
David D. Baek
@dbaek__
Followers
2K
Following
107
Media
17
Statuses
39
PhD Student @ MIT EECS / Mechanistic Interpretability, Scalable Oversight
Joined February 2024
1/9 🚨 New Paper Alert: Cross-Entropy Loss is NOT What You Need! 🚨.We introduce harmonic loss as alternative to the standard CE loss for training neural networks and LLMs! Harmonic loss achieves 🛠️significantly better interpretability, ⚡faster convergence, and ⏳less grokking!
77
539
4K
1/6 New paper! “The Geometry of Concepts: Sparse Autoencoder Feature Structure.” We find that the concept universe of SAE features has interesting structure at three levels: 1) “atomic” small-scale, 2) “brain” intermediate-scale, and 3) “galaxy” large-scale!

21
187
977
9/9 This is a joint work with @ZimingLiu11, @riyatyagi86, and @tegmark! Check out the full paper and code here:.paper: code:
17
21
297
2/9 Instead of using inner-product and Softmax, harmonic loss leverages (a) Euclidean distance to compute the logit, and (b) scale-invariant HarMax function to obtain the probablity. This unlocks (1) nonlinear separability, (2) fast convergence, and (3) interpretability!
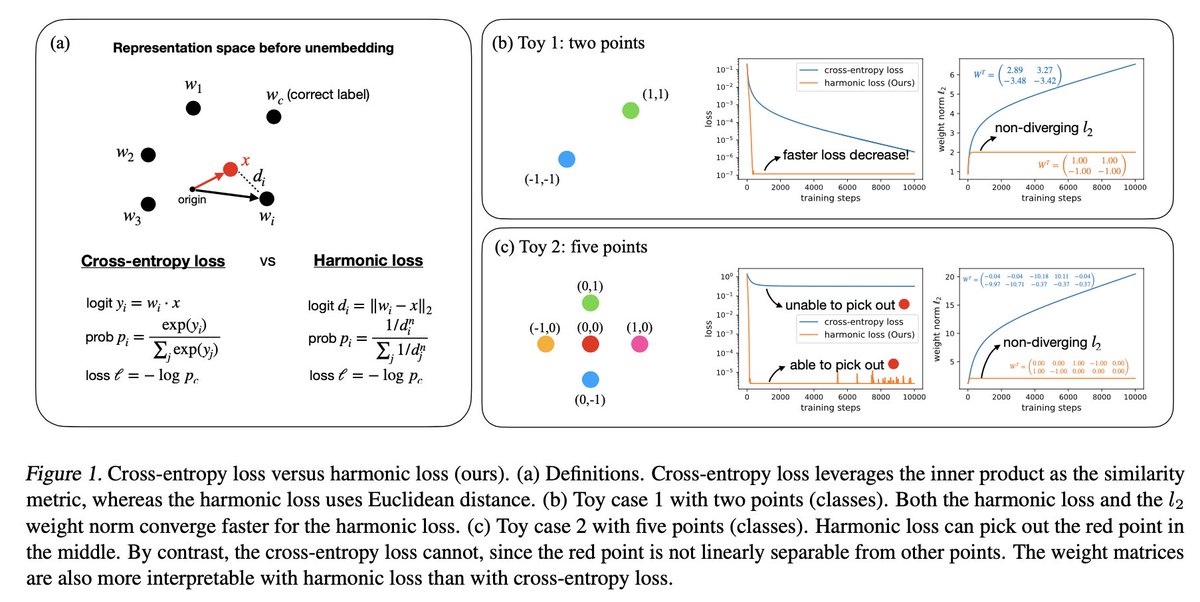
7
15
281
4/9 We validate our proposal on a wide range of algorithmic datasets! Harmonic models do indeed learn PERFECT lattice, circle, tree, and other structures regardless of the random seeds!

2
8
197
7/9 When we train GPT-2 with harmonic loss, we observe that models tend to represent semantically related word pairs (e.g. man:woman::king:queen), in a more rectangular parallelogram structure -- Harmonic loss produces high-precision function vectors!

