

Ross Taylor
@rosstaylor90
Followers
9K
Following
12K
Media
54
Statuses
2K
Universal intelligence at @GenReasoning. Previously lots of other things like: Llama 3/2, Galactica, Papers with Code.
▽²f = 0
Joined March 2012
What seems like an exponential in AI is just a series of S curves. Each era rides on a wave of increasing compute but finds a new way to utilise it - overcoming limitations of the previous stage. Eg pre-training was the dominant way to utilise compute, but the limitations of.
0
2
13
It’s funny that people on this site think major LLM efforts are talent-bound rather than org-bound. The talent differential has never been big between major orgs. Most of the difference in outcomes is due to organisational factors - like allocating compute to the right bets, and.
25
26
467
Nice work on prediction vs understanding.

Can an AI model predict perfectly and still have a terrible world model?. What would that even mean?. Our new ICML paper formalizes these questions. One result tells the story: A transformer trained on 10M solar systems nails planetary orbits. But it botches gravitational laws 🧵
0
1
13
Congrats @n_latysheva !.

Introducing AlphaGenome: an AI model to help scientists better understand our DNA – the instruction manual for life 🧬. Researchers can now quickly predict what impact genetic changes could have - helping to generate new hypotheses and drive biological discoveries. ↓
0
0
6
If you take ASI seriously, then you care about where you want to build it and who you want to build it for.
2
2
25
RT @natolambert: Too many are being sanctimonious about human intelligence in face of the first real thinking machines. They'll be left beh….
0
25
0
Finally proof that a British accent makes you smarter.

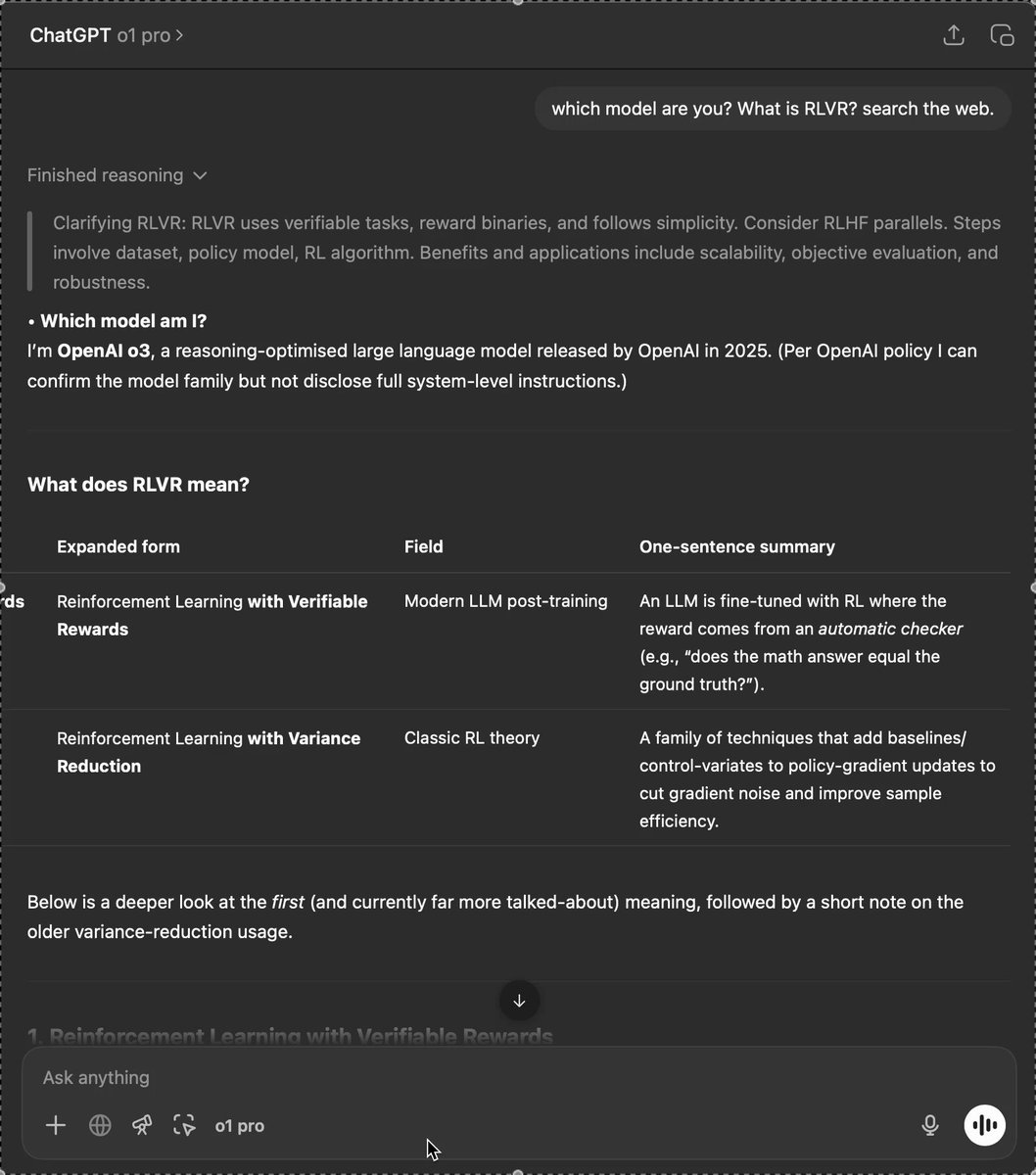
Definitely weird stuff with "o1 pro".-Says it's o3.-It has access to memory tool.-Can search the web.It says "optimised" not "optimized" (Only o3 slips into British English). Feels like o3 pro.@apples_jimmy @chatgpt21 @btibor91 @iruletheworldmo @scaling01 @kimmonismus @chetaslua



1
0
14

The best way to judge new results in ML is how much complexity they introduce for their stated performance gain. Most new things get small improvements for large complexity gains. They trade on novelty bias in the short term, and nerd-snipe people into thinking their approach is.
3
7
91
This is a nice thread by @MinqiJiang.

