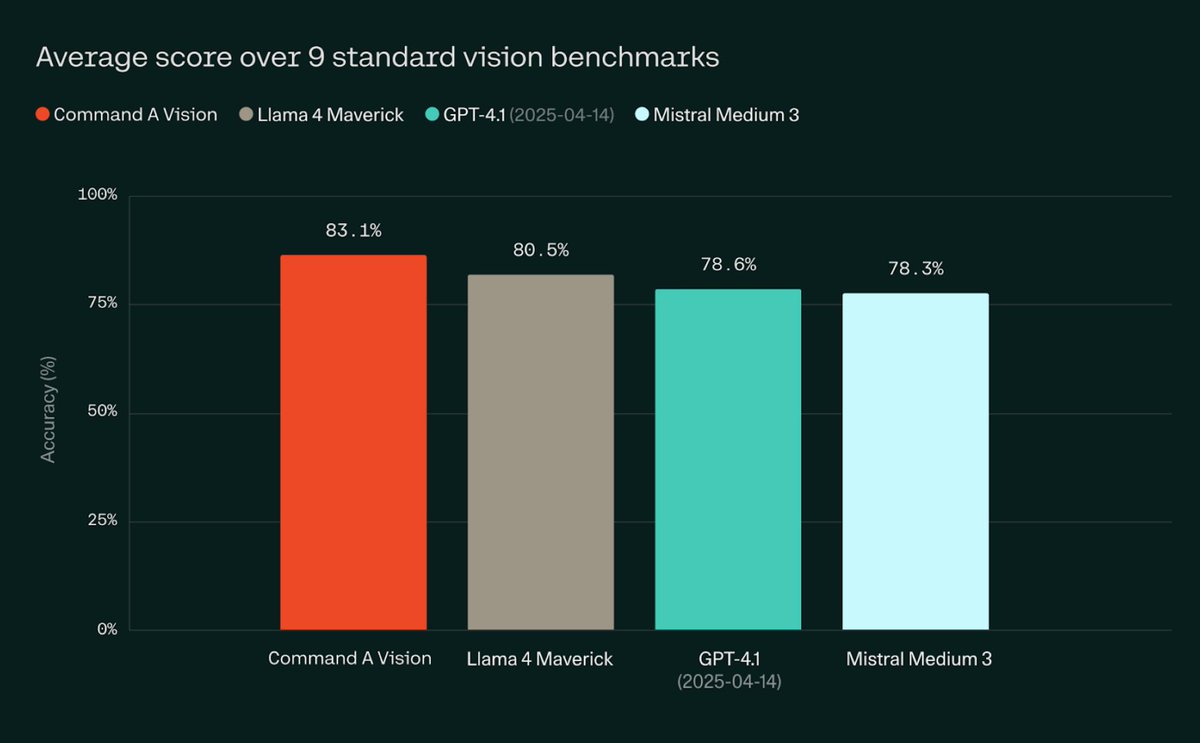
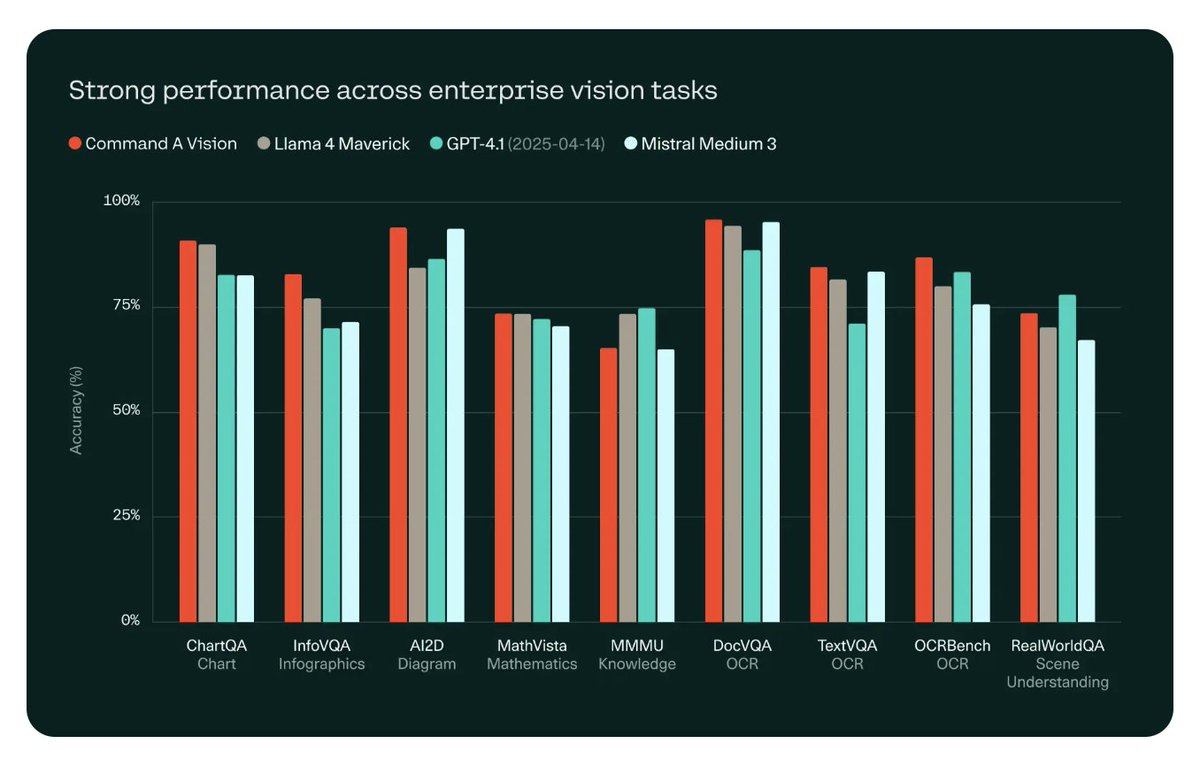
Excited to reveal what I've been working on for the last few months. Command-A-Vision is our new flagship 112B VLM that outperforms Llama 4 Maverick, Mistral Medium/Pixtral Large, GPT 4.1, and others. We release weights on HF and hope you'll like it.
0
0
17
RT @TheOneKloud: Excited to reveal what I've been working on for the last few months. Command-A-Vision is our new flagship 112B VLM that ou….
0
30
0
This is very cool. One of the reasons I think muP hasn't caught on is that it is not seamlessly integrated with torch. Optax can make some things annoying, but this one is nice :).

