
Sam Buchanan
@_sdbuchanan
Followers
1K
Following
3K
Media
30
Statuses
301
Postdoc @Berkeley_EECS, previously @TTIC_Connect, PhD @EE_ColumbiaSEAS. Representation learning, theory and practice
Bay Area, CA
Joined March 2015
At CVPR this week for our tutorial (tomorrow; all day; on low-dim models and their ubiquity in deep learning for vision. Come by throughout the day to hear more, and let me know if you'd like to meet up!.
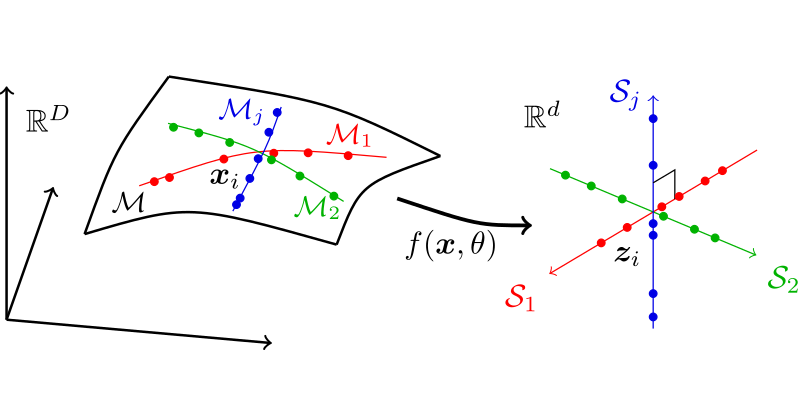
cvpr2024-tutorial-low-dim-models.github.io
'Website for CVPR 2024 Tutorial "Learning Deep Low-Dimensional Models from High-Dimensional Data: From Theory to Practice"'
0
8
99
GPT-5 seems pretty good for math in my limited testing so far 🤔 One-shotted a tricky differential geometry computation a bit beyond my expertise. Anyone else have similar experiences so far?.
1
0
8

Turn old photos into videos and see friends and family come to life. Try Grok Imagine, free for a limited time.
733
1K
5K
RT @realDanFu: What a throwback to weak supervision! Great work @JonSaadFalcon @ekellbuch @MayeeChen!.
0
8
0
RT @ekellbuch: LLMs can generate 100 answers, but which one is right? Check out our latest work closing the generation-verification gap by….
0
16
0
RT @yisongyue: One of my PhD students got their visa revoked. I know of other cases amongst my AI colleagues. This is not what investing….
0
168
0
RT @andrewhowens: In case you were wondering what’s going on with the back of the #CVPR2024 T-shirt: it’s a hybrid image made by @invernopa….
0
53
0
RT @YiMaTweets: If you want to know the newest understanding about deep networks from the perspective of learning low-dim structures, pleas….
cvpr2024-tutorial-low-dim-models.github.io
'Website for CVPR 2024 Tutorial "Learning Deep Low-Dimensional Models from High-Dimensional Data: From Theory to Practice"'
0
58
0
RT @fang_zhenghan: Presenting at #ICLR2024 with Sam Buchanan @_sdbuchanan and Jere Sulam @Jere_je_je!. We present neural networks that exac….
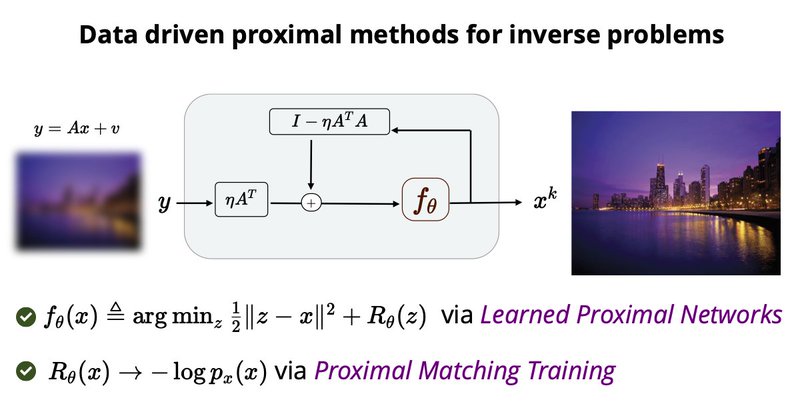
zhenghanfang.github.io
Learned proximal networks (LPN) are deep neural networks that exactly parameterize proximal operators. When trained with our proposed proximal matching loss, they learn expressive and interpretable...
0
8
0
RT @druv_pai: At ICLR this week! Excited to present our work, which presents a transformer-like autoencoder architecture which is performan….
0
8
0
Work done with the outstanding @fang_zhenghan and @Jere_je_je at JHU! Check out Jere's tweet thread and our project page (linked in Zhenghan's tweet) for more details!.

