

Fenil Doshi
@fenildoshi009
Followers
574
Following
1K
Media
19
Statuses
432
PhD student @Harvard and @KempnerInst studying biological and machine vision | object perception | mid-level vision | cortical organization
Cambridge, MA
Joined June 2017
🧵 What if two images have the same local parts but represent different global shapes purely through part arrangement? Humans can spot the difference instantly! The question is can vision models do the same? . 1/15
5
114
594
RT @Guangxuan_Xiao: I've written the full story of Attention Sinks — a technical deep-dive into how the mechanism was developed and how our….
0
258
0

Generate videos in just a few seconds. Try Grok Imagine, free for a limited time.
23
16
176
RT @talboger: Looking at Van Gogh’s Starry Night, we see not only its content (a French village beneath a night sky) but also its *style*.….
0
15
0
RT @AndrewLampinen: In neuroscience, we often try to understand systems by analyzing their representations — using tools like regression or….
0
59
0
RT @mlpowered: Earlier this year, we showed a method to interpret the intermediate steps a model takes to produce an answer. But we were m….
0
55
0
RT @Jack_W_Lindsey: Attention is all you need - but how does it work? In our new paper, we take a big step towards understanding it. We dev….
0
192
0
RT @YungSungChuang: Scaling CLIP on English-only data is outdated now…. 🌍We built CLIP data curation pipeline for 300+ languages.🇬🇧We train….
0
79
0
RT @yingtian80536: 🧠 NEW PREPRINT .Many-Two-One: Diverse Representations Across Visual Pathways Emerge from A Single Objective. https://t.co….

biorxiv.org
How the human brain supports diverse behaviours has been debated for decades. The canonical view divides visual processing into distinct "what" and "where/how" streams – however, their origin and...
0
22
0
RT @Napoolar: Chatted with Le Monde about interpretability and sparse autoencoders. (Yes, SAE made it into mainstream news 😅) . https://t.….

lemonde.fr
Les rouages des robots conversationnels demeurent très opaques, mais des chercheurs commencent à localiser les « neurones » qui stockent les informations et prennent des décisions-clés.
0
9
0
RT @ruilong_li: For everyone interested in precise 📷camera control 📷 in transformers [e.g., video / world model etc]. Stop settling for Plü….
0
80
0
RT @Rahul_Venkatesh: AI models segment scenes based on how things appear, but babies segment based on what moves together. We utilize a vis….
0
13
0
RT @aran_nayebi: 🚀 New Open-Source Release! PyTorchTNN 🚀. A PyTorch package for building biologically-plausible temporal neural networks (T….
0
38
0
RT @mihirp98: 🚨 The era of infinite internet data is ending, So we ask:. 👉 What’s the right generative modelling objective when data—not co….
0
182
0
RT @t_andy_keller: Why do video models handle motion so poorly? It might be lack of motion equivariance. Very excited to introduce: Flow E….
0
73
0
RT @KempnerInst: New in the #DeeperLearningBlog: #KempnerInstitute research fellow @t_andy_keller introduces the first flow equivariant neu….
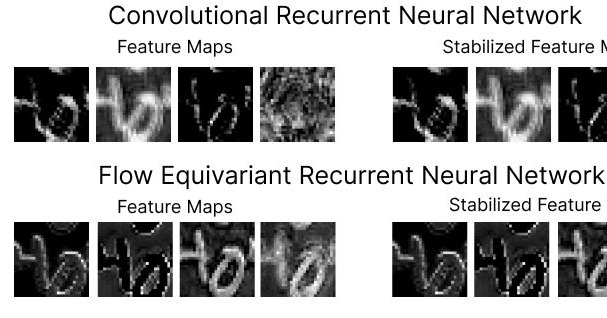
kempnerinstitute.harvard.edu
Sequence transformations, like visual motion, dominate the world around us, but are poorly handled by current models. We introduce the first flow equivariant models that respect these motion symmet...
0
4
0
RT @AndrewLampinen: Quick thread on the recent IMO results and the relationship between symbol manipulation, reasoning, and intelligence in….
0
85
0
RT @Napoolar: Great excuse to share something I really love: .1-Lipschitz nets. They give clean theory, certs for robustness, the right lo….
0
53
0
RT @demishassabis: Official results are in - Gemini achieved gold-medal level in the International Mathematical Olympiad! 🏆 An advanced ver….

deepmind.google
Our advanced model officially achieved a gold-medal level performance on problems from the International Mathematical Olympiad (IMO), the world’s most prestigious competition for young...
0
762
0
RT @shawshank_v: Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G….
0
56
0
RT @SeKim1112: We prompt a generative video model to extract state-of-the-art optical flow, using zero labels and no fine-tuning. Our metho….
0
8
0
RT @tpimentelms: Mechanistic interpretability often relies on *interventions* to study how DNNs work. Are these interventions enough to gua….
0
28
0