
Kelly Buchanan
@ekellbuch
Followers
1K
Following
20K
Media
5
Statuses
680
Reliable AI. Postdoctoral Fellow @Stanford working with @HazyResearch and @Scott_linderman. PhD from @Columbia @ZuckermanBrain. Industry: @GoogleAI.
Palo Alto, CA
Joined July 2011
LLMs can generate 100 answers, but which one is right? Check out our latest work closing the generation-verification gap by aggregating weak verifiers and distilling them into a compact 400M model. If this direction is exciting to you, we’d love to connect.

How can we close the generation-verification gap when LLMs produce correct answers but fail to select them? .🧵 Introducing Weaver: a framework that combines multiple weak verifiers (reward models + LM judges) to achieve o3-mini-level accuracy with much cheaper non-reasoning

1
16
51
RT @ZeyuanAllenZhu: 🚀 NVIDIA continues to lead on open-sourcing pretraining data — Nemotron-CC-v2 has dropped! .👏 Congrats to @KarimiRabeeh….
0
81
0
RT @sirbayes: I just finished reading this interesting book by @druv_pai, @_sdbuchanan and colleagues. It's fairly "heavy" but provides a v….
0
91
0
RT @jacobaustin132: Today we're putting out an update to the JAX TPU book, this time on GPUs. How do GPUs work, especially compared to TPUs….
0
535
0
RT @jiawzhao: Introducing DeepConf: Deep Think with Confidence. 🚀 First method to achieve 99.9% on AIME 2025 with open-source models! Using….
0
331
0
RT @YiMaTweets: Our latest book on the mathematical principles of deep learning and intelligence has been released publicly at: https://t.c….
0
272
0
RT @stuart_sul: MoE layers can be really slow. When training our coding models @cursor_ai, they ate up 27–53% of training time. So we comp….
0
98
0
RT @pratyushmaini: 1/Pretraining is hitting a data wall; scaling raw web data alone leads to diminishing returns. Today @datologyai shares….
0
125
0
RT @paulg: The Trump administration has suspended the funding of Terence Tao and the Institute for Pure and Applied Mathematics at UCLA. ht….
0
1K
0
RT @brenthyi: July has been a big month for Viser!.- Released v1.0.0😊.- We did some writing. Some demos👇
0
101
0
RT @mihirp98: We ran more experiments to better understand “why” diffusion models do better in data-constrained settings than autoregressiv….
0
61
0
RT @mihirp98: We ran more experiments, with random token masking, and attention dropout in autoregressive training. Consistent with our ear….
0
17
0
RT @ren_hongyu: Check out the latest open models. Absolutely no competitor of the same scale. Towards intelligence too cheap to meter. http….
0
16
0
RT @GoogleDeepMind: What if you could not only watch a generated video, but explore it too? 🌐. Genie 3 is our groundbreaking world model th….
0
3K
0
RT @sama: someday soon something smarter than the smartest person you know will be running on a device in your pocket, helping you with wha….
0
3K
0
RT @ClementDelangue: Every tech company can and should train their own deepseek R1, Llama or GPT5, just like every tech company writes thei….
0
280
0
RT @SnorkelAI: New from Snorkel AI: Weaver combines weak verifiers to boost LLM output quality: no fine-tuning needed. ⚡ +14.5% accuracy.⚡….
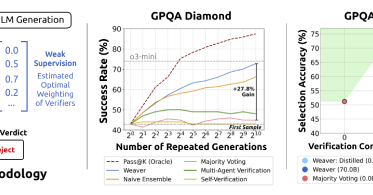
snorkel.ai
Verifiers can enhance language model (LM) performance by scoring and ranking a set of generated responses, but high-quality verifiers today are either unscalable (like human judges) or of limited...
0
3
0

