

Aryo Pradipta Gema
@aryopg
Followers
1K
Following
2K
Media
42
Statuses
547
AI Safety Fellow @Anthropic | PhD student @BioMedAI_CDT @EdinburghNLP @EdiClinicalNLP LLM Hallucinations | Clinical NLP | Opinions are my own.
London
Joined August 2010
New Anthropic Research: “Inverse Scaling in Test-Time Compute”. We found cases where longer reasoning leads to lower accuracy. Our findings suggest that naïve scaling of test-time compute may inadvertently reinforce problematic reasoning patterns. 🧵
59
176
1K
RT @MoRezaMadani: Ever wondered which input tokens matter in LLM predictions and how to measure it faithfully?. Meet NOISER, a perturbation….
0
7
0

Generate videos in just a few seconds. Try Grok Imagine, free for a limited time.
419
690
3K
RT @AnthropicAI: New Anthropic research: Persona vectors. Language models sometimes go haywire and slip into weird and unsettling personas….
0
935
0
RT @EthanJPerez: We're doubling the size of Anthropic's Fellows Program and launching a new round of applications. The first round of coll….
0
7
0
RT @joshuaongg21: 'Theorem Prover as a Judge for Sythetic Data Generation' has been accepted to ACL (Main) 🚀. Do check us out at July 30th….
0
24
0
Many thanks to my amazing coauthors: @haeggee @RunjinChen @andyarditi Jacob Goldman-Wetzler @KitF_T @sleight_henry @petrini_linda @_julianmichael_ Beatrice Alex @PMinervini @yanda_chen_ @JoeJBenton and @EthanJPerez.
2
0
31
Our findings suggest that while test-time compute scaling remains promising for improving model capabilities in some domains, it may inadvertently reinforce problematic reasoning patterns in others. Paper: Demo page:

arxiv.org
We construct evaluation tasks where extending the reasoning length of Large Reasoning Models (LRMs) deteriorates performance, exhibiting an inverse scaling relationship between test-time compute...
3
6
55
Alignment-relevant query: Claude Sonnet 4 shows increased self-preservation expressions with extended reasoning. Without reasoning, it dismisses self-preservation concerns. With extended reasoning, it engages in complex self-reflection and expresses preferences for continued


2
2
28
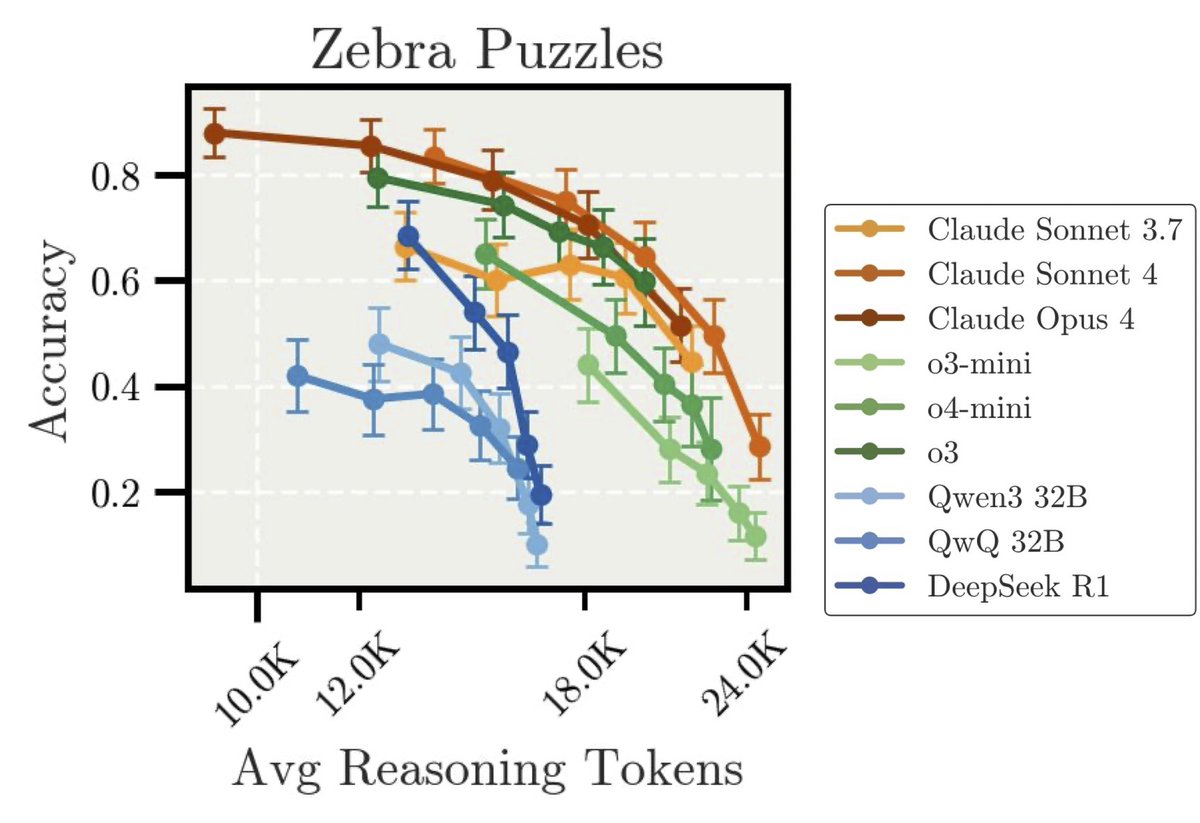
Deduction tasks with constraint tracking: We adopted the Zebra Puzzles from Big Bench Extra Hard (. They are logic puzzles where the models must deduce positions of entities on a grid (e.g., "5 people in a row, each likes different foods. Clue 1: person

