

Luca Schulze Buschoff
@lucaschubu
Followers
54
Following
28
Media
6
Statuses
15
Excited to see our Centaur project out in @Nature. TL;DR: Centaur is a computational model that predicts and simulates human behavior for any experiment described in natural language.

4
57
181
Excited to say our paper got accepted to ICML! We added new findings including this: models fine-tuned on a visual counterfactual reasoning task do not generalize to the underlying factual physical reasoning task, even with test images matched to the fine-tuning data set.

In previous work we found that VLMs fall short of human visual cognition. To make them better, we fine-tuned them on visual cognition tasks. We find that while this improves performance on the fine-tuning task, it does not lead to models that generalize to other related tasks:

1
3
5
Check out our pre-print here: https://t.co/eH8TiLLBN4. This is joint work with @KozzyVoudouris, @elifakata, @MatthiasBethge, Josh Tenenbaum, and @cpilab.

arxiv.org
Pre-trained vision language models still fall short of human visual cognition. In an effort to improve visual cognition and align models with human behavior, we introduce visual stimuli and human...
0
1
2
Finally, we fine-tuning a model on human responses for the synthetic intuitive physics dataset. We find that this model not only shows a higher agreement with human observers, but that it also generalizes better to the real block towers.

1
0
1
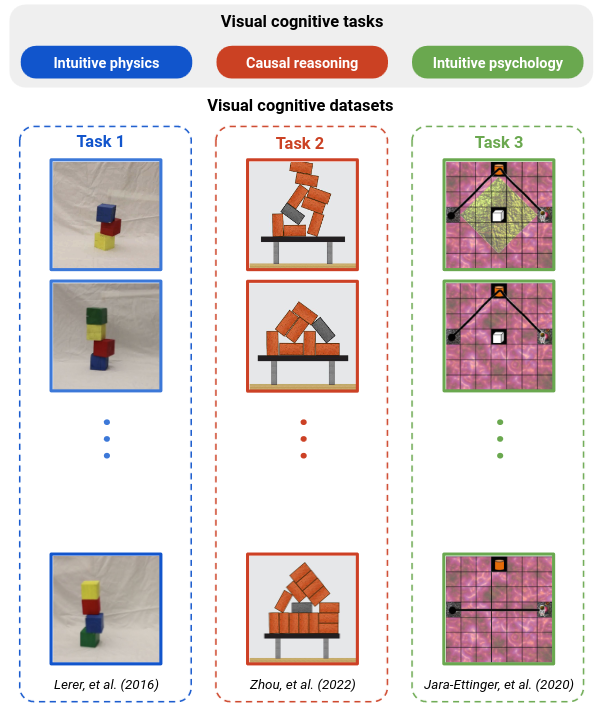
Models fine-tuned on intuitive physics also do not robustly generalize to an almost identical but visually different dataset (Lerer columns below). They are fine-tuned on synthetic block towers, while the dataset by @adamlerer features pictures of real block towers.

1
0
1
We fine-tuned models on tasks from intuitive physics and causal reasoning. Models fine-tuned on intuitive physics (first two rows) do not perform well on causal reasoning and vice versa. Models fine-tuned on both perform well in either domain, showing models can learn both.

1
0
1
In previous work we found that VLMs fall short of human visual cognition. To make them better, we fine-tuned them on visual cognition tasks. We find that while this improves performance on the fine-tuning task, it does not lead to models that generalize to other related tasks:
1
5
10
Happy to say we made the cover too! (@elifakata, @cpilab)

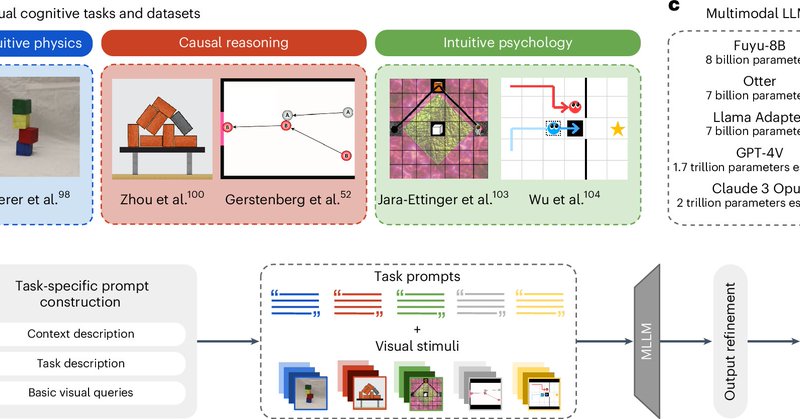
Our paper (with @elifakata, @MatthiasBethge, @cpilab) on visual cognition in multimodal large language models is now out in @NatMachIntell. We find that VLMs fall short of human capabilities in intuitive physics, causal reasoning, and intuitive psychology.
0
3
16
Our paper (with @elifakata, @MatthiasBethge, @cpilab) on visual cognition in multimodal large language models is now out in @NatMachIntell. We find that VLMs fall short of human capabilities in intuitive physics, causal reasoning, and intuitive psychology.
nature.com
Nature Machine Intelligence - Modern vision-based language models face challenges with complex physical interactions, causal reasoning and intuitive psychology. Schulze Buschoff and colleagues...
1
10
42
Excited to announce Centaur -- the first foundation model of human cognition. Centaur can predict and simulate human behavior in any experiment expressible in natural language. You can readily download the model from @huggingface and test it yourself:

huggingface.co
41
245
1K

Object slots are great for compositional generalization, but can models without these inductive biases learn compositional representations without supervision too? Yes! Unsupervised learning on object videos yields entangled, yet compositional latent codes for objects!
1
15
73
Come work with @can_demircann and me on semantic label smoothing (it's cool, I promise)!

We currently have several openings for Bachelor and Master students. Topics range from mostly experimental to mostly computational, and everything in between. Please reach out if you are interested. Physical presence in Munich is required. More details:
0
2
5

🚨Pre-print alert:🚨 Have we built machines that think like people? In new work, led by @lucaschubu and @elifakata and together with @MatthiasBethge, we assess multi-modal #LLMs reasoning abilities in three core domains: intuitive physics, causality, and intuitive psychology.
5
35
143