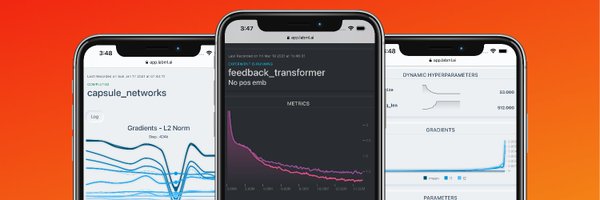

labml.ai
@labmlai
Followers
13K
Following
604
Media
204
Statuses
654
📝 Annotated paper implementations https://t.co/qeO4UTbrJ3
Joined December 2020
You can now download the Notbad v1.0 Mistral 24B model from @huggingface
https://t.co/O0XjmIPojq Try it on

chat.labml.ai
NotBadAI models generate shorter, cleaner reasoning outputs through self-improved capabilities, independently developed without distillation from other models.
0
2
13

As an ML engineer, implementation >>>>everything. Knowing is theory. Implementation is understanding. Few outstanding topics it has: 1. Reinforcement Learning - ppo, dqn 2. Transformer - classical to Retro, switch, gpt models 3. Diffusion models - stable, DDPM, DDIM, UNET 4.
16
58
612
We've open-sourced our internal AI coding IDE. We built this IDE to help with coding and to experiment with custom AI workflows. It's based on a flexible extension system, making it easy to develop, test, and tweak new ideas quickly. Each extension is a Python script that runs
2
5
11
GEPA appears to be an effective method for enhancing LLM performance, requiring significantly fewer rollouts than reinforcement learning (RL). It maintains a pool of system prompts. It uses an the LLM to improve them by reflecting on the generated answers and the scores/feedback
2
4
17
Wrote an annotated Triton implementation of Flash Attention 2. (Links in reply) This is based on the flash attention implementation by the Triton team. Changed it to support GQA and cleaned up a little bit. Check it out to read the code for forward and backward passes along
3
9
48
Added the JAX transformer model to annotated paper implementations project. https://t.co/PBFbvaeVY3 Link 👇

Coded a transformer model in JAX from scratch. This was my first time with JAX so it might have mistakes. https://t.co/J0AE8RH7zn This doesn't using any high-level frameworks such as Flax. 🧵👇
1
4
24
The new training also improved GPQA from 64.2% to 67.3% and MMLU Pro from 64.2% to 67.3%. This model was also trained with the same reasoning datasets we used to train the v1.0 model. We mixed more general instruction data with answers sampled from the

We are releasing an updated reasoning model with improvements on IFEval scores (77.9%) than our previous model (only 51.4%). 👇 Links to try the model and to download weights below
1
6
7
We are releasing an updated reasoning model with improvements on IFEval scores (77.9%) than our previous model (only 51.4%). 👇 Links to try the model and to download weights below
1
6
10
We just released a Python coding reasoning dataset with 200k samples on @huggingface This was generated by our RL-based self-improved Mistral 24B 2501 model. This dataset was used to train train Notbad v1.0 Mistral 24B. 🤗 Links in replies 👇
2
7
19
Uploaded the dataset of 270k math reasoning samples that we used to finetune Notbad v1.0 Mistral 24B (MATH-500=77.52% GSM8k Platinum=97.55%) to @huggingface (link in reply) Follow @notbadai for updates
9
13
62
We're open-sourcing a math reasoning dataset with 270k samples, generated by our RL-based self-improved Mistral 24B 2501 model and used to train Notbad v1.0 Mistral 24B. Available on Hugging Face:

huggingface.co
0
4
9
📢 We are excited to announce Notbad v1.0 Mistral 24B, a new reasoning model trained in math and Python coding. This model is built upon the @MistralAI Small 24B 2501 and has been further trained with reinforcement learning on math and coding.
1
8
23
Try it on
chat.labml.ai
NotBadAI models generate shorter, cleaner reasoning outputs through self-improved capabilities, independently developed without distillation from other models.
📢 We are excited to announce Notbad v1.0 Mistral 24B, a new reasoning model trained in math and Python coding. This model is built upon the @MistralAI Small 24B 2501 and has been further trained with reinforcement learning on math and coding.
0
0
6

Now Our visualization library Inspectus can visualize values related to tokens in LLM outputs. This demo shows some outputs from using entropyx (by @_xjdr) on Llama 3. Had fun making this. (jk I didn’t) 🔗👇
0
0
6
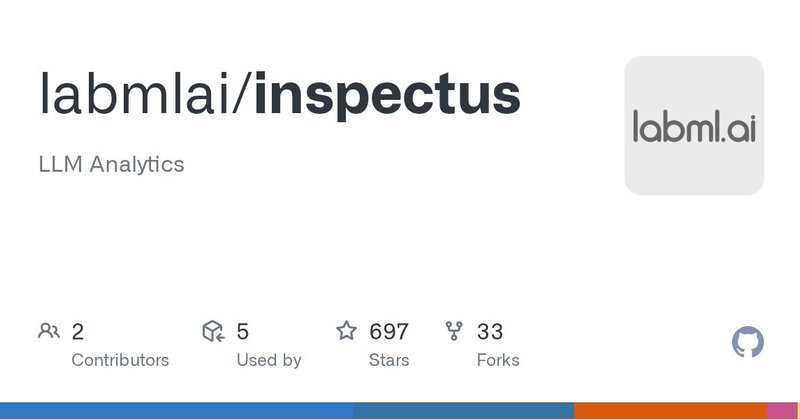
We added token visualization to Inspectus. It lets you visualize metrics associated with tokens such as loss, entropy, KL div, etc. It works on notebooks and pretty easy to use. 👇 https://t.co/uWLPkorrtN
1
4
27
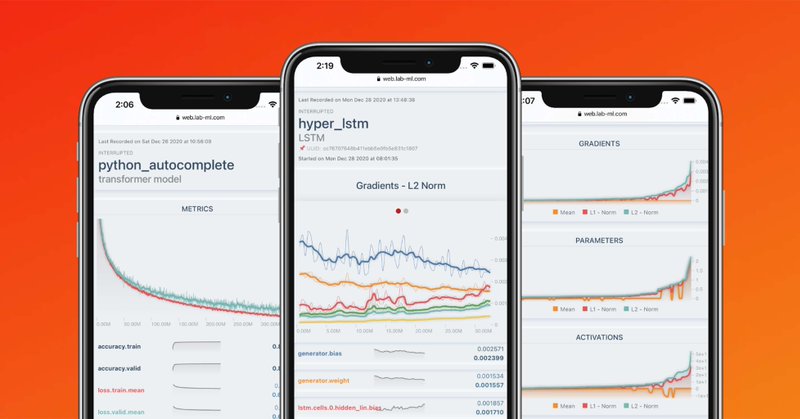
Our open source deep learning experiment monitoring library now has 2000 stars! Thank you
1
3
18