MUP has been on my mind forever!.Now I came across this gem from @JesseFarebro : It automatically handles it on JAX/Flax 😍. Just need to see what to adjust for Muon / Shampoo / PSGD-kron (init params + LR scaling).
0
0
7
RT @dianaabagyan: A huge thank you to all of my mentors and collaborators, especially @ahmetustun89, @sarahookr, @alexrs95, and @mziizm for….

arxiv.org
Pretraining massively multilingual Large Language Models (LLMs) for many languages at once is challenging due to limited model capacity, scarce high-quality data, and compute constraints....
0
6
0
RT @Cohere_Labs: How can we make language models more flexible to adapt to new languages after pretraining? 🌏. 🧠 Our latest work investigat….
0
19
0
RT @magikarp_tokens: 🔠 UTF-8 was never meant for language models. Yet every major tokenizer still uses it, creating unfair "byte premiums".….
0
41
0
Fun sonnet 4 hallucination on muP. The Yang-Lecun correspondence

0
0
4
RT @irombie: I'm excited to share our new pre-print.ShiQ: Bringing back Bellman to LLMs! .In this work, we propose….

arxiv.org
The fine-tuning of pre-trained large language models (LLMs) using reinforcement learning (RL) is generally formulated as direct policy optimization. This approach was naturally favored as it...
0
39
0
RT @mziizm: 1/ Science is only as strong as the benchmarks it relies on. So how fair—and scientifically rigorous—is today’s most widely us….
0
21
0
Up on arxiv! Now you can cite the largest model using muP (((: .

arxiv.org
In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and...
0
0
2
The Command A tech report is out, lots of really useful post-training details, and a couple interesting pre-training nuggets :)))).

We’re redefining what’s possible with AI. With the release of our latest model, Command A, optimized for real-world agentic and multilingual tasks, we’re demonstrating our commitment to bringing enterprises AI that goes beyond the ordinary, and offers security & efficiency.
1
1
12
RT @cohere: We’re redefining what’s possible with AI. With the release of our latest model, Command A, optimized for real-world agentic a….
0
23
0
RT @lmarena_ai: 🚀 Big news @cohere's latest Command A now climbs to #13 on Arena!. Another organization joining the top-15 club - congrats….
0
42
0