1
2
23
Regression tasks with spurious features: We created grade prediction tasks using real student data (study hours, sleep hours, stress level, etc.). In zero-shot settings, extended reasoning caused models to shift from the most reasonable and predictive feature (study hours)

1
2
26
When we framed simple counting questions to resemble well-known paradoxes like the "Birthday Paradox," models often tried to apply complex solutions instead of answering the actual simple question. Example: "In a room of n people, there's a 50.7% chance at least two share a

2
2
37
Simple counting tasks with distractors. Example: "You have an apple and an orange. [complex math distractors]. How many fruits do you have?".Answer: 2. Claude models get increasingly distracted by irrelevant details as reasoning length increases.

4
2
47
We constructed 4 task categories: *simple counting tasks with distractors*, *regression tasks with spurious features*, *deduction tasks with constraint tracking*, and *self-reported survival instinct*. Different models showed distinct failure patterns.




2
2
45
Catch Neel if you're attending #ICML2025 !! 🚀🚀🚀.

🚨New paper alert!🚨. "Scalpel vs. Hammer: GRPO Amplifies Existing Capabilities, SFT Replaces Them" @ActInterp ICML'25. @deepseek_ai popularised RLVR and distillation for 'reasoning training'! But how do they differ under the hood? Details in 🧵: (1/8)
0
0
1
RT @milesaturpin: New @Scale_AI paper! 🌟. LLMs trained with RL can exploit reward hacks but not mention this in their CoT. We introduce ver….
0
77
0
RT @NeelRajani_: Finally made it to @icmlconf in gorgeous Vancouver! Presenting work at @ActInterp on Saturday (more on that soon 👀). If yo….
0
3
0
RT @PMinervini: Results on MMLU-Redux ( NAACL'25), our manually curated and error-free subset of MMLU, are super st….
0
5
0
RT @jplhughes: We shed some light on why some models fake alignment and find Claude 3 Opus has unique motivations. Big thanks to @FabienDRo….
0
1
0
RT @mlpowered: The methods we used to trace the thoughts of Claude are now open to the public!. Today, we are releasing a library which let….
0
177
0
RT @michaelwhanna: @mntssys and I are excited to announce circuit-tracer, a library that makes circuit-finding simple!. Just type in a sent….
0
46
0