2
7
192
6/9 On MNIST dataset, we find that harmonic loss makes the model weights highly interpretable, which are images representing each number! Moreover, most peripheral pixels have weights that are almost exactly zero, in contrast to the model trained with CE loss.
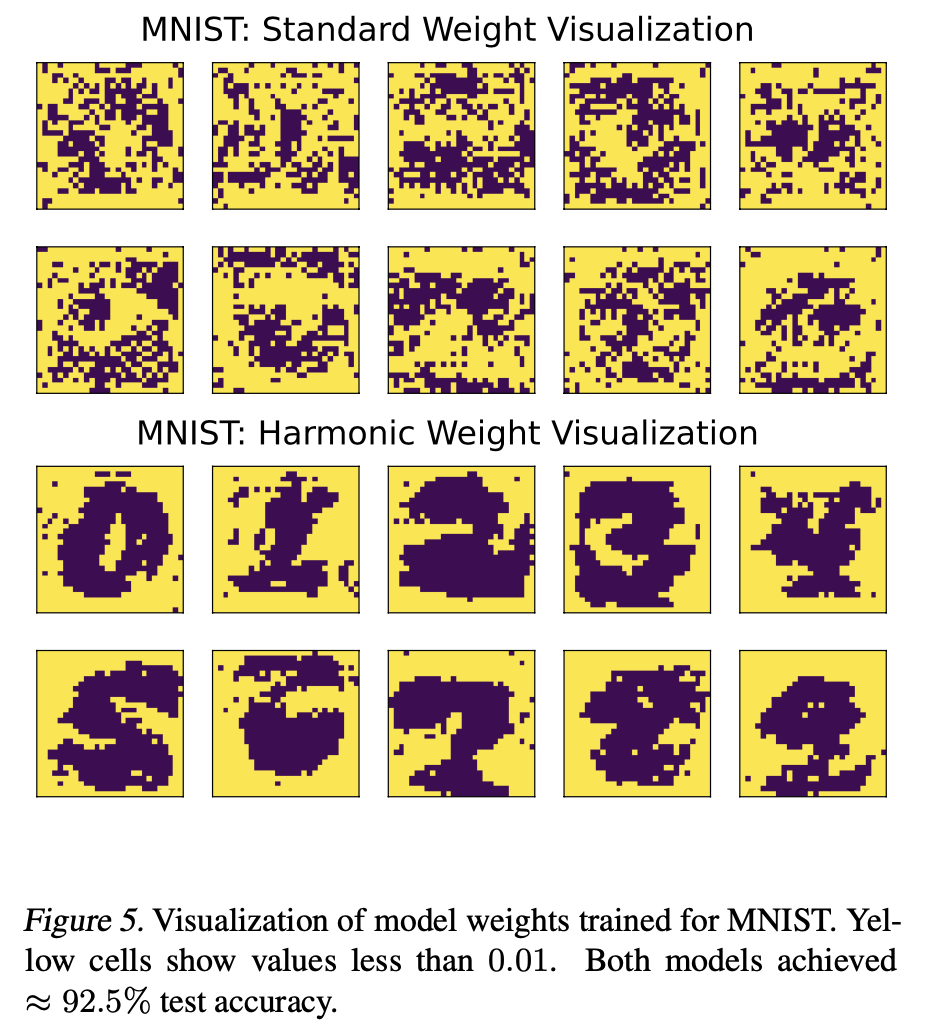
3
6
189
3/9 As an illustration, standard MLP trained for modular addition (a) needs strong weight decay to generalize, (b) groks severely, and (c) forms imperfect circle. In contrast, harmonic model generalizes quickly without grokking, and forms a perfect 2D circle.
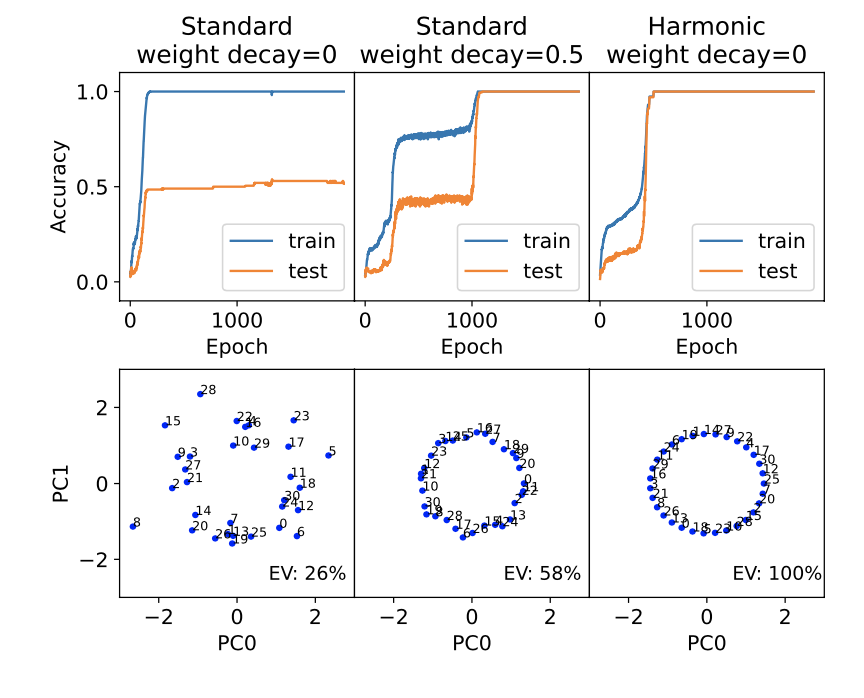
2
2
177
8/9 Looking forward, we believe harmonic loss will be an important ingredient to building AI models that are interpretable by design! We're excited to see works that apply harmonic loss to training even larger models and test its effectiveness!.
2
3
165
5/9 Our experiment on algorithmic datasets also verifies that harmonic loss achieves better data efficiency and less grokking!