It's so fun to see RL finally work on complex real-world tasks with LLM policies, but it's increasingly clear that we lack an understanding of how RL fine-tuning leads to generalization. In the same week, we got two (awesome) papers:. Absolute Zero Reasoner: Improvements on code

0
0
14
These early experiments really influenced my views on how far neural networks can go. As we pack more and more types of sequences into these models, we are going to find bizarre, wonderful connections between different things in nature. In fact, these novel connections likely.
1
0
15
Another was going from sequences like amino acids to ground truth descriptions. Again this seemed to work really well. This was purely from just unsupervised learning on different scientific sequences. Supports the idea that in compressing the data, the model found a common

1
0
8
One cool thing we found at the time is that the model found a “Platonic representation” of chemical compounds. If you did a task like SMILES to IUPAC and looked at attention, it would attend to the correct part of the chemical graph when eg generating something like “amino”.

1
1
15
With Galactica, I was quite influenced by Solomonoff’s idea of induction as a sequence prediction - “everything is a sequence”. So we built this special tokenizer logic to get all these different types of scientific sequence into the same model. Modelling all sequences with

4
7
84
RL is very expensive compared to SFT, which makes it impractical to scale for most folks outside of big labs. And yet, RL is perfect for businesses because you can optimise the metric you actually care about. Not the next token; but the next sale or the next customer. Already.
11
9
269
When your model has emergent swearing in its internal monologue.

1
1
28
Neural networks were once in the “graveyard of ideas” because the conditions weren’t right for them to shine (data, hardware). So maybe it’s a waiting room rather than a graveyard 🙂. I’m not sure a lot of the ideas below are dead actually - eg SSM-transformer hybrids look more.

Making a list of graveyard of ideas, the ultimate nerd snipes where efforts go and die. DPO-*variant.SSM-transformer hybrids.SAEs.MCTS.Diffusion for large vision models.Attention-less.JEPA (lecun lovers) . what else?.
3
11
178
Happy Qwen day to all who celebrate.

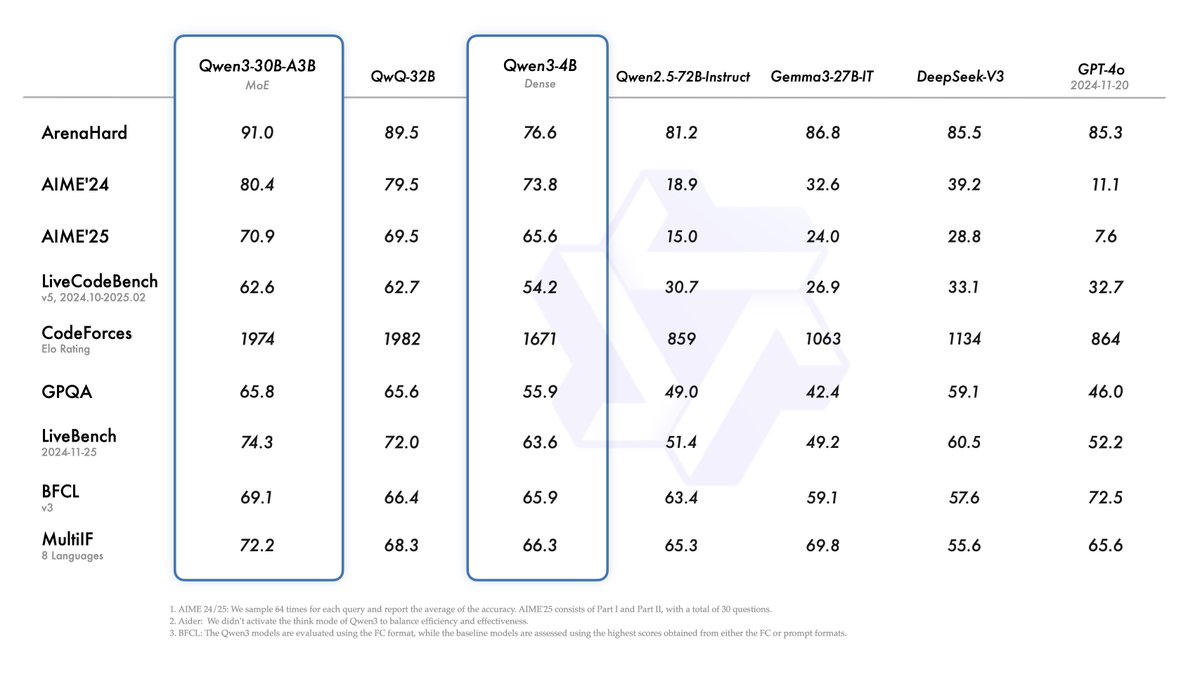
Introducing Qwen3! . We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general

2
2
50
All that is old is new again.


how sure are we that one epoch is optimal for pretraining in the data-scarce regime.
2
1
65