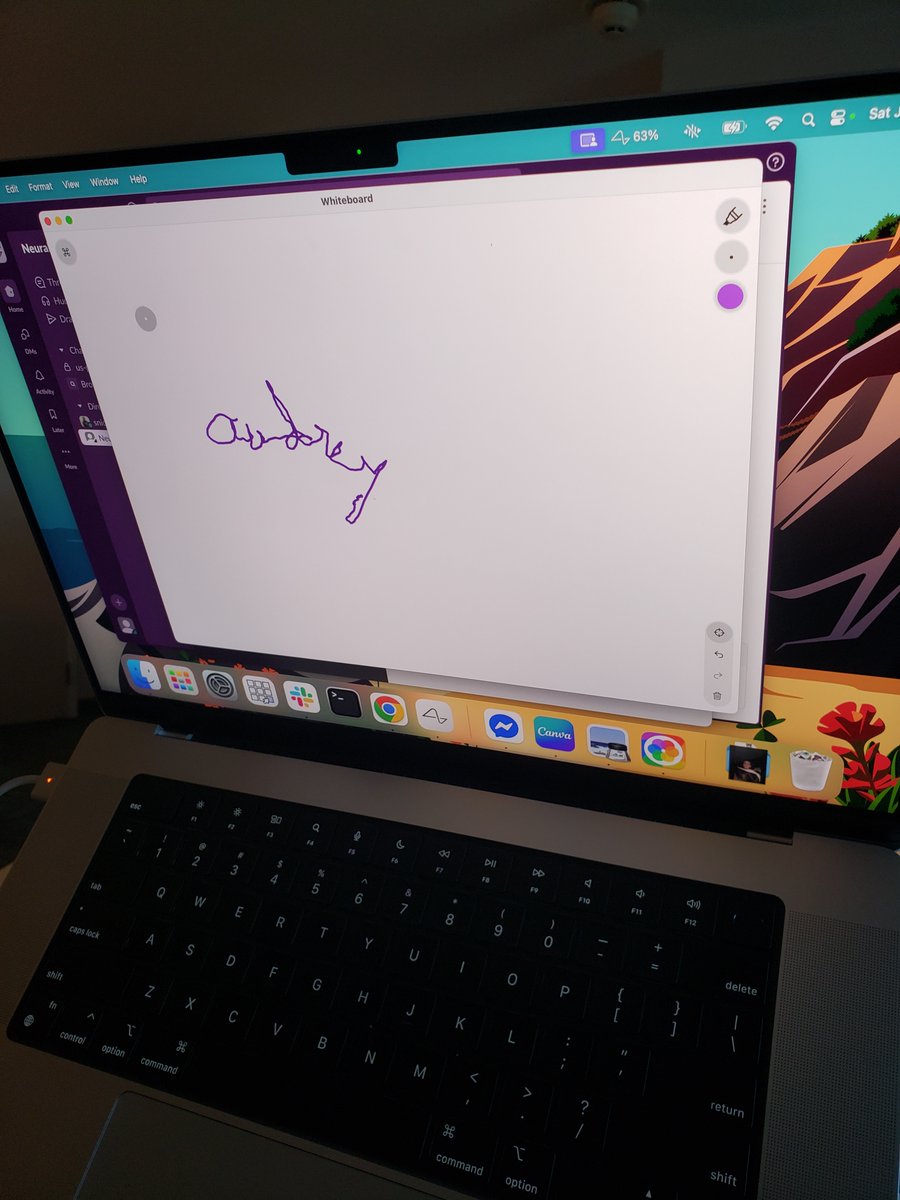
RT @NeuraNova9: I tried writing my name for the first time in 20 years. Im working on it. Lol #Neuralink
0
3K
0
RT @3blue1brown: New video on the details of diffusion models: Produced by @welchlabs, this is the first in a smal….
0
407
0
RT @ChujieZheng: Proud to introduce Group Sequence Policy Optimization (GSPO), our stable, efficient, and performant RL algorithm that powe….
0
247
0