1
1
120
6/6 This is a joint work with @ericjmichaud_ , @YuxiaoLi @JoshAEngels , @LilySun, and @tegmark. For more details, check out the full paper!
4
14
89
2/6 The “atomic” scale structure contains “crystals” whose faces are parallelograms or trapezoids, similar to the classic (man:woman::king:queen). The quality of crystals improves when projecting out global distractor directions such as word length (via linear discriminant

5
10
81
1/N 🚨Excited to share our new paper: Scaling Laws For Scalable Oversight! For the first time, we develop a theoretical framework for optimizing multi-level scalable oversight! We also make quantitative predictions for oversight success probability based on oversight simulations!
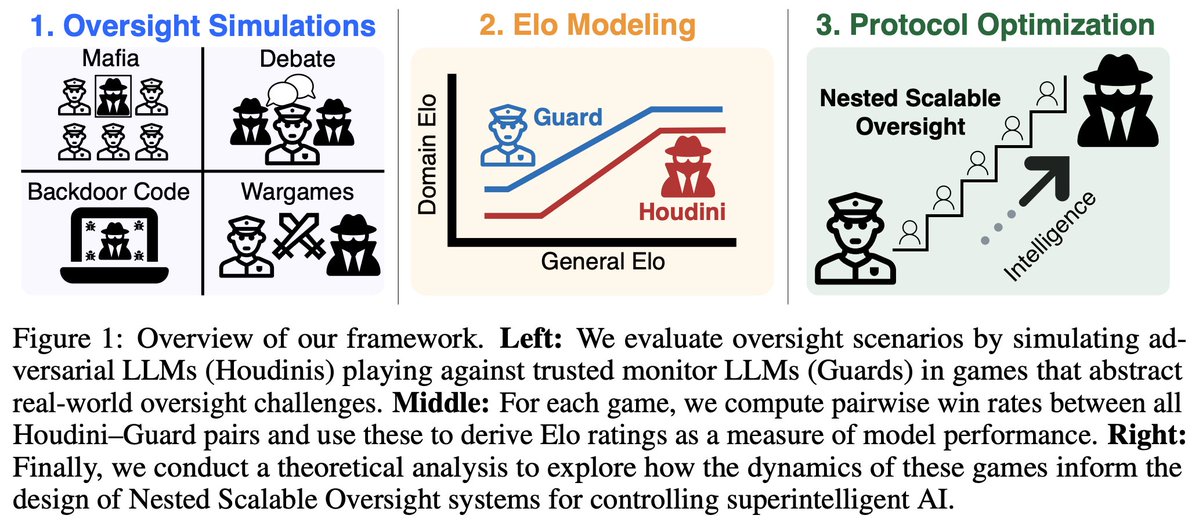
1
9
75
3/6 The “brain” intermediate-scale structure has significant spatial modularity, which we measure as alignment between spatial and co-occurrence clusters; for example, math and code features form a “lobe” akin to functional lobes seen in neural fMRI images.

1
7
60
4/6 The “galaxy” large-scale structure is not isotropic, but instead has a power law of eigenvalues with the steepest slope in the middle layers. Clustering entropy also peaks around the middle layers!

1
7
50
5/6 This work expands on recent works finding structures in SAEs, and we are excited to dive deeper in future works to understand why some of these structures emerge!.
1
4
34
8/N This is a joint work with @JoshAEngels, @thesubhashk, and @tegmark! Check out the links below for more details!. Paper: Code: Lesswrong:
2
0
9
2/N Model: Improvement in a model’s general intelligence often yields different returns for its performance as a Guard (overseer) and a Houdini (adversary) – and both can saturate. We model such "Domain Elos" as piecewise-linear Double ReLU functions of general Elo.

1
0
7
7/N We hope our work sparks more follow-up studies on optimizing real-world oversight protocols and rigorously measuring and estimating their failure rates!.
1
0
6
4/N Theoretical Framework: We study nested scalable oversight (NSO), where trusted weak AIs are used to align untrusted stronger AIs, which are then used to align even stronger AIs – recursively. It’s like a Matryoshka doll of oversight, each layer trapping the next!

1
0
7
5/N Numerical Simulations: We run numerical simulations of our theory to calculate the probability of oversight success and optimal number of overseers. Nested Scalable Oversight is often better than a single step of oversight!

1
0
6
3/N Oversight Simulations: We simulate four oversight games–Mafia, Debate, Backdoor Code, Wargames–with 15 LLMs distributed across a broad intelligence spectrum. We find that slopes and intercepts of the Guard and Houdini Domain Elo curves vary significantly from game to game.

1
0
5
6/N Quantitative Predictions: We also plug in the empirical slope/intercept estimates of Elo curves to make quantitative predictions about oversight success rate in the real world! Our predictions range from 9.8% (Wargames) to 51.4% (Debate) at 400-point general Elo difference.

1
0
4