Paper 🚨 @iclr_conf! Proximal operators are ubiquitous in optimization, and thus in ML, signal+image processing. How can you learn deep nets that *exactly* parametrize proximal maps for data driven functions? and how can you use them to solve inverse problems? work with awesome.
0
0
3
Deep denoisers have become ubiquitous backbones for data-driven inverse problem solvers. But these networks are black-box -- what priors do they learn, how can we visualize them, and do the resulting algorithms converge?. Check out our poster at #ICLR2024 for a new solution!.

Presenting at #ICLR2024 with Sam Buchanan @_sdbuchanan and Jere Sulam @Jere_je_je!. We present neural networks that exactly parameterize prox operators and a new loss for learning the prox of an unknown prior!. 🔗📍Halle B #102.⏰Fri 10 May 10:45-12:45.
2
1
22
Interested in alternatives to purely black-box deep networks for unsupervised learning? Come check out Druv's work at ICLR this Thursday! . Project page: (scroll to bottom!).
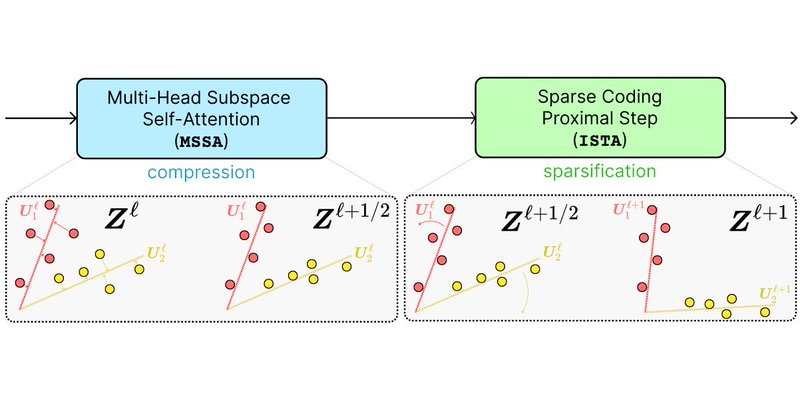
ma-lab-berkeley.github.io
CRATE is a transformer-like architecture which is constructed through first principles and has competitive performance on standard tasks while also enjoying many side benefits.

At ICLR this week! Excited to present our work, which presents a transformer-like autoencoder architecture which is performant, scalable, and interpretable, based on the framework of white-box deep networks. 🔗 ⏰ May 9, 10:45-12:45.📍 Halle B #39. 1/14

0
1
10
This work by @Song__Mei on foundations and statistical benefits of unrolled networks is opening tons of exciting research directions in this area. I believe soon we'll see proofs of algorithmic advantages (e.g. for CRATE!) as well, matching practice! Happy to see CRATE mentioned!.
1
6
23
One more post from Seoul -- rented a bike and rode most of the Han River Trail today. Absolutely incredible public resource -- has to be better than any such thing we have in the US (?), and can likely go pound-for-pound with urban trails around Europe too (??)



0
0
14
Very much enjoyed a visit and talk at Prof. Jong Chul Ye's group at KAIST today! Beautiful campus and very interesting research.


2
0
18

Traveling to Seoul tomorrow for our tutorial about white-box deep networks on Sunday. Hope to see you there!
0
1
11
In beautiful Nagoya at TTI! Gave a seminar yesterday about white-box transformers to a great audience of students and faculty. Thanks to Prof. Ukita and Prof. Sasaki for hosting me!

3
2
24
RT @Song__Mei: My group at Berkeley Stats and EECS has a postdoc opening in the theoretical (e.g., scaling laws, watermark) and empirical a….
0
23
0
Passing along in case you (also) hadn't seen it, or not for a while at least -- there are beautiful words about the spirit of analysis in here: "fine cuisine", about ". strength and sharpness of attack with simple, powerful tools" :-).

Fields medalist Cédric Villani explains some of John Nash's most amazing theorems.
0
0
5