

Hans-Peter Zorn
@data_hpz
Followers
10K
Following
10K
Media
91
Statuses
4K

How do LLMs pick the next word? They don’t choose words directly: they only output word probabilities. 📊 Greedy decoding, top-k, top-p, min-p are methods that turn these probabilities into actual text. In this video, we break down each method and show how the same model can

1
8
38

@growing_daniel unlike claude code, junior devs learn from their mistakes instead of having to be corrected for the same things over and over and over again until the sun burns out
8
4
334

"A stylish woman in a beige coat walking confidently past a moving train at a modern train station." Create images and videos in seconds with Grok Imagine.
831
718
5K

Can an AI model predict perfectly and still have a terrible world model? What would that even mean? Our new ICML paper formalizes these questions One result tells the story: A transformer trained on 10M solar systems nails planetary orbits. But it botches gravitational laws 🧵
211
1K
7K

Thanks for sharing! 🙂Here another abstract for the visual people. 😀



1
10
72

This is really BAD news of LLM's coding skill. ☹️ The best Frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel. LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI (“International

100
315
2K
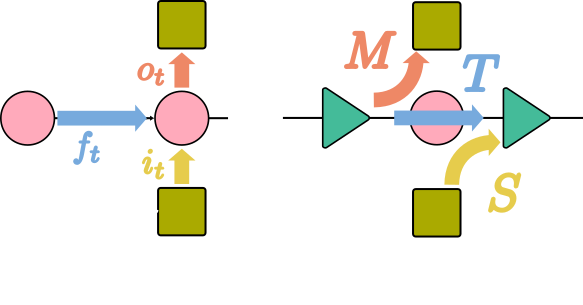
Ever wondered how linear RNNs like #mLSTM (#xLSTM) or #Mamba can be extended to multiple dimensions? Check out "pLSTM: parallelizable Linear Source Transition Mark networks". #pLSTM works on sequences, images, (directed acyclic) graphs. Paper link: https://t.co/nU7626uHWK
4
40
138

After ~6 years of building these types of architectures (starting with BERT, eg see Baleen), I think calling these multi-agent systems is a distraction. This is just software. Happens to be AI software. It doesn’t seem so complicated once you internalize it’s just a program.


New on the Anthropic Engineering blog: how we built Claude’s research capabilities using multiple agents working in parallel. We share what worked, what didn't, and the engineering challenges along the way. https://t.co/k3Gzd4HkLg
41
124
1K

Bro how was the show Silicon Valley so consistently 10 years ahead of its time 🤣
195
2K
28K




The data science revolution is getting closer. TabPFN v2 is published in Nature: https://t.co/Ybb15pnZ5P On tabular classification with up to 10k data points & 500 features, in 2.8s TabPFN on average outperforms all other methods, even when tuning them for up to 4 hours🧵1/19

36
252
1K

I don't think people really appreciate how simple ARC-AGI-1 was, and what solving it really means. It was designed as the simplest, most basic assessment of fluid intelligence possible. Failure to pass signifies a near-total inability to adapt or problem-solve in unfamiliar
68
141
1K

47
708
4K

Making a video with @plazmapunk is fun. I never know what I will get to see until the video is generated. Music made with @mytracksy
4
1
10

𝐁𝐌𝟒𝟐 - 𝐓𝐡𝐞 𝐌𝐢𝐬𝐬𝐢𝐧𝐠 𝐁𝐞𝐧𝐜𝐡𝐦𝐚𝐫𝐤 Qdrant released this week an interesting new approach that claims to replace BM25/lexical search. They just sadly forgot to do proper benchmarking. As it turns out: BM42 is way worse than BM25.


Hey all! We actually did find a discrepancy with our previous benchmarks of bm42. Please don't trust us and always check performance on your own data. Our best effort to correct it is here: https://t.co/dLW7UWBPYo

13
64
376

the delorean is a conference room THE DELOREAN IS A CONFERENCE ROOM
9
8
120
We are excited to share now the code for xLSTM! 🚀 Happy to hear about your first experiments with it! 🧪 https://t.co/FC3hEz8kFZ

github.com
Official repository of the xLSTM. Contribute to NX-AI/xlstm development by creating an account on GitHub.
0
19
104
9 out of 10 RAG applications would be better off by establishing a simple baseline before introducing text embeddings.

9
20
287

🔬🎙️ User Research and Interactive #recsys with @McWillemsen from @jadatascience Episode #21 of #recsperts is out! We discuss how users exert control over #recommendations, decision #psychology and user-centric evaluation - go check it out: https://t.co/Rmq0xyZcq0

0
4
8